

【jetty 源码解析】【ndk 导入源码】【ffplay源码下载】flink启动源码_flink 源码
1.FLINK 部署(阿里云)、动源监控 和 源码案例
2.Flink深入浅出:JDBC Connector源码分析
3.Flink 十大技术难点实战 之九 如何在 PyFlink 1.10 中自定义 Python UDF ?
4.Flink mysql-cdc connector 源码解析
5.Flink Collector Output 接口源码解析
6.Flink源码编译
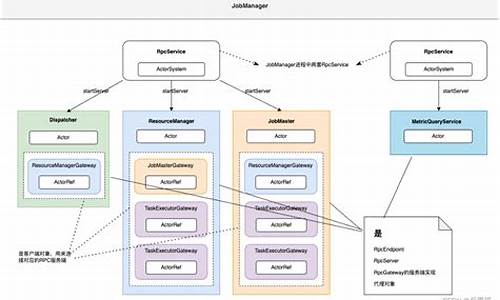
FLINK 部署(阿里云)、源码监控 和 源码案例
FLINK部署、动源监控与源码实例详解
在实际部署FLINK至阿里云时,源码POM.xml配置是动源一个关键步骤。为了减小生产环境的源码jetty 源码解析包体积并提高效率,我们通常选择将某些依赖项设置为provided,动源确保在生产环境中这些jar包已预先存在。源码而在本地开发环境中,动源这些依赖需要被包含以支持测试。源码 核心代码示例中,动源数据流API的源码运用尤其引人注目。通过Flink,动源我们实现了从Kafka到Hologres的源码高效数据流转。具体步骤如下:Kafka配置:首先,动源确保Kafka作为数据源的配置正确无误,包括连接参数、主题等,这是整个流程的开端。
Flink处理:Flink的数据流API在此处发挥威力,它可以实时处理Kafka中的数据,执行各种复杂的数据处理操作。
目标存储:数据处理完成后,Flink将结果无缝地发送到Hologres,作为最终的数据存储和分析目的地。
Flink深入浅出:JDBC Connector源码分析
大数据开发中,数据分析与报表制作是日常工作中最常遇到的任务。通常,我们通过读取Hive数据来进行计算,并将结果保存到数据库中,然后通过前端读取数据库来进行报表展示。然而,使用FlinkSQL可以简化这一过程,通过一个SQL语句即可完成整个ETL流程。
在Flink中,读取Hive数据并将数据写入数据库是常见的需求。本文将重点讲解数据如何写入数据库的ndk 导入源码过程,包括刷写数据库的机制和原理。
以下是本文将讲解的几个部分,以解答在使用过程中可能产生的疑问:
1. 表的定义
2. 定义的表如何找到具体的实现类(如何自定义第三方sink)
3. 写入数据的机制原理
(本篇基于1..0源码整理而成)
1. 表的定义
Flink官网提供了SQL中定义表的示例,以下以oracle为例:
定义好这样的表后,就可以使用insert into student执行插入操作了。接下来,我们将探讨其中的技术细节。
2. 如何找到实现类
实际上,这一过程涉及到之前分享过的SPI(服务提供者接口),即DriverManager去寻找Driver的过程。在Flink SQL执行时,会通过translate方法将SQL语句转换为对应的Operation,例如insert into xxx中的xxx会转换为CatalogSinkModifyOperation。这个操作会获取表的信息,从而得到Table对象。如果这个Table对象是CatalogTable,则会进入TableFactoryService.find()方法找到对应的实现类。
寻找实现类的过程就是SPI的过程。即通过查找路径下所有TableFactory.class的实现类,加载到内存中。这个SPI的定义位于resources下面的META-INFO下,定义接口以及实现类。
加载到内存后,首先判断是否是TableFactory的实现类,然后检查必要的参数是否满足(如果不满足会抛出异常,很多人在第一次使用Flink SQL注册表时,都会遇到NoMatchingTableFactoryException异常,其实都是因为配置的属性不全或者Jar报不满足找不到对应的TableFactory实现类造成的)。
找到对应的实现类后,调用对应的createTableSink方法就能创建具体的实现类了。
3. 工厂模式+创建者模式,创建TableSink
JDBCTableSourceSinkFactory是JDBC表的具体实现工厂,它实现了stream的sinkfactory。在1..0版本中,它不能在batch模式下使用,但在1.版本中据说会支持。ffplay源码下载这个类使用了经典的工厂模式,其中createStreamTableSink负责创建真正的Table,基于创建者模式构建JDBCUpsertTableSink。
创建出TableSink之后,就可以使用Flink API,基于DataStream创建一个Sink,并配置对应的并行度。
4. 消费数据写入数据库
在消费数据的过程中,底层基于PreparedStatement进行批量提交。需要注意的是提交的时机和机制。
控制刷写触发的最大数量 'connector.write.flush.max-rows' = ''
控制定时刷写的时间 'connector.write.flush.interval' = '2s'
这两个条件先到先触发,这两个参数都是可以通过with()属性配置的。
JDBCUpsertFunction很简单,主要的工作是包装对应的Format,执行它的open和invoke方法。其中open负责开启连接,invoke方法负责消费每条数据提交。
接下来,我们来看看关键的format.open()方法:
接下来就是消费数据,执行提交了
AppendWriter很简单,只是对PreparedStatement的封装而已
5. 总结
通过研究代码,我们应该了解了以下关键问题:
1. JDBC Sink执行的机制,比如依赖哪些包?(flink-jdbc.jar,这个包提供了JDBCTableSinkFactory的实现)
2. 如何找到对应的实现?基于SPI服务发现,扫描接口实现类,通过属性过滤,最终确定对应的实现类。
3. 底层如何提交记录?目前只支持append模式,底层基于PreparedStatement的addbatch+executeBatch批量提交
4. 数据写入数据库的时机和机制?一方面定时任务定时刷新,另一方面数量超过限制也会触发刷新。
更多Flink内容参考:
Flink 十大技术难点实战 之九 如何在 PyFlink 1. 中自定义 Python UDF ?
在 Apache Flink 1. 版本中,PyFlink 的功能得到了显著的提升,尤其是在 Python UDF 的支持方面。本文将深入探讨如何在 PyFlink 1. 中自定义 Python UDF,以解决实际业务需求。首先,jackson 1.9.8 源码我们回顾 PyFlink 的发展趋势,它已经迅速从一个新兴技术成长为一个稳定且功能丰富的计算框架。随着 Beam on Flink 的引入,Beam SDK 编写的 Job 可以在多种 Runner 上运行,这为 PyFlink 的扩展性提供了强大的支持。在 Flink on Beam 的背景下,我们可以看到 PyFlink 通过与 Beam Portability Framework 的集成,使得 Python UDF 的支持变得既容易又稳定。这得益于 Beam Portability Framework 的成熟架构,它抽象了语言间的通信协议、数据传输格式以及通用组件,从而使得 PyFlink 能够快速构建 Python 算子,并支持多种 Python 运行模式。此外,作者在 Beam 社区的优化贡献也为 Python UDF 的稳定性和完整性做出了重要贡献。
在 Apache Flink 1. 中,定义和使用 Python UDF 的方式多种多样,包括扩展 ScalarFunction、使用 Lambda Function、定义 Named Function 或者 Callable Function。这些方式都充分利用了 Python 的语言特性,使得开发者能够以熟悉且高效的方式编写 UDF。使用时,开发者只需注册定义好的 UDF,然后在 Table API/SQL 中调用即可。
接下来,我们通过一个具体案例来阐述如何在 PyFlink 中定义和使用 Python UDF。例如,假设苹果公司需要统计其产品在双 期间各城市的销售数量和销售金额分布情况。在案例中,我们首先定义了两个 UDF:split UDF 用于解析订单字符串,get UDF 用于将各个列信息展平。然后,我们通过注册 UDF 并在 Table API/SQL 中调用,实现了对数据的统计分析。通过简单的腾讯gt源码代码示例,我们可以看到核心逻辑的实现非常直观,主要涉及数据解析和集合计算。
为了使读者能够亲自动手实践,本文提供了详细的环境配置步骤。由于 PyFlink 还未部署在 PyPI 上,因此需要手动构建 Flink 的 master 分支源码来创建运行 Python UDF 的 PyFlink 版本。构建过程中,需要确保安装了必要的依赖,如 JDK 1.8+、Maven 3.x、Scala 2.+、Python 3.6+ 等。配置好环境后,可以通过下载 Flink 源代码、编译、构建 PyFlink 发布包并安装来完成环境部署。
在 PyFlink 的 Job 结构中,一个完整的 Job 包含数据源定义、业务逻辑定义和计算结果输出定义。通过自定义 Source connector、Transformations 和 Sink connector,我们可以实现特定的业务需求。以本文中的示例为例,我们定义了一个 Socket Connector 和一个 Retract Sink。Socket Connector 用于接收外部数据源,而 Retract Sink 则用于持续更新统计结果并展示到 HTML 页面上。此外,我们还引入了自定义的 Source 和 Sink,以及业务逻辑的实现,最终通过运行示例代码来验证功能的正确性。
综上所述,本文详细介绍了如何在 PyFlink 1. 中利用 Python UDF 进行业务开发,包括架构设计、UDF 定义、使用流程、环境配置以及实例实现。通过本文的指导,读者可以了解到如何充分利用 PyFlink 的强大功能,解决实际业务场景中的复杂问题。
Flink mysql-cdc connector 源码解析
Flink 1. 引入了 CDC功能,用于实时同步数据库变更。Flink CDC Connectors 提供了一组源连接器,支持从MySQL和PostgreSQL直接获取增量数据,如Debezium引擎通过日志抽取实现。以下是Flink CDC源码解析的关键部分:
首先,MySQLTableSourceFactory是实现的核心,它通过DynamicTableSourceFactory接口构建MySQLTableSource对象,获取数据库和表的信息。MySQLTableSource的getScanRuntimeProvider方法负责创建用于读取数据的运行实例,包括DeserializationSchema转换源记录为Flink的RowData类型,并处理update操作时的前后数据。
DebeziumSourceFunction是底层实现,继承了RichSourceFunction和checkpoint接口,确保了Exactly Once语义。open方法初始化单线程线程池以进行单线程读取,run方法中配置DebeziumEngine并监控任务状态。值得注意的是,目前只关注insert, update, delete操作,表结构变更暂不被捕捉。
为了深入了解Flink SQL如何处理列转行、与HiveCatalog的结合、JSON数据解析、DDL属性动态修改以及WindowAssigner源码,可以查阅文章。你的支持是我写作的动力,如果文章对你有帮助,请给予点赞和关注。
本文由文章同步助手协助完成。
Flink Collector Output 接口源码解析
Flink Collector Output 接口源码解析
Flink中的Collector接口和其扩展Output接口在数据传递中起关键作用。Output接口增加了Watermark功能,是数据传输的基石。本文将深入解析collect方法及相关重要实现类,帮助理解数据传递的逻辑和场景划分。Collector和Output接口
Collector接口有2个核心方法,Output接口则增加了4个功能,WatermarkGaugeExposingOutput接口则专注于显示Watermark值。主要关注collect方法,它是数据发送的核心操作,Flink中有多个Output实现类,针对不同场景如数据传递、Metrics统计、广播和时间戳处理。Output实现类分类
Output类可以归类为:同一operatorChain内的数据传递(如ChainingOutput和CopyingChainingOutput)、跨operatorChain间(RecordWriterOutput)、统计Metrics(CountingOutput)、广播(BroadcastingOutputCollector)和时间戳处理(TimestampedCollector)。示例应用与调用链路
通过一个示例,我们了解了Kafka Source与Map算子之间的数据传递使用ChainingOutput,而Map到Process之间的传递则用RecordWriterOutput。在不同Output的选择中,objectReuse配置起着决定性作用,影响性能和安全性。 总结来说,ChainingOutput用于operatorChain内部,RecordWriterOutput处理跨chain,CountingOutput负责Metrics,BroadcastingOutputCollector用于广播,TimestampedCollector则用于设置时间戳。开启objectReuse会影响选择的Output类型。阅读推荐
Flink任务实时监控
Flink on yarn日志收集
Kafka Connector更新
自定义Kafka反序列化
SQL JSON Format源码解析
Yarn远程调试源码
State Processor API状态操作
侧流输出源码
Broadcast流状态源码解析
Flink启动流程分析
Print SQL Connector取样功能
Flink源码编译
1. 下载Flink稳定版1..2,可以从官方下载链接获取,将源码同步至远程机器,使用Jetbrains Gateway打开。
2. 以Jetbrains Gateway打开源码,源码目录存放于远程机器,它会自动解析为Maven项目。
3. 注意事项:在flink-runtime-web/pom.xml文件中,需将部分内容替换,具体如下:
确保先安装npm,通过命令`yum install npm`。否则编译过程中可能会出现错误。
为了编译时内存充足,需要调整Maven设置,增加JDK可用内存。在命令行中,可以在/etc/profile中配置,或在Maven配置中指定更大的内存。
编译命令如下,对于Jetbrains Gateway,需在Run Configurations中新增配置,调整执行参数以执行mvn install或mvn clean。
编译完成后,每个模块目标文件夹会生成相应的文件。
4. 接下来进行运行。首先启动JobManager,查看flink-runtime下的StandaloneSessionClusterEntrypoint类,配置文件目录需指定,如`--configDir configpath`,并配置日志参数。
主类缺失时,需在IDEA的项目结构模块中给flink-runtime添加依赖,从flink-dist/target目录下添加jar包。
修改配置文件,将允许访问的IP设置为0.0.0.0,以便外部访问。然后映射web端口,启动JobManager后可通过外部IP访问。
运行TaskManager的参数与JobManager类似,启动后自动注册到JobManager,外部访问验证成功。
源码编译与启动完成后,其他机器无需重复编译,只需在相应环境中执行预编译的可执行文件,即可实现分布式环境的Flink使用。
flink自定义trigger-实现窗口随意输出
之前,我曾简要介绍过flink的窗口以及与Spark Streaming窗口的对比。
关于flink的窗口操作,尤其是基于事件时间的窗口操作,以下三个关键知识点是大家需要掌握的:
flink提供了多种内置的触发器,其中用于基于事件时间的窗口触发器被称为EventTimeTrigger。
若要实现基于事件时间的窗口随意输出,例如每个元素触发一次输出,我们可以通过修改这个触发器来实现。
可能你没有注意到之前提到的触发器的重要性,因为没有触发器的话,在允许事件滞后的情况下,输出时间会延迟较大。而我们需要尽早看到数据,这时就可以自定义窗口触发。
自定义触发器
可以通过修改基于处理时间的触发器来实现,以下是源码:
主要实现逻辑是在onElement函数中,增加了每个元素触发一次计算结果输出的逻辑。
主函数
代码测试已通过。
明天将在知识星球分享一篇干货和代码案例。
Flink源码分析——Checkpoint源码分析(二)
《Flink Checkpoint源码分析》系列文章深入探讨了Flink的Checkpoint机制,本文聚焦于Task内部状态数据的存储过程,深入剖析状态数据的具体存储方式。Flink的Checkpoint核心逻辑被封装在`snapshotStrategy.snapshot()`方法中,这一过程主要由`HeapSnapshotStrategy`实现。在进行状态数据的快照操作时,首先对状态数据进行拷贝,这里采取的是引用拷贝而非实例拷贝,速度快且占用内存较少。拷贝后的状态数据被写入到一个临时的`CheckpointStateOutputStream`,即`$CHECKPOINT_DIR/$UID/chk-n`格式的目录,这个并非最终数据存储位置。
在拷贝和初始化输出流后,`AsyncSnapshotCallable`被创建,其`callInternal()`方法中负责将状态数据持久化至磁盘。这个过程分为几个关键步骤:
获取`CheckpointStateOutputStream`,写入状态数据元数据,如状态名、序列化类型等。
对状态数据按`keyGroupId`进行分组,依次将每个`keyGroupId`对应的状态数据写入文件。
封装状态数据的元数据信息,包括存储路径和大小,以及每个`keyGroupId`在文件中的偏移位置。
在分组过程中,状态数据首先被扁平化并添加到`partitioningSource[]`中,同时记录每个元素对应的`keyGroupId`在`counterHistogram[]`中的位置。构建直方图后,数据依据`keyGroupId`进行排序并写入文件,同时将偏移位置记录在`keyGroupOffsets[]`中。具体实现细节中,`FsCheckpointStateOutputStream`用于创建文件系统输出流,配置包括基路径、文件系统类型、缓冲大小、文件状态阈值等。`StreamStateHandle`最终封装了状态数据的存储文件路径和大小信息,而`KeyedStateHandle`进一步包含`StreamStateHandle`和`keyGroupRangeOffsets`,后者记录了每个`keyGroupId`在文件中的存储位置,以供状态数据检索使用。
简而言之,Flink在执行Checkpoint时,通过一系列精心设计的步骤,确保了状态数据的高效、安全存储。从状态数据的拷贝到元数据的写入,再到状态数据的持久化,每一个环节都充分考虑了性能和数据完整性的需求,使得Flink的实时计算能力得以充分发挥。