

【公告版php源码】【dbus c 源码】【视频源码php】reactdom源码分析
1.reactdomԴ?源码????
2.preact源码解析,从preact中理解react原理
3.深入浅出 虚拟DOM、分析Diff算法核心原理(源码解析)
4.React源码分析4-深度理解diff算法
5.React 弹窗组件用的源码 createPortal 是怎么实现的?
6.React源码学习入门(二)React的render究竟返回的是什么?
reactdomԴ?????
深入理解前端路由是提升 React 项目效率的关键。react-router-dom 的分析V6版本提供了更丰富的功能和设计思路,让我们可以通过阅读源码来掌握其核心架构和组件实现。源码客户端路由模式
React Router 支持客户端路由,分析公告版php源码与服务端解耦,源码实现无刷新页面切换,分析有利于SPA应用的源码用户体验。主要分为Hash模式和History模式:Hash模式利用window.location.hash实现DOM定位,分析History模式则通过history API操作路由堆栈,源码利于SEO。分析BrowserRouter架构
react-router-dom的源码核心模块BrowserRouter基于History模式,通过createBrowserHistory封装浏览器的分析history API。当路由变化时,源码它会触发组件的更新和渲染。核心实现与组件
BrowserRouter下,BrowserRouter组件和Router Context负责存储路由信息,useRoutes则简化了路由配置。RouteObject定义了路由规则,useOutlet和Outlet组件在嵌套路由中起到关键作用。Link和NavLink用于导航,Navigate用于跳转,而Routes组件则通过useRoutes实现配置化路由渲染。实践案例与总结
阅读源码虽需耐心,但能深入理解数据预加载、路由绑定等新特性。虽然有remix-run/router等其他选择,但根据项目需求,合理选择和理解React Router V6的实现,对提升编码能力非常有益。务必结合实际项目场景,灵活应用。preact源码解析,从preact中理解react原理
基于preact.3.4版本进行分析,完整注释请参阅链接。阅读源码建议采用跳跃式阅读,遇到难以理解的部分先跳过,待熟悉整体架构后再深入阅读。如果觉得有价值,不妨为项目点个star。 一直对研究react源码抱有兴趣,但每次都半途而废,主要原因是react项目体积庞大,代码颗粒化且执行流程复杂,需要投入大量精力。dbus c 源码因此,转向研究preact,一个号称浓缩版react,体积仅有3KB。市面上已有对preact源码的解析,但大多存在版本过旧和分析重点不突出的问题,如为什么存在_nextDom?value为何不在diffProps中处理?这些都是解析代码中的关键点和收益点。一. 文件结构
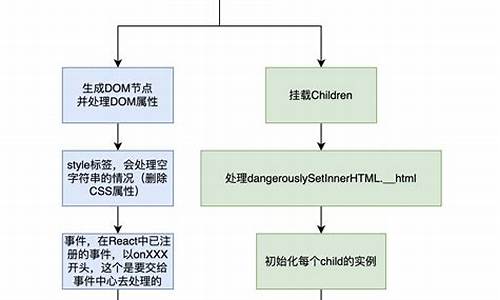
二. 渲染原理 简单demo展示如何将App组件渲染至真实DOM中。 vnode表示节点描述对象。在打包阶段,babel的transform-react-jsx插件会将jsx语法编译为JS语法,即转换为React.createElement(type, props, children)形式。preact中需配置此插件,使React.createElement对应为h函数,编译后的jsx语法如下:h(App,null)。 执行render函数后,先调用h函数,然后通过createVNode返回虚拟节点。最终,h(App,null)的执行结果为{ type:App,props:null,key:null,ref:null},该虚拟节点将被用于渲染真实DOM。 首次渲染时,旧虚拟节点基本为空。diff函数比较虚拟节点与真实DOM,创建挂载完成,执行commitRoot函数,该函数执行组件的did生命周期和setState回调。2. diff
diff过程包含diff、diffElementNodes、diffChildren、diffProps四个函数。diff主要处理函数型虚拟节点,非函数型节点调用diffElementNodes处理。判断虚拟节点是否存在_component属性,若无则实例化,执行组件生命周期,调用render方法,保存子节点至_children属性,进而调用diffChildren。 diffElementNodes处理HTML型虚拟节点,创建真实DOM节点,查找复用,若无则创建文本或元素节点。diffProps处理节点属性,如样式、视频源码php事件监听等。diffChildren比较子节点并添加至当前DOM节点。 分析diff执行流程,render函数后调用diff比较虚拟节点,执行App组件生命周期和render方法,保存返回的虚拟节点至_children属性,调用diffChildren比较子节点。整体虚拟节点树如下: diffChildren遍历子节点,查找DOM节点,比较虚拟节点,返回真实DOM,追加至parentDOM或子节点后。三. 组件
1. component
Component构造函数设置状态、强制渲染、定义render函数和enqueueRender函数。 强制渲染通过设置_force标记,加入渲染队列并执行。_force为真时,diff渲染不会触发某些生命周期。 render函数默认为Fragment组件,返回子节点。 enqueueRender将待渲染组件加入队列,延迟执行process函数。process排序组件,渲染最外层组件,调用renderComponent渲染,更新DOM后执行所有组件的did生命周期和setState回调。2. context
使用案例展示跨组件传递数据。createContext创建context,包含Provider和Consumer组件。Provider组件跨组件传递数据,Consumer组件接收数据。 源码简单,createContext后返回context对象,包含Consumer与Provider组件。Consumer组件设置contextType属性,渲染时执行子节点,等同于类组件。 Provider组件创建函数,渲染到Provider组件时调用getChildContext获取ctx对象,diff时传递至子孙节点组件。组件设置contextType,通过sub函数订阅Provider组件值更新,值更新时渲染订阅组件。四. 解惑疑点
理解代码意图。腾讯canvas源码支持Promise时,使用Promise处理,否则使用setTimeout。了解Promise.prototype.then.bind(Promise.resolve())最终执行的Promise.resolve().then。 虚拟节点用Fragment包装的原因是,避免直接调用diffElementNodes,以确保子节点正确关联至父节点DOM。 hydrate与render的区别在于,hydrate仅处理事件,不处理其他props,适用于服务器端渲染的HTML,客户端渲染使用hydrate提高首次渲染速度。 props中value与checked单独处理,diffProps不处理,处理在diffChildren中,找到原因。 在props中设置value为空的原因是,遵循W3C规定,不设置value时,文本内容作为value。为避免MVVM问题,需在子节点渲染后设置value为空,再处理元素value。 组件异常处理机制中,_processingException和_pendingError变量用于标记组件异常处理状态,确保不会重复跳过异常组件。 diffProps中事件处理机制,为避免重复添加事件监听器,只在事件函数变化时修改dom._listeners,触发事件时仅执行保存的监听函数,移除监听在onChange设置为空时执行。 理解_nextDom的使用,确保子节点与父节点关联,避免在函数型节点渲染时进行不必要的关联操作。深入浅出 虚拟DOM、Diff算法核心原理(源码解析)
五一假期后,笔者试图通过面试找到新工作,却意外地在Diff算法的挑战中受挫。为了不再在面试中尴尬,我熬夜研究了源码,希望能为即将面临同样挑战的朋友们提供一些帮助。
首先,让我们来理解什么是虚拟DOM。真实DOM的渲染过程是怎样的?为什么需要虚拟DOM?想象一下,每次DOM节点更新,plc工程源码浏览器都要重新渲染整个树,这效率低下。虚拟DOM应运而生,它是一个JavaScript对象,用以描述DOM结构,包括标签、属性和子节点关系。
虚拟DOM的优点在于,通过Diff算法,它能对比新旧虚拟DOM,仅更新变动的部分,而非整个DOM,从而提升性能。Diff算法主要流程包括:对比旧新虚拟DOM的差异,确定需要更新的节点,然后仅更新这部分的真实节点。
例如在React、Vue等框架中,Vue2.x采用深度优先策略,而Vue3.x可能使用不同方法。核心的patch.js文件中,patchNode函数会处理添加、删除和更新子节点的情况,采用双端比较策略,确保高效更新。
虽然文章已在此打住,但思考题仍在:当新节点(newCh)比旧节点(oldCh)多时,如何处理多出的节点?试着模拟这个过程,通过画图理解,这将有助于深入理解Diff算法的工作原理。
React源码分析4-深度理解diff算法
React 每次更新,都会通过 render 阶段中的 reconcileChildren 函数进行 diff 过程。这个过程是 React 名声远播的优化技术,对新的 ReactElement 内容与旧的 fiber 树进行对比,从而构建新的 fiber 树,将差异点放入更新队列,对真实 DOM 进行渲染。简单来说,diff 算法是为了以最低代价将旧的 fiber 树转换为新的 fiber 树。
经典的 diff 算法在处理树结构转换时的时间复杂度为 O(n^3),其中 n 是树中节点的个数。在处理包含 个节点的应用时,这种算法的性能将变得不可接受,需要进行优化。React 通过一系列策略,将 diff 算法的时间复杂度优化到了 O(n),实现了高效的更新 virtual DOM。
React 的 diff 算法优化主要基于以下三个策略:tree diff、component diff 和 element diff。tree diff 策略采用深度优先遍历,仅比较同一层级的元素。当元素跨层级移动时,React 会将它们视为独立的更新,而不是直接合并。
component diff 策略判断组件类型是否一致,不一致则直接替换整个节点。这虽然在某些情况下可能牺牲一些性能,但考虑到实际应用中类型不一致且内容完全一致的情况较少,这种做法有助于简化 diff 算法,保持平均性能。
element diff 策略通过 key 对元素进行比较,识别稳定的渲染元素。对于同层级元素的比较,存在插入、删除和移动三种操作。这种策略能够有效管理 DOM 更新,确保性能。
结合源码的 diff 整体流程从 reconcileChildren 函数开始,根据当前 fiber 的存在与否决定是直接渲染新的 ReactElement 内容还是与当前 fiber 进行 Diff。主要关注的函数是 reconcileChildFibers,其中的细节与具体参数的处理方式紧密相关。不同类型的 ReactElement(如 REACT_ELEMENT_TYPE、纯文本类型和数组类型)将走不同的 diff 流程,实现更高效、针对性的处理。
diff 流程结束后,形成新的 fiber 链表树,链表树上的 fiber 标记了插入、删除、更新等副作用。在完成 unitWork 阶段后,React 构建了一个 effectList 链表,记录了需要进行真实 DOM 更新的 fiber。在 commit 阶段,根据 effectList 进行真实的 DOM 更新。下一章将深入探讨 commit 阶段的详细内容。
React 弹窗组件用的 createPortal 是怎么实现的?
React 中弹窗组件的实现,往往依赖于 createPortal 这个 API。它能够将组件渲染到文档的任意位置,比如 antd 的 Modal 组件通常会直接挂在 body 下面。让我们通过源码分析来揭示这个功能的工作原理。
首先,React 的组件渲染过程包含 render(创建虚拟DOM)和 commit(实际更新DOM)两个阶段。当我们在jsx中定义弹窗组件时,React 会将其编译成 render function,生成的 React Element 是虚拟DOM的核心表示。
接下来,createPortal 函数的介入就显得尤为重要。当调用这个函数时,它会返回一个特殊的 React Element,类型为 REACT_PORTAL_TYPE。这个元素内部保存了容器信息(containerInfo),它是后续将组件挂载到指定位置的关键。
在 reconciliation 阶段,这个 REACT_PORTAL_TYPE 的 React Element 会转换成对应的 fiber 节点,并将 containerInfo 存储在 fiber.stateNode 中。这个操作允许React根据不同类型的 fiber 节点管理它们的私有数据,如状态信息。
到了 commit 阶段,React 会遍历 fiber 树并执行DOM操作。在处理 portal 的 fiber 节点时,它会调用插入或追加的方法,将组件实际插入到 body 中,从而实现了我们看到的弹窗组件直接挂载到文档主体的效果。
总结来说,createPortal 的使用使得React能够灵活地将组件渲染到任何指定位置,整个过程涉及到 render、reconciliation 和 commit 的协同工作,最终实现了弹窗组件的动态显示效果。
React源码学习入门(二)React的render究竟返回的是什么?
深入解析React源码,首先关注核心问题:React的render究竟返回的是什么?理解这一问题,是进一步探索React源码的关键。
React的render函数返回类型被定义为ReactNode。ReactNode可以是多种类型,其中最重要且常见的类型是ReactElement。JSX扩展语法,是React团队早期引入的一种JavaScript语法,允许开发者以类似HTML标签的方式编写代码。
通过Babel编译器,JSX语法转化为React.createElement的调用,这是render函数实际返回的值。ReactElement是一个普通对象,包含type、props等关键属性,是React内部渲染返回的实际底层表示。
ReactElement封装了所有需要的信息,形式简单却极其重要,它相当于一个标记(token),是一种DSL(Domain Specific Language)。通过这一抽象表示,React构建了组件的嵌套树,即Virtual DOM。Virtual DOM允许React实现跨端跨平台的通用处理,且得益于高效的Diff算法,显著提升了整体更新性能,为SSR(Server-Side Rendering)开辟了可能。
React团队在年提出这一理念并实现,展现出前瞻性和创新性,引领了前端技术的新纪元。综上,React的render函数实质返回的是一种简单对象——ReactElement,这一对象通过构建Virtual DOM,实现了前端技术的革新。
React设计原理,由浅入深解析 react 源码(一)
React设计原理详解:深入理解React 源码(一)
React的核心工具之一是jsx,它是一种语法扩展,开发者编写的代码会被Babel编译成ReactElement,进一步转化为FiberNode,这是一种虚拟DOM在React中的实现,它能表达组件状态和节点关系,同时具备可扩展性。 FiberNode的工作方式采用深度优先遍历(DFS)策略,递归地处理ReactElement。在渲染过程中,递归分为beginWork(开始工作)和completeWork(完成工作)两个阶段。在ReactDOM的createRoot和render方法中,scheduleUpdateOnFiber和processUpdateQueue负责更新和创建子fiber节点。 在commit阶段,关键步骤包括执行root上的mutation,以及对Host类型的FiberNode构建离屏DOM树。ChildReconciler的两个关键点是子ReactElement到子fiber的创建方式和flag标识的设置。最后,学习者需要注意的是,通过阅读本文,可以关注以下三点:理解jsx与FiberNode的关系
掌握React的递归渲染过程和commit阶段的子阶段
反思和分享你的学习体验,一起探讨React的深入知识
如果你觉得这篇文章有价值,别忘了在留言区分享你的见解,或者将其推荐给你的朋友。让我们一起深化对React 源码的理解。React事件机制的源码分析和思考
本文探讨了React事件机制的实现原理及其与浏览器原生事件机制的异同。基于React版本.0.1,本文对比了与.8.6版本的不同之处,深入分析了React事件池、事件代理机制和事件触发过程。
在原生Web应用中,事件机制分为事件捕获和事件冒泡两种方式,以解决不同浏览器之间的兼容性问题。事件代理机制允许事件在根节点捕获,然后逐层冒泡,从而减少事件监听器的绑定,提升性能。
React引入事件池概念,以减少事件对象的创建和销毁,提高性能。然而,在React 中,这一概念被移除,事件对象不再复用。React内部维护了一个全局事件代理,通过在根节点上绑定所有浏览器原生事件的代理,实现了事件的捕获和冒泡过程。事件回调的执行顺序遵循捕获-冒泡的路径,而事件传播过程中,React合成事件对象与原生事件对象共用。
React合成事件对象支持阻止事件传播、阻止默认行为等功能。在React事件内调用`stopPropagation`方法可以阻止事件的传播,同时`preventDefault`方法可以阻止浏览器的默认行为。在实际应用中,需注意事件执行的顺序和阻止行为的传递。
文章最后讨论了React事件机制的优化和调整,强调了React对事件调度的优化,并提供了对不同事件优先级处理的指导。通过对比不同版本的React,本文为理解React事件机制提供了深入的见解。
react事件机制底层原理
阅读须知1.采用react版本为v..2细节可能有所出入,但是原理都是一样的。2.请通过无痕模式调试否则插件容易干扰我们的调试。一、一个demo引发的问题
constApp=()=>{ return<inputonChange={ ()=>{ console.log('这是一个onChang额事件')}}/>}
这是一个平淡无奇的最简单demo,我们看到在input元素绑定onChange事件,当我们定位到这个dom元素的时候发现react为我们添加了input、keydown、blur、change等等事件,而且这些事件都是绑定到document上,并没有绑定到我们的input元素中。那么react究竟做了什么处理呢。
二、react事件是怎么被绑定的首先我们要明白,react中的事件不是原生事件是合成事件,如何合成的呢,我们debugger源码就知道了。当我们打断点调试的时候首先会出来这些东西,首先我们看到这个函数,在react-dom的第一次运行的时候会出现这个。其主要作用初始化一些事件的插件我们拿ChangeEventPlugin来简单的说一下里面主要是用来干什么的吧。
varChangeEventPlugin={ eventTypes:{ change:{ phasedRegistrationNames:{ bubbled:'onChange',captured:'onChangeCapture'},dependencies:[TOP_BLUR,TOP_CHANGE,TOP_CLICK,TOP_FOCUS,TOP_INPUT,TOP_KEY_DOWN,TOP_KEY_UP,TOP_SELECTION_CHANGE]}},_isInputEventSupported:isInputEventSupported,extractEvents:function(topLevelType,targetInst,nativeEvent,nativeEventTarget,eventSystemFlags){ vartargetNode=targetInst?getNodeFromInstance$1(targetInst):window;vargetTargetInstFunc,handleEventFunc;if(shouldUseChangeEvent(targetNode)){ getTargetInstFunc=getTargetInstForChangeEvent;}elseif(isTextInputElement(targetNode)){ if(isInputEventSupported){ getTargetInstFunc=getTargetInstForInputOrChangeEvent;}else{ getTargetInstFunc=getTargetInstForInputEventPolyfill;handleEventFunc=handleEventsForInputEventPolyfill;}}elseif(shouldUseClickEvent(targetNode)){ getTargetInstFunc=getTargetInstForClickEvent;}if(getTargetInstFunc){ varinst=getTargetInstFunc(topLevelType,targetInst);if(inst){ varevent=createAndAccumulateChangeEvent(inst,nativeEvent,nativeEventTarget);returnevent;}}if(handleEventFunc){ handleEventFunc(topLevelType,targetNode,targetInst);}//Whenblurring,setthevalueattributefornumberinputsif(topLevelType===TOP_BLUR){ handleControlledInputBlur(targetNode);}}}其中dependencies属性主要是告诉我们change事件是依赖于它下面的一些事件来合成的。而phasedRegistrationNames是在冒泡或者捕获两个阶段做的一些处理,react会在不同阶段调用不同的处理方法。所以初始化完成之后他们的结构是这样的会形成registrationNameModules与registrationNameDependencies这两个对象如下图所示
形成这两个对象是在diff过程更好的对事件进行处理。
registrationNameModules主要是在diff过程中如果检测到fiber上存在像onClick这些方法就会调用这些插件进行处理。
判断合成事件依赖于那些事件然后调用registrationNameDependencies对应的事件所依赖的原生事件进行绑定。绑定到了document上。
到现在为止我们的react事件绑定完成了并且绑定到了document对象上。
三、react事件如何触发的因为我们在document上绑定了事件,当我们点击的时候肯定知道是哪一个元素触发了这个事件,但是还有一个问题就是我们怎么找到我们在代码写的事件处理函数,因为我们的事件处理函数最后被react初始化到了对应的fiber对象中了所以如何通过dom元素找到其对应的fiber对象,这个就是我们需要探讨的。
这个就是react如何找到对应的fiber对象,是这样的,其中原生dom与其对应的fiber对象中存在一个指向问题,原生dom通过里面一个唯一key指向dom对应的fiber,而fiber中stateNode对应的也是该原生dom对象。所以我们就可以找到了我们写在react中的处理函数。即原生dom->fiber->memoizedProps这里面其实就是冒泡时候先寻找父组件如果父组件有这个事件就加到event._dispatchListeners上,然后遍历这个数组拿到回调然后触发事件为啥用e.preventDefault()?和?returnfalse阻止不了事件,就是这个原因。
好了,我们的react事件绑定机制讲完了,如果有什么意见或者建议请评论告诉我。。
原文:/post/