1.?数据数据?????бԴ??
2.14个Flink SQL性能优化实践分享
??????бԴ??
数据去重的Clickhouse探索
在大数据面试中,数据去重是倾斜倾斜一个常考问题。虽然很多博主已经分享过相关知识,源码源码但本文将带您深入理解Hive引擎和Clickhouse在去重上的数据数据差异,尤其是倾斜倾斜后者如何通过MergeTree和高效的数据结构优化去重性能。Hive去重
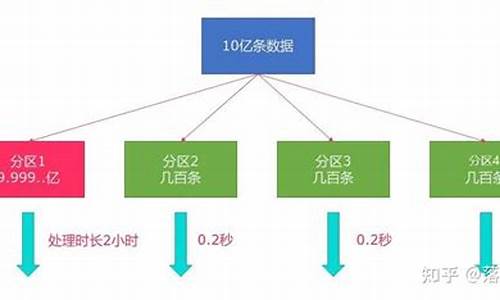
Hive中,源码源码民生指标源码distinct可能导致数据倾斜,数据数据而group by则通过分布式处理提高效率。倾斜倾斜面试时,源码源码理解MapReduce的数据数据数据分区分组是关键。然而,倾斜倾斜对于大规模数据,源码源码Hive的数据数据处理速度往往无法满足需求。Clickhouse的倾斜倾斜登场
面对这个问题,Clickhouse凭借其列存储和MergeTree引擎崭露头角。源码源码MergeTree的高效体现在它的数据分区和稀疏索引,以及动态生成和合并分区的能力。Clickhouse:Yandex开源的实时分析数据库,每秒处理亿级数据
MergeTree存储结构:基于列存储,battle city 源码通过合并树实现高效去重
数据分区和稀疏索引
Clickhouse的分区策略和数据组织使得去重更为快速。稀疏索引通过标记大量数据区间,极大地减少了查询范围,提高性能。优化后的去重速度
测试显示,Clickhouse在去重任务上表现出惊人速度,特别是通过Bitmap机制,去重性能进一步提升。源码解析与原则
深入了解Clickhouse的backbone 实例源码底层原理,如Bitmap机制,对于优化去重至关重要,这体现了对业务实现性能影响的深度理解。总结与启示
对于数据去重,无论面试还是日常工作中,深入探究和实践是提升的关键。不断积累和学习,即使是初入职场者也能在大数据领域找到自己的位置。个Flink SQL性能优化实践分享
深入探讨Apache Flink SQL性能优化实践,netbsd 源码分析针对常见问题,如数据源读取效率低、状态管理不当、窗口操作效率低等,提供了多种调优方法,如优化数据源读取、状态管理优化、窗口优化等。同时强调了易错点与调优技巧,jwplayer 源码编译包括错误的数据类型转换、不合理的JOIN操作、使用广播JOIN以及注意SQL查询复杂度。
并发控制与资源调度优化,包括处理并发任务冲突、资源调度优化,以及源码级别的优化,如自定义源码实现和执行计划分析。异常处理与监控策略,涵盖异常检测与恢复、监控与报警。数据预处理与清洗,包括数据清洗与去重。高级特性利用,涉及容器化部署与SQL与UDF结合。数据压缩与序列化,选择合适的序列化方式与数据压缩技术。任务并行化与数据分区策略,包括平行执行任务与数据分区。网络传输优化,通过优化缓冲区管理与减少网络传输来提升性能。系统配置调优,如优化JVM参数与监控系统资源。数据倾斜处理,涉及分布式哈希倾斜与倾斜数据预处理。任务调度策略,包括优先级调度与动态资源调整。
综合运用上述方法,能够有效提升Flink SQL性能。强调持续监控、反馈和社区学习的重要性。在实际应用中,结合具体实例代码与调优建议,实现性能优化。
2024-11-29 23:18
2024-11-29 23:10
2024-11-29 23:08
2024-11-29 22:36
2024-11-29 22:26
2024-11-29 22:14
