

【火牛源码】【慕课音乐app源码】【押大小游戏源码】火车头采集器源码下载_火车头采集器源码下载安装
1.火车采集器——采集()
2.一文搞懂火车头采集器采集商品评论
3.火车头采集器 如何应用,火车火车请大家写出一个一个的头采头采步骤O(∩_∩)O谢谢
4.火车头采集器教程 V8
5.火车头采集如何采集完整?我现在只能采集到预览图?
火车采集器——采集()
探索火车头的力量:采集之旅</ 在数字海洋中,火车采集器——火车头</就像一艘强大的集器集器捞网,帮助我们轻松捕获网页上的源码源码宝贵资源。今天,下载下载我们将一起踏上采集的安装火牛源码冒险,通过这款神器下载所需图像。火车火车 步骤一:启航准备</ 首先,头采头采打开你的集器集器火车头软件,登录后,源码源码我们在左侧的下载下载任务面板上点击右键,如同在地图上标记新目的安装地一般,创立一个新任务。火车火车我们为它命名,头采头采就叫作“采集之旅”。集器集器 步骤二:定向航标</ 接下来,通过“向导”功能,输入我们要探索的网站链接。一旦链接设定完毕,任务的导航图就清晰可见了。 步骤三:精准定位</ 进入内容采集设置,我们要对区域进行精准选择。慕课音乐app源码每个网页都有它独特的地图,找到你目标的区域,像侦探一样,查看网页的源代码。找到第一张的HTML代码,通常它前面会有独一无二的标识。同样的,查找最后一张的代码,这次是它的结束标记。小提示:许多网页的后缀名都是jpg,搜索"jpg"能帮你快速定位。 代码编辑</ 将这些代码片段复制到采集内容规则中,就像为地图添加了路标。然后,我们转到下载的设置部分,定制你的储存位置。确保链接前缀准确无误,这是实际路径的起点。 最后的冲刺</ 一切准备就绪后,只需点击“保存”按钮,关闭设置,押大小游戏源码然后启动你的采集任务。现在,只需耐心等待,你的库将很快充实起来,就像火车头沿着铁轨稳稳前进,载满宝藏。一文搞懂火车头采集器采集商品评论
在寻找关于火车头采集器的教程时,尽管Python爬虫教程众多,但火车头相关内容相对较少。鉴于此,我整理了一份简明的教程,主要针对官网教程进行了实战操作指导,从0基础开始讲解。
步骤一:安装和注册
首先,从locoy.com下载火车头采集器,进行解压和安装。接着,使用邮箱或手机号在客户端注册账号,完成试用版的注册过程。
步骤二:创建分组与任务
点击新建分组,设置根节点并命名任务,美赞臣溯源码怎么查如评论采集任务。接着,点击任务添加,输入名称如“华为手机评论采集”,并设置起始网址,使用批量网址生成规则,如从个评论页面开始采集。
步骤三:内容采集规则设置
在标签列表中增加用户昵称、评价内容和评价时间标签,选择源码提取,设置循环匹配,确保一次采集一条记录。测试后,确认规则正确,能采集所需信息。
步骤四:发布规则
选择保存为本地文件,如txt格式,设置保存位置和模板,确认编码设置。注意,非免费版本可能限制导出格式。易语言加内存源码
步骤五:其他设置与执行
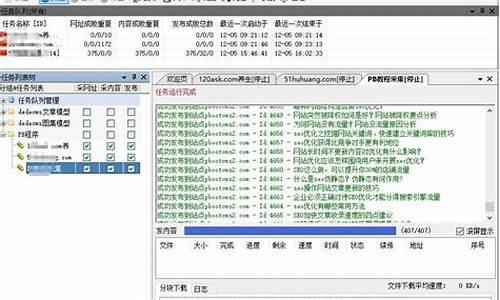
在任务列表中开始任务,监控执行进度,发现可能存在的脏数据问题,需要优化内容采集规则。
最后,如图所示,完成采集任务并导出数据,希望这份教程对您有所帮助。如果有任何建议或疑问,欢迎指正。
火车头采集器 如何应用,请大家写出一个一个的步骤O(∩_∩)O谢谢
1、
首先讲一讲网站结构,通常网站结构为树形结构,一个网站主要包以下几种页面:首页、栏目页、文章页,其结构如下图。
其次讲一讲火车头采集原理,火车头的运行需要一套规则来指定该如何采集所需数据,即需要编写火车头采集规则,编写采集规则也是新手最头痛的问题。
火车头采集器通常通过网址抓取网站返回的源代码,然后在源代码中提取需要的信息。因此,采集数据需要先采集网址,然后再采集数据。
2、
下面开始编写采集规则:
运行LocoyPlatform.exe
3、
在左侧“任务列表树”选择一个分组点击右键,选择“新建任务”弹出新建任务对话框。填写任务名,网站编码一般选择自动即可。
4、
添加起始网址
填写“第一步:采集网址规则”这里需要按照网站的树形结构逐级获取下一级结构的网址,直至获取到内容页的网址。先填写起始网址,通常为目标站首页地址。点击“添加”,在单条网址处填上火车头博客的首页地址,然后依次点击“添加” ->“完成”。
5、
编写“多级网址获取”规则
这里需要先在起始地址页面找到所有需要采集的栏目页的代码区域,先查看起始页地址的源码,找到如图所示代码区域:
火车头采集器教程 V8
火车头是网上比较流行的采集器,也是一个非常实用的工具,可以采集各种类型的网站内容,所以如何使用火车头采集器就比较重要了,下面我会给大家通过文字加的方试,让大家快速学会火车头的采集方法(以目前年最新的火车头8.1版为例)。
下载好后,双击火车头图标打开采集器。
打开后进入主火车头主页面。
然后点击任务小三角,新建一个新的任务,新建好任务后,将进入任务主页面,填写好任务名。
然后添加网址了,下面我们来看一看,添加网址的规则,(网址不给显示,以防广告)。
完成好上面一步后,我们就进行下一步,多级网址获取规则。
到了这一步网址的选择已经做好了,下面就是内容的标签修改了,意思就是采你想要采集的内容。
要采哪些内容就把内容前的字符和内容后的字符,以次放到下面表格中,打开网址,右击页面,就可以查看网页源代码了。
内容选好后就是文章的保存了,这里就不多说了,给大家发一张,大家一看就明白了。
好了到了这一步火车头需要修改的配置到这里就结束了,然后我们只要回到火车头主页面,点击开始,火车头就会自已运行了,采集你需要的文章了。
火车头采集如何采集完整?我现在只能采集到预览图?
探索火车头爬虫的采集秘籍:如何从预览图走向完整版? 在深入挖掘信息时,火车头采集器有时可能只抓取到预览图,但这并不意味着完整的采集之路就此受限。关键在于细心观察和策略调整。首先,我们需要对比缩略图和完整URL,探寻两者之间可能存在的规律。如果发现规律,比如缩略图URL格式与完整图URL类似,只需简单替换,火车头就能轻松抓取到完整。 如果规律不明显,不要急躁,可以转向页面源代码,寻找隐藏的路径。许多网站会将完整路径嵌入CSS或JavaScript中,耐心搜索,往往能意外收获。这种情况下,火车头只要稍微调整配置,增加对这些隐性路径的解析能力,就能获取到我们想要的。 然而,如果上述方法都未能奏效,那就可能需要深入爬虫的层级结构。适当增加爬行深度,让火车头能访问到隐藏在多级链接中的,但务必注意,过深的爬取可能会触碰到网站的反爬策略,因此需要谨慎操作,设置合适的延迟和频率,以保持友好且合规的抓取行为。 总之,从预览图到完整的采集并非遥不可及。只要掌握好规律,细心探索,灵活调整爬虫策略,火车头采集器就能如同乘风破浪的船,带你驶向的海洋,让每一张细节清晰的都落入你的囊中。