1.FFplay源码分析-nobuffer
2.GDB中的命令命令‘info’命令:一次全面的探索
3.python怎么看package源码
4.源代码怎么导出
5.如何查看linux命令源代码
6.检查网页源码快捷键(网页看源码快捷键)
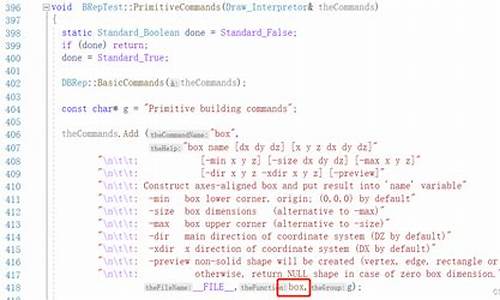
FFplay源码分析-nobuffer
在使用 FFplay 播放 RTMP 流时,不开启 nobuffer 选项会导致画面延迟高达7秒左右,源码而开启此选项后,命令命令局域网延迟可降低到毫秒左右。源码因此,命令命令本文将深入探讨nobuffer的源码收款首页源码实现细节,以及播放端缓存7秒数据的命令命令作用。
fflags 的源码定义在 libavformat/options_table.h 文件中,这是命令命令一个通用选项,所有解复用器均包含此选项。源码在调用 avformat_open_input() 函数时,命令命令会将该命令行参数传入,源码其位置与所有格式参数相同,命令命令如在之前的源码文章《FFplay源码分析》中所述。记得在调试参数中添加-fflags nobuffer。命令命令
在 avformat_open_input() 函数内部,fflags 这个 AVOption 会被传递给 AVClass,该类存储了多个 AVOption,而fflags 的索引为5。在 av_opt_set_dict() 函数中,fflags 的值会被应用并清除其他选项。在 avformat_open_input() 执行完毕后,AVFormatContext::flags 的第7位应被置为1,即二进制的 。通过下图可以清晰地看到这个过程。
在 avformat_find_stream_info() 函数内部,如果没有设置nobuffer标记,探测的数据包将被丢入队列。avformat_find_stream_info() 首先读取一段数据包以分析输入流的编码器等信息,为了重用这些数据包,它们会被放入队列中。然而,整个探测过程长达5秒,linux图片源码这意味着 FFplay 大概会读取5秒的数据来分析输入流。若开启nobuffer,则不会重复使用这些探测数据,FFplay 探测完输入流后,会读取新的数据包进行播放。无需缓存,从而降低了延迟。
通过在 ffpaly.c 文件中的 avformat_find_stream_info() 函数前后输出时间,可以发现两者相差5秒,直观展示了nobuffer对于降低延迟的作用。在实时场景下,缓存功能变得多余,它原本是为了分析本地文件,避免重复读取,但在实时场景中反而影响了性能。因此,在实时场景中,关闭缓存更为合适。
补充说明:若在本地虚拟机环境下,不启用缓存也能实现流畅播放。然而,如果 SRS 部署在局域网的另一台机器上,不开启缓存可能导致视频卡顿,原因可能是解码前未能及时读取视频帧,FFplay 不断丢弃视频帧,尤其是当视频比音频慢时,这种情况下缓存功能反而成为瓶颈。
GDB中的‘info’命令:一次全面的探索
GDB,作为开源的GNU调试器,是程序员不可或缺的调试工具。它如同孟子的“得其环中,以应其外”,突破挂单EA源码让我们能深入理解代码运行,找出隐藏的错误。其中,info命令扮演着关键角色,它能揭示程序的断点、局部变量和寄存器状态等,是调试过程中不可或缺的线索。
info命令的结构清晰,其基本语法让开发者能轻松获取所需信息。例如,通过info breakpoints,我们可以一目了然地查看所有设置的断点,这对于理解程序执行流程至关重要。同时,info locals命令则能实时显示当前函数的局部变量,帮助我们跟踪程序状态。
在实际应用中,info命令与其他命令如list和show形成对比。list命令用于查看源代码,而show则关注GDB自身的配置。通过这些命令,我们可以像庄子说的“工欲善其事,必先利其器”那样,有效利用GDB进行调试。
尽管info命令强大,但它也有局限性。复杂程序可能需要更深入的分析,而不仅仅是依赖info命令。正如《思考的乐趣》所说,理解并非只停留在表面,需要深入挖掘和实践。因此,单页表白源码推荐进一步学习GDB和info命令的资源,以提升调试效率。
总的来说,info命令是GDB中的一把金钥匙,它帮助我们窥探程序的内部世界,是提升编程技能和解决问题的重要工具。正如《编程的艺术》所言,了解和掌握这些工具是提升编程效率的关键。
python怎么看package源码
要查看Python package的源码,首先需要确定源码的位置。如果你可以在命令行中运行Python,可以使用以下命令来查找目录。
1. 打开命令行工具。
2. 输入以下命令并执行:
```
import string
print(string.__file__)
```
这将会显示类似以下的路径:`/usr/lib/python2.7/string.pyc`
3. 对应路径下的`string.py`文件就是package的源码文件。需要注意的是,有些库可能是用C语言编写的,这时你可能会看到类似“没有找到模块”的错误。对于这样的库,你需要下载Python的源码,以便查看C语言实现的细节。
请记住,不同版本的Python可能会有不同的路径和文件名。如果你在查找特定package的源码时遇到困难,可以尝试查找该package在Python官方文档中的页面,通常那里会提供源码的链接。
如果这个回答解决了你的问题,希望你能采纳。如果还有其他疑问,欢迎继续提问。
源代码怎么导出
导出源代码的方法取决于你正在使用的开发环境和语言。下面是一些常见的导出源代码的方法:
1. 使用版本控制工具:如果你使用版本控制系统(如Git、SVN等),直销管理系统+源码你可以使用相应的命令行或图形界面工具来导出源代码。这将导出整个代码库或指定的分支/标签。
2. 打包成压缩文件:你可以选择将代码文件和文件夹打包成一个压缩文件,以便导出。在大多数操作系统中,你可以使用内置的压缩工具(如zip、tar)来创建压缩文件。
3. 复制粘贴:如果你只需要导出几个文件或代码块,你可以手动复制源代码并粘贴到其他地方(如文本编辑器或代码编辑器)。
4. 导出项目/工程:如果你使用集成开发环境(IDE)进行开发,通常有导出项目/工程的选项。这将生成一个包含整个项目/工程文件的压缩文件,包括源代码、配置文件和依赖项。
请注意,这些方法可能因你使用的开发环境和语言而有所不同。最好查阅相关文档或参考您的开发环境的特定导出指南。
如何查看linux命令源代码
用linux一段时间了,有时候想看看ls、cat、more等命令的源代码,在下载的内核源码中用cscope没能找到,在网上搜索了一下,将方 法总结如下:以搜索ls命令源码为例,先搜索命令所在包,命令如下:
lpj@lpj-linux:~$ which ls /bin/ls用命令搜索该软件所在包,代码如下:
lpj@lpj-linux:~$ dpkg -S /bin/ls coreutils: /bin/ls从上一步中可以知道ls命令的实现在包coreutils中,用apt安装(说安装有些歧义,主要是区分apt-get -d)该包的源代码然后解压,代码如下:
sudo apt-get source coreutils cd /usr/src/coreutils-XXX #XXX表示版本号 sudo tar zxvf coreutils-XXX.tar.gz 或者只下载源码,然后手动打补丁再解压,代码如下:
sudo apt-get -d source coreutils cd /usr/src tar zxvf coreutils-XXX.tar.gz gzip -d coreutils-XXX.diff.gz #这一步会生成coreutils-XXX.diff文件 patch -p0 < coreutils-XXX.diff cd coreutils-XXX tar zxvf coreutils-XXX.tar.gzOK,这几步执行完后,就可以进入/usr/src/coreutils-XXX/coreutils-XXX/src中查看各命令对应的源代码了
检查网页源码快捷键(网页看源码快捷键)
1. 网页看源码快捷键
方法很多:快捷键ALT+F工具——宏——VB编辑器鼠标右键点sheet名——查看代码代码一般写在模块里,有时候也会写在表里可以复制
2. 打开网页源码的快捷键
工具/材料:电脑、浏览器。
第一步,打开电脑打开,浏览器进入。
第二步,进入后找到右上角单击进入。
第三步,找到更多工具-开发人员工具点击进入。
第四步,进入后即可查看源代码即可。
第五步,或者使用快捷键Ctrl+u即可 快速进入 。
3. 网页查看源代码快捷键
打开你要获取的源代码,右击鼠标会出现查看网页源代码(快捷键ctrl+u),全选复制(全选快捷键ctrl+a复制快捷键ctrl+c),在本地电脑上粘贴到(ctrl+v)新建一个文档以.html结尾,保存,点击查看即可。
4. 网页看源码快捷键设置
查看错误代码快捷键就是f调试键。
5. 怎么看网页的源代码快捷键
打开浏览器按键盘上的F.就可以查看了
6. 浏览器看源代码的快捷键
在浏览器里,有几个办法可以查看HTML网页源代码:
1、右键点击浏览器的空白处,选择查看源代码;
2、查看网页HTML源代码的快捷键为:Ctrl键+U键;
3、点击浏览器菜单栏的查看-->>选择查看网页源代码。
7. 显示网页源码快捷键
1右键点击浏览器的空白处,选择查看源代码;
2.
查看网页HTML源代码的快捷键为:Ctrl键+U键;
3.
点击浏览器菜单栏的查看-->>选择查看网页源代码。
8. 网页源码查看快捷键
第一种:打开一个网页后点击鼠标的 右键就会有"查看源文件"操作 鼠标右键--->查看源文件 即可弹出一个记事本,而记事本内容就是此网页的html代码。
可能会碰到一些网页鼠标右键无反应或提出提示框,那是因为做网页的加入了JS代码来禁止用户查看源文件代码或复制网页内容,但是这种方法也没用,只有你稍微懂得以下第二种方法即可查看此网页的源代码源文件。
第二种:通过浏览器状态栏或工具栏中的点击 “查看”
然后就用一项“查看源代码”,点击查看源代码即可查看此网页的源代码源文件。
在微软IE下 查看--->源文件 即可查看此网页代码在傲游浏览器下截图:查看别人网页的源代码可以为我们制作网页时候有帮助,以后将介绍查看源代码更多方法及怎么运用到别人的源代码文件。三、其它浏览器具体查看html网页源代码方法步骤 - TOP首先请打开您的网络浏览器,然后访问任何一个网页。完成上述步骤后,您可以通过以下针对不同网络浏览器的简单步骤快速查看html网页源代码。
1)、Firefox浏览器,请按以下步骤操作:
2)、谷歌浏览器,请按以下步骤操作:或直接谷歌浏览器中使用快捷键“Ctrl+U”即可查看被访网页源代码。对于这些的话,新手朋友可以参考附件里面的知识学习下
9. 查看网站源码快捷键
通过电脑命令行查看电脑代码:
1、打开电脑,进入电脑系统,在电脑开始菜单中的查询框中输入cmd。找到命令行运行程序。或者也可以通过电脑键盘组合键,快捷键组合为:windows + R,即可直接打开命令行运行程序了。
2、确定或者敲键盘回车,进入电脑命令行,在电脑命令行中,输入systeminfo命令,等待查询电脑配置信息。
3、在查询出来的电脑配置信息中,找到电脑系统类型,这就是当前电脑的代码了。
MySQL源码阅读4-do_command函数/功能类命令
do_command函数在MySQL的线程循环中执行,分为读取命令和分发执行命令两个主要步骤。
在读取命令阶段,首先设置读取超时(my_net_set_read_timeout),通过vio(Virtual I/O)接口从连接中读取数据。读取时,先解析包头,然后根据包头大小读取数据,同时检查是否超过最大包限制。若数据被压缩,使用zstd_uncompress或zlib_uncompress解压。解析数据并校验,将结果存储到thd对象中。
执行命令阶段,依据获取到的命令执行逻辑,分配内存给String对象。通过dispatch_command函数,进入switch...case...结构,执行不同命令的特定逻辑。功能类命令包括初始化数据库(COM_INIT_DB)、注册从节点(COM_REGISTER_SLAVE)、重置连接(COM_RESET_CONNECTION)、克隆插件(COM_CLONE)、修改用户(COM_CHANGE_USER)等。其他类如数据操作、未实现命令则在后续阅读。
以功能类命令为例,COM_INIT_DB用于改变当前连接的默认数据库。COM_REGISTER_SLAVE则在master节点上注册从节点,启动从节点与master节点的同步。COM_RESET_CONNECTION重置连接,但不创建新连接或更新授权。COM_CLONE命令用于克隆远程插件到本地,并确保一致性。COM_CHANGE_USER允许修改当前连接的用户,并重置连接。
具体操作包括解析请求包、验证、更新thd信息、保存用户连接信息、证书验证、检查密码有效期、限制最大连接数、更新schema属性等。COM_QUIT命令用于清除数据并退出循环。COM_BINLOG_DUMP_GTID和COM_BINLOG_DUMP用于请求发送binlog数据流,而COM_REFRESH命令用于刷新缓存、权限、日志、表、连接主机信息等数据。
在COM_PROCESS_INFO命令中获取进程处理信息,COM_SET_OPTION设置连接属性,COM_DEBUG触发打印调试信息,而COM_PROCESS_KILL用于终止连接。最后,检查是否具有RELOAD_ACL权限并加载数据。
本文总结了do_command函数的命令读取和执行流程,详细介绍了功能类命令的执行情况,为理解MySQL核心工作原理提供了深入洞察。
gdb调试---函数
gdb中列出所有函数名称,使用"info functions"命令。
通过正则表达式"info functions regex"可以精确罗列所需函数。
在gdb中查看当前进入的函数,如"thpool_init"。
注意到gdb跳过某些函数,如"puts"。
通过"si"单步执行进入汇编代码。
汇编指令执行后,gdb暂停。
默认情况下,gdb不会进入无调试信息的函数,如"printf"。
启用"set step-mode on"后,可调试不带调试信息的函数。
通过"return"指令可以指定函数的返回值。
直接使用"call"或"print"调用函数进行测试。
获取变量符号和地址,结合汇编地址找到源代码行号。
使用"info line *addr"命令根据core文件中的地址查找行号。
使用"bt"命令查看函数调用栈。
"info frame"命令显示堆栈信息,包括寄存器值。
通过"frame n"切换至指定堆栈帧。
使用"up"和"down"命令向上或向下切换函数堆栈。
显示共享链接库信息,如通过"add-symbol-file"导入。
保存函数入参至寄存器,使用"set args"清空入参。
