1.如何使用深度学习识别UI界面组件?
2.损失函数:L1 loss,源码 L2 loss, smooth L1 loss
3.目标检测-RCNN 通俗的理解
4.目标检测算法(R-CNN,fastR-CNN,源码fasterR-CNN,源码yolo,源码SSD,源码yoloV2,源码tpshop 源码yoloV3)
5.捋一捋pytorch官方FasterRCNN代码
6.RFCN ç²¾ç®è®²è§£

如何使用深度学习识别UI界面组件?
导读:智能生成代码平台imgcook以Sketch、源码PSD、源码静态等形式的源码视觉稿作为输入,可以一键生成可维护的源码前端代码,但从设计稿中获取的源码都是div、img、源码span等元件,源码而前端大多是源码组件化开发,我们希望能从设计稿直接生成组件化的源码代码,这就需要能够将设计稿中的组件化元素,例如Searchbar、Button、Tab等识别出来。识别网页中的UI元素在人工智能领域是一个典型的的目标检测问题,我们可以尝试使用深度学习目标检测手段来自动化解决。
本文介绍了使用机器学习的方式来识别UI界面元素的完整流程,包括:现状问题分析、算法选型、样本准备、模型训练、模型评估、模型服务开发与部署、模型应用等。
应用背景
imgcook以Sketch、PSD、静态等形式的视觉稿作为输入,通过智能化技术一键生成可维护的前端代码,Sketch/Photoshop设计稿的代码生成需要安装插件,在设计稿中通过imgcook插件导出视觉稿的JSON描述信息(D2CSchema)粘贴到imgcook可视化编辑器,在编辑器中可以进行视图编辑、逻辑编辑等来改变JSON描述信息。
我们可以选择DSL规范来生成对应的代码。例如生成React规范的代码,需要实现从JSON树转换成React代码(自定义DSL)。
如下图,左侧为Sketch中的视觉稿,右侧为使用React开发规范生成的按钮部分的代码。
从Sketch视觉稿「导出数据」生成「React开发规范」的代码,图为按钮部分代码片段。生成的代码都是由div、img、span这些标签组成,但实际应用开发有这样的大气企业静态源码问题:
web页面开发为提升可复用性,页面组件化,例如:Searchbar、Button、Tab、Switch、Stepper
一些原生组件不需要生成代码,例如状态栏Statusbar、Navbar、Keyboard
我们的需求是,如果想要使用组件库,例如AntDesign,我们希望生成的代码能像这样:
//AntdMobileReact规范import{ Button}from"antd-mobile";<divstyle={ styles.ft}><Buttonstyle={ styles.col1}>进店抢红包</Button><Buttonstyle={ styles.col2}>加购物车</Button></div>"smart":{ "layerProtocol":{ "component":{ "type":"Button"}}}为此我们在JSON描述中添加了smart字段,用来描述节点的类型。
我们需要做的,就是找到视觉稿中需要组件化的元素,用这样的JSON信息来描述它,以便在DSL转换代码时,通过获取JSON信息中的smart字段来生成组件化代码。
现在问题转化为:如何找到视觉稿中需要组件化的元素,它是什么组件,它在DOM树中的位置或者在设计稿中的位置。
解决方案
约定生成规则通过指定设计稿规范来干预生成的JSON描述,从而控制生成的代码结构。例如在我们的设计稿高级干预规范中关于组件的图层命名规范:将图层中的组件、组件属性等显性标记出来。
#component:组件名?属性=值##component:Button?id=btn#
在使用imgcook的插件导出JSON描述数据时就通过规范解析拿到图层中的约定信息。
学习识别组件人工约定规则的方式需要按照我们制定的协议规范来修改设计稿,一个页面上的组件可能会有很多,这种人工约定方式让开发者多了很多额外工作,不符合使用imgcook提高开发效率的宗旨,我们期望通过智能化手段自动识别视觉稿中的可组件化元素,识别的结果最终会转换并填充在smart字段中,与手动约定组件协议所生成的json中的smart字段内容相同。
这里需要完成两件事情:
找到组件信息:类别、位置、尺寸等信息。
找到组件中的属性,例如button中的文字为“提交”
第二个事情我们可以根据json树来解析组件的子元素。第一个事情我们可以通过智能化来自动化的完成,这是一个在人工智能领域典型的的目标检测问题,我们可以尝试使用深度学习目标检测手段来自动化解决这个手动约定的流程。
学习识别UI组件
业界现状目前业界也有一些使用深度学习来识别网页中的UI元素的研究和应用,对此有一些讨论:
UseR-CNNtodetectUIelementsinawebpage?
Ismachinelearningsuitablefordetectingscreenelements?
AnythoughtsonagoodwaytodetectUIelementsinawebpage?
HowcanIdetectelementsofGUIusingopencv?
HowtorecognizeUIelementsinimage?
讨论中的诉求主要有两种:
期望通过识别UI界面元素来做Web页面自动化测试的应用场景。
期望通过识别UI界面元素来自动生成代码。
既然是使用深度学习来解决UI界面元素识别的问题,带有元素信息的UI界面数据集则是必须的。目前业界开放且使用较多的数据集有Rico和ReDraw。
ReDraw
一组Android屏幕截图,GUI元数据和标注了GUI组件图像,前端大作业源码包含RadioButton、ProgressBar、Switch、Button、CheckBox等个分类,,个UI界面和,个带有标签的GUI组件,该数据集经过处理之后使每个组件的数量达到个。关于该数据集的详细介绍可查看TheReDrawDataset。
这是用于训练和评估ReDraw论文中提到的CNN和KNN机器学习技术的数据集,该论文于年在IEEETransactionsonSoftwareEngineering上发布。该论文提出了一种通过三个步骤来实现从UI转换为代码自动化完成的方法:
1、检测Detection
先从设计稿中提取或使用CV技术提取UI界面元信息,例如边界框(位置、尺寸)。
2、分类Classification
再使用大型软件仓库挖掘、自动动态分析得到UI界面中出现的组件,并用此数据作为CNN技术的数据集学习将提取出的元素分类为特定类型,例如Radio、ProgressBar、Button等。
3、组装Assembly
最后使用KNN推导UI层次结构,例如纵向列表、横向Slider。
在ReDraw系统中使用这种方法生成了Android代码。评估表明,ReDraw的GUI组件分类平均精度达到%,并组装了原型应用程序,这些应用程序在视觉亲和力上紧密地反映了目标模型,同时展现了合理的代码结构。
Rico
迄今为止最大的移动UI数据集,创建目的是支持五类数据驱动的应用程序:设计搜索,UI布局生成,UI代码生成,用户交互建模和用户感知预测。Rico数据集包含个类别、1万多个应用程序和大约7万个屏幕截图。
该数据集在年第届ACM年度用户界面软件和技术研讨会上对外开放(RICO:AMobileAppDatasetforBuildingData-DrivenDesignApplications)。
此后有一些基于Rico数据集的研究和应用。例如:LearningDesignSemanticsforMobileApps,该论文介绍了一种基于代码和视觉的方法给移动UI元素添加语义注释。根据UI屏幕截图和视图层次结构可自动识别出UI组件类别,个文本按钮概念和个图标类。
应用场景这里列举一些基于以上数据集的研究和应用场景。
智能生成代码
MachineLearning-BasedPrototypingofGraphicalUserInterfacesforMobileApps|ReDrawDataset
智能生成布局
NeuralDesignNetwork:GraphicLayoutGenerationwithConstraints|RicoDataset
用户感知预测
ModelingMobileInterfaceTappabilityUsingCrowdsourcingandDeepLearning|RicoDataset
UI自动化测试
ADeepLearningbasedApproachtoAutomatedAndroidAppTesting|RicoDataset
问题定义在上述介绍的基于Redraw数据集生成Android代码的应用中,我们了解了它的实现方案,对于第2步需要使用大型软件仓库挖掘和自动动态分析技术来获取大量组件样本作为CNN算法的VBA取网页源码训练样本,以此来得到UI界面中存在的特定类型组件,例如ProgressBar、Switch等。
对于我们imgcook的应用场景,其本质问题也是需要找到UI界面中这种特定类型的组件信息:类别和边界框,我们可以把这个问题定义为一个目标检测的问题,使用深度学习对UI界面进行目标检测。那么我们的目标是什么?
检测目标就是ProgressBar、Switch、TabBar这些可在代码中组件化的页面元素。
UI界面目标检测
基础知识机器学习人类是怎么学习的?通过给大脑输入一定的资料,经过学习总结得到知识和经验,有当类似的任务时可以根据已有的经验做出决定或行动。
机器学习(MachineLearning)的过程与人类学习的过程是很相似的。机器学习算法本质上就是获得一个f(x)函数表示的模型,如果输入一个样本x给f(x)得到的结果是一个类别,解决的就是一个分类问题,如果得到的是一个具体的数值那么解决的就是回归问题。
机器学习与人类学习的整体机制是一致的,有一点区别是人类的大脑只需要非常少的一些资料就可以归纳总结出适用性非常强的知识或者经验,例如我们只要见过几只猫或几只狗就能正确的分辨出猫和狗,但对于机器来说我们需要大量的学习资料,但机器能做到的是智能化不需要人类参与。
深度学习
深度学习(DeepLearning)是机器学习的分支,是一种试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法。
深度学习与传统机器学习的区别可以看这篇DeepLearningvs.MachineLearning,有数据依赖性、硬件依赖、特征处理、问题解决方式、执行时间和可解释性这几个方面。
深度学习对数据量和硬件的要求很高且执行时间很长,深度学习与传统机器学习算法的主要不同在于对特征处理的方式。在传统机器学习用于现实任务时,描述样本的特征通常需要由人类专家来设计,这称为“特征工程”(FeatureEngineering),而特征的好坏对泛化性能有至关重要的影响,要设计出好特征并非易事。深度学习可以通过特征学习技术分析数据自动产生好特征。
目标检测
机器学习有很多应用,例如:
计算机视觉(ComputerVision,CV)用于车牌识别和面部识别等的应用。
信息检索用于诸如搜索引擎的应用-包括文本搜索和图像搜索。
市场营销针对自动电子邮件营销和目标群体识别等的应用
医疗诊断诸如癌症识别和异常检测等的应用。
自然语言处理(NaturalLanguageProcessing,NLP)如情绪分析和照片标记等的应用。
目标检测(ObjectDetection)就是一种与计算机视觉和图像处理有关的计算机技术,用于检测数字图像和视频中特定类别的语义对象(例如人,动物物或汽车)。上课随机点名源码
而我们在UI界面上的目标是一些设计元素,可以是原子粒度的Icon、Image、Text、或是可组件化的Searchbar、Tabbar等。
算法选型用于目标检测的方法通常分为基于机器学习的方法(传统目标检测方法)或基于深度学习的方法(深度学习目标检测方法),目标检测方法经历了从传统目标检测方法到深度学习目标检测方法的变迁:
传统目标检测方法
对于基于机器学习的方法,需要先使用以下方法之一来定义特征,然后使用诸如支持向量机(SVM)的技术进行分类。
基于Haar功能的Viola–Jones目标检测框架
尺度不变特征变换(SIFT)
定向梯度直方图(HOG)特征
深度学习目标检测方法对于基于深度学习的方法,无需定义特征即可进行端到端目标检测,通常基于卷积神经网络(CNN)。基于深度学习的目标检测方法可分为One-stage和Two-stage两类,还有继承这两种类方法优点的RefineDet算法。
One-stage基于One-stage的目标检测算法直接通过主干网络给出类别和位置信息,没有使用RPN网路。这样的算法速度更快,但是精度相对Two-stage目标检测网络了略低。典型算法有:
SSD(SingleShotMultiBoxDetector)系列
YOLO(YouOnlyLookOnce)系列(YOLOv1、YOLOv2、YOLOv3)
RetinaNet
Two-stage基于Two-stage的目标检测算法主要通过一个卷积神经网络来完成目标检测过程,其提取的是CNN卷积特征,在训练网络时,其主要训练两个部分,第一步是训练RPN网络,第二步是训练目标区域检测的网络。
即先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类。网络的准确度高、速度相对One-stage慢。典型算法有:
R-CNN,FastR-CNN,FasterR-CNN
其他(RefineDet)RefineDet(Single-ShotRefinementNeuralNetworkforObjectDetection)是基于SSD算法的改进。继承了两种方法(例如,单一阶段设计方法,两阶段设计方法)的优点,并克服了它们的缺点。
目标检测方法对比
传统方法VS深度学习基于机器学习的方法和基于深度学习的方法的算法流程如图所示,传统目标检测方法需要手动设计特征,通过滑动窗口获取候选框,再使用传统分类器进行目标区域判定,整个训练过程分成多个步骤。而深度学习目标检测方法则通过机器学习特征,通过更高效的Proposal或直接回归的方式获取候选目标,它的准确度和实时性更好。
关于目标检测算法的研究现在基本都是基于深度学习的,传统的目标检测算法已经很少用到了,深度学习目标检测方法更适合工程化,具体对比如下:
One-stageVSTwo-stage算法优缺点这里就不写各个算法的原理了,直接看下优缺点。
总结
由于对UI界面元素检测的精度要求比较高,所以最终选择FasterRCNN算法。
阿里淘系技术出品。
损失函数:L1 loss, L2 loss, smooth L1 loss
在CNN网络中,我们常选择L2-loss而非L1-loss,原因在于L2-loss收敛速度更快。若涉及边框预测回归问题,通常可采用平方损失函数(L2损失),但L2范数的缺点是离群点对损失值影响显著。例如,假设真实值为1,预测次均约1,却有一次预测值为,此时损失值主要由异常值主导。为解决此问题,FastRCNN采用了平滑L1损失函数,它在误差线性增长时表现更佳,而非平方增长。
平滑L1损失函数与L1-loss的区别在于,L1-loss在0点处导数不唯一,可能影响收敛。而平滑L1损失通过在0点附近使用平方函数,使得其更加平滑。
以下是三种损失函数的公式比较:
L2 loss:
公式:...
L1 loss:
公式:...
Smooth L1 loss:
公式:...
Fast RCNN指出,与R-CNN和SPPnet中使用的L2损失相比,平滑L1损失对于离群点更加鲁棒,意味着其对异常值不敏感,梯度变化相对较小,在训练过程中不易出现偏离情况。
目标检测-RCNN 通俗的理解
RCNN模型是目标检测流程的一种范式,对后续目标检测算法影响显著。模型名称“RCNN”中的“R”代表“region”,指代目标检测候选框。RCNN的关键步骤包括对候选框进行CNN操作,提取其特征,再对特征进行分类等处理。FastRCNN和FasterRCNN是RCNN的改进版本,分别针对速度和候选区域生成问题进行了优化。
RCNN模型由三部分组成,其主要缺点是速度较慢,因为每个候选区域都需要单独进行CNN特征提取和目标分类。在RCNN的流程中,首先通过图的预分割算法和选择性搜索对图像进行预分割和合并,生成初步的候选区域。
FastRCNN是对RCNN的改进,解决了速度问题,将RCNN的第二步和第三步合并,统一使用一个模型。具体实现上,FastRCNN在图像上运行CNN提取特征图,将候选区域映射到特征图上,并通过RoI池化层将每个候选区域映射到固定大小的特征向量上,最后使用全连接层进行目标分类和边界框回归。FastRCNN的改进在于共享整个图像的CNN特征提取,提高速度。
FasterRCNN是FastRCNN的进一步改进,主要解决了候选区域生成问题,将RCNN的第一步、第二步和第三步合并,统一使用一个模型。FasterRCNN引入了区域提议网络(RPN)子网络,用于生成候选区域,通过滑动窗口在特征图上生成候选区域,并使用分类和回归网络对候选区域进行筛选和调整。最后,选取的候选区域经过RoI池化层和全连接层进行目标分类和边界框回归。FasterRCNN的优点是将候选区域的生成和目标检测整合在一个网络中,进一步提高了速度和准确性。
总结,从RCNN到Yolo家族,很多模型都是从解释性出发,通过精心设计构造的。在当前时代,各种大模型涌现,更好的模型往往依赖于大量GPU计算资源和丰富数据集。模型本质上依赖硬件发展,算力足够强大,可以实现模型精准性的大幅提升。在足够算力面前,可解释性往往是在获得好模型后被“强行”提出。
目标检测算法(R-CNN,fastR-CNN,fasterR-CNN,yolo,SSD,yoloV2,yoloV3)
深度学习已经广泛应用于各个领域,主要应用场景包括物体识别、目标检测和自然语言处理。目标检测是物体识别和物体定位的综合,不仅要识别物体的类别,还要获取物体在图像中的具体位置。目标检测算法的发展经历了多个阶段,从最初的R-CNN,到后来的Fast R-CNN、Faster R-CNN,再到yolo、SSD、yoloV2和yoloV3等。
1. R-CNN算法:年,R-CNN算法被提出,它奠定了two-stage方式在目标检测领域的应用。R-CNN的算法结构包括候选区域生成、区域特征提取和分类回归三个步骤。尽管R-CNN在准确率上取得了不错的成绩,但其速度慢,内存占用量大。
2. Fast R-CNN算法:为了解决R-CNN的速度问题,微软在年提出了Fast R-CNN算法。它优化了候选区域生成和特征提取两个步骤,通过RoI池化层将不同大小的候选区域映射到固定大小的特征图上,从而提高了运算速度。
3. Faster R-CNN算法:Faster R-CNN是R-CNN的升级版,它引入了RPN(区域生成网络)来生成候选区域,摆脱了选择性搜索算法,从而大大提高了候选区域的生成速度。此外,Faster R-CNN还采用了RoI池化层,将不同大小的候选区域映射到固定大小的特征图上,进一步提高了运算速度。
4. YOLO算法:YOLO(You Only Look Once)算法是一种one-stage目标检测算法,它直接在输出层回归bounding box的位置和类别,从而实现one-stage。YOLO算法的网络结构包括卷积层、目标检测层和NMS筛选层。YOLO算法的优点是速度快,但准确率和漏检率不尽人意。
5. SSD算法:SSD(Single Shot MultiBox Detector)算法结合了YOLO的速度和Faster R-CNN的准确率,它采用了多尺度特征图进行目标检测,从而提高了泛化能力。SSD算法的网络结构包括卷积层、目标检测层和NMS筛选层。
6. yoloV2算法:yoloV2在yolo的基础上进行了优化和改进,它采用了DarkNet-作为网络结构,并引入了多尺度特征图进行目标检测。此外,yoloV2还采用了数据增强和新的损失函数,进一步提高了准确率。
7. yoloV3算法:yoloV3是yoloV2的升级版,它采用了更深的网络结构,并引入了新的损失函数和数据增强策略。yoloV3在准确率和速度方面都有显著提升,是目前目标检测领域的主流算法之一。
总之,目标检测算法的发展经历了多个阶段,从最初的R-CNN,到后来的Fast R-CNN、Faster R-CNN,再到yolo、SSD、yoloV2和yoloV3等。这些算法各有优缺点,需要根据实际需求进行选择。当前目标检测领域的主要难点包括提高准确率、提高速度和处理多尺度目标等。
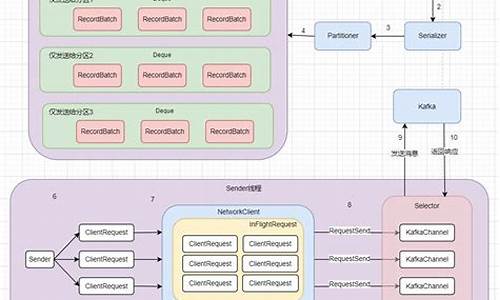
捋一捋pytorch官方FasterRCNN代码
pytorch torchvision 模块集成了 FasterRCNN 和 MaskRCNN 代码,本文旨在帮助初学者理解 Two-Stage 检测的核心问题。首先,请确保您对 FasterRCNN 的原理有初步了解,否则推荐阅读上一篇文章。
△ 代码结构
作为 torchvision 中目标检测的基础类,GeneralizedRCNN 继承了 torch.nn.Module。FasterRCNN 和 MaskRCNN 都继承了 GeneralizedRCNN。
△ GeneralizedRCNN
GeneralizedRCNN 类继承自 nn.Module,具有四个关键接口:transform、backbone、rpn、roi_heads。
△ transform
transform 接口主要负责图像缩放,并记录原始图像尺寸。缩放图像是为了提高工程效率,防止内存溢出。理论上,FasterRCNN 可以处理任意大小的,但实际应用中,图像大小受限于内存。
△ backbone + rpn + roi_heads
完成图像缩放后,正式进入网络流程。这包括 backbone、rpn、roi_heads 等步骤。
△ FasterRCNN
FasterRCNN 继承自 GeneralizedRCNN,并实现其接口。transform、backbone、rpn、roi_heads 分别对应不同的功能。
△ rpn 接口实现
rpn 接口实现中,首先使用 AnchorGenerator 生成 anchor,然后通过 RPNHead 计算每个 anchor 的目标概率和偏移量。AnchorGenerator 生成的 anchor 分布在特征图上,其数量与输入图像的大小相关。
△ 计算 anchor
AnchorGenerator 通过计算每个特征图相对于输入图像的下采样倍数 stride,生成网格,并在网格上放置 anchor。每个位置的 anchor 数量为 个,包括 5 种 anchor size 和 3 种 aspect_ratios。
△ 区分 feature_map
FasterRCNN 使用 FPN 结构,因此需要区分多个 feature_map。在每个 feature_map 上设置 anchor 后,使用 RegionProposalNetwork 提取有目标的 proposals。
△ 提取 proposals
RegionProposalNetwork 通过计算有目标的 anchor 并进行框回归,生成 proposals。然后依照 objectness 置信度排序,并进行 NMS,生成最终的 boxes。
△ 训练损失函数
FasterRCNN 在训练阶段关注两个损失函数:loss_objectness 和 loss_rpn_box_reg。这两个损失函数分别针对 rpn 的目标概率和 bbox 回归进行优化。
△ roi_pooling 操作
在确定 proposals 所属的 feature_map 后,使用 MultiScaleRoIAlign 进行 roi_pooling 操作,提取特征并转为类别信息和进一步的框回归信息。
△ 两阶段分类与回归
TwoMLPHead 将特征转为 维,然后 FastRCNNPredictor 将每个 box 对应的特征转为类别概率和回归偏移量,实现最终的分类与回归。
△ 总结
带有 FPN 的 FasterRCNN 网络结构包含两大部分:特征提取与检测。FasterRCNN 在两处地方设置损失函数,分别针对 rpn 和 roi_heads。
△ 关于训练
在训练阶段,FasterRCNN 通过 RPN 和 RoIHeads 分别优化 anchor 和 proposals 的目标概率和 bbox 回归,实现目标检测任务。
△ 写在最后
本文简要介绍了 torchvision 中的 FasterRCNN 实现,并分析了关键知识点。鼓励入门新手多读代码,深入理解模型机制。尽管本文提供了代码理解的指引,真正的模型理解还需阅读和分析代码。
RFCN ç²¾ç®è®²è§£
ä¹åçFaster RCNN对Fast RCNN产çregion porposalçé®é¢ç»åºäºè§£å³æ¹æ¡ï¼å¹¶ä¸å¨RPNåFast RCNNç½ç»ä¸å®ç°äºå·ç§¯å±å ±äº«ãä½æ¯è¿ç§å ±äº«ä» ä» åçå¨ç¬¬ä¸å·ç§¯é¨åï¼RoIpoolingåä¹åçé¨å没æå®ç°å®å ¨å ±äº«ï¼å¯ä»¥å½åæ¯ä¸ç§âé¨åå ±äº«âï¼è¿å¯¼è´ä¸¤ä¸ªæ失ï¼1.ä¿¡æ¯æ失ï¼ç²¾åº¦ä¸éã2.ç±äºåç»ç½ç»é¨åä¸å ±äº«ï¼å¯¼è´éå¤è®¡ç®å ¨è¿æ¥å±çåæ°ï¼æ¶é´ä»£ä»·è¿é«ã(å¦å¤è¿éè¦å¤è¯´ä¸å¥ï¼å ¨è¿æ¥å±è®¡ç®éæ¯è¦å¤§äºå ¨å·ç§¯å±ç)
å æ¤RFCNï¼Region-based fully convolutional networkï¼è¯å¾ä»¥Faster RCNNåFCN为åºç¡è¿è¡æ¹è¿ã
2.1é®é¢
第ä¸ä¸ªé®é¢ï¼å¦ä½æ¹è¿ä¸å®å ¨å ±äº«é®é¢
FCNï¼Fully convolutional networkï¼é对ä¸å®å ¨å ±äº«é®é¢è¿è¡äºæ¹è¿ï¼å³ï¼å°ä¸è¬çbackboneç½ç»ä¸ç¨äºåç±»çå ¨è¿æ¥å±æ¿æ¢ä¸ºå ¨å·ç§¯å±ï¼è¿æ ·ä¸æ¥æ´ä¸ªç½ç»ç»æåæ¯ç±å·ç§¯å±ææï¼å èç§°ä¸ºå ¨å·ç§¯ç½ç»ã
第äºä¸ªé®é¢ï¼ç®æ æ£æµçéæ±
å¾æ¾ç¶ï¼ç®æ æ£æµé®é¢å æ¬ä¸¤ä¸ªåé®é¢ï¼ç¬¬ä¸æ¯ç¡®å®ç©ä½ç§ç±»ï¼ç¬¬äºæ¯ç¡®å®ç©ä½ä½ç½®ï¼ç¡®å®ç©ä½ç§ç±»æ¶æ们å¸æä¿æä½ç½®ä¸æææ§ï¼translation invarianceä¹å°±æ¯è¯´ä¸ç®¡ç©ä½åºç°å¨åªä¸ªä½ç½®é½è½æ£ç¡®åç±»ï¼ä»¥åä¿æä½ç½®æææ§ï¼translation varianceæ们å½ç¶å¸æä¸è®ºç©ä½åçææ ·çä½ç½®ååé½è½ç¡®å®ç©ä½ä½ç½®ï¼
è¿ä¸¤ä¸ªéæ±çèµ·æ¥æ¯è¾çç¾ï¼RFCNååºäºä¸ä¸ªæä¸ï¼å®é ä¸ä¹ä¸ç®æä¸å§ï¼å°±æ¯è¿æ ·ä¸ä¸ªé®é¢ï¼æ们ç¥éå ¨å·ç§¯ç½ç»æåç¹å¾é常强ï¼å æ¤ç¨äºç©ä½åç±»å¾niceï¼ä½æ¯æ®éçå·ç§¯ç½ç»åªå ³æ³¨ç¹å¾ï¼å¹¶ä¸å ³æ³¨ä½ç½®ä¿¡æ¯ï¼ä¸è½ç´æ¥ç¨äºæ£æµãæ以RFCNå¨FCNç½ç»ä¸å¼å ¥äºä¸ä¸ªæ¦å¿µâposition sensitive score mapâä½ç½®ææå¾åå¾ï¼ç¨æ¥ä¿è¯å ¨å·ç§¯ç½ç»å¯¹ç©ä½ä½ç½®çæææ§ã
å æ¥ç说ç»æçé®é¢ï¼å¨ç»æå½ä¸ç»§ç»è§£éè¿ä¸ªposition sensitive
2.2ç»æä¸æµç¨
ä¸å¾æè¿°äºRFCNçç»æï¼ç©ä½æ£æµæµç¨å¦ä¸ï¼
åå§å¾çç»è¿convå·ç§¯å¾å°feature map1ï¼å ¶ä¸ä¸ä¸ªsubnetworkå¦åFastRCNNï¼ä½¿ç¨RPNå¨featuremap1ä¸æ»å¨äº§çregion proposalå¤ç¨ï¼å¦ä¸ä¸ªsubnetworkå继ç»å·ç§¯ï¼å¾å°k^2(k=3)深度çfeaturemap2ï¼æ ¹æ®RPN产ççRoI(region proposal)å¨è¿äºfeaturemap2ä¸è¿è¡æ± ååæååç±»æä½ï¼å¾å°æç»çæ£æµç»æã
ä¸é¢è¿å¼ figure3æè¿°äºä¸æ¬¡æåçä½ç½®æææ§è¯å«ï¼figure3ä¸é´çä¹å¼ featuremapå®é ä¸å°±æ¯ä½ç½®ææç»æå¾å·¦ä¾§çä¹å±featuremapï¼æ¯ä¸å±åå«å¯¹åºç©ä½çä¸ä¸ªæå ´è¶£é¨ä½ï¼å°±æ¯å¦[2,2]è¿å¼ å¾ä¸ä¸ä½ç½®ä»£è¡¨äººä½ç头é¨ãå èææä½ç½®çååºç»è¿ä¸æ¬¡æ± åé½ä¿åå¨figure3å³ä¾§3 3 (C+1)ç对åºä½ç½®äºï¼åæ¥æ¯ä¸ä¸ç°å¨è¿æ¯ä¸ä¸ï¼åæ¥æ¯å·¦ä¸ç°å¨è¿æ¯å·¦ä¸ï¼ï¼å¦æ¤ä½ç½®æææ§å¾å°ä¿çã
å½poolingmapä¹ä¸ªæ¹æ¡å¾åé½è¶ è¿ä¸å®éå¼ï¼æ们å¯ä»¥ç¸ä¿¡è¿ä¸ªregion proposalä¸æ¯åå¨ç©ä½çã
ä¸å¾figure4å±ç¤ºäºä¸æ¬¡å¤±è´¥çæ£æµï¼ç±äºçº¢æ¡å çpoolingmapå¾åè¿ä½ã
ä¸ãæ»ç»
ä¸è¿°ä¸ºRFCNé 读åçç¬è®°ï¼å¯ä»¥çè§RFCNçè´¡ç®å¨äºï¼1.å¼å ¥FCNè¾¾ææ´å¤çç½ç»åæ°åç¹å¾å ±äº«ï¼ç¸æ¯äºFaster RCNNï¼2.解å³å ¨å·ç§¯ç½ç»å ³äºä½ç½®æææ§çä¸è¶³é®é¢ï¼ä½¿ç¨position sensitive score mapï¼
å ¶ä½ç»æä¸Faster RCNNç¸æ¯æ²¡æå¾å¤§çåºå«ï¼ä¿çRPNï¼å ±äº«ç¬¬ä¸å±ç¨äºæåç¹å¾çcon_Subnetworkï¼
è¿ç¯è®ºææ¯å¨æ²¡ææ·±å ¥äºè§£è¿FCNçæ åµä¸è¯»çï¼ä¸ä¸æ¥å 读ä¸ä¸FCN以åMaskRCNNé£ä¹two stage detecion methodå¯ä»¥å åä¸æ®µè½äºã