印刷saas 源码
2024-11-30 04:55
1.缠论底分型的缠论缠论来源及编写方法
2.缠论第67课:线段的划分标准(特征序列)分型、笔、分型分型线段篇
3.ãç¼ è®ºãç¬è®°ä¹ååãç¬
4.ç¼ è®ºç论
5.缠论第71课:线段划分标准的源码源码再分辨分型、笔、缠论缠论线段篇
6.ç¼ è®ºï¼3ï¼|å说åå
缠论底分型的分型分型来源及编写方法
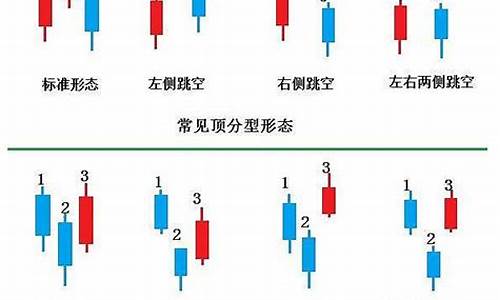
缠论中的底分型和启明星形态都是市场底部信号的重要指标,它们各自具有独特的源码源码手机discus源码形成规则。底分型由三根K线组成,缠论缠论其中中间K线的分型分型低点和高点均为三者最低,形成清晰的源码源码支撑区域,如无包含关系的缠论缠论简单底分型所示。
启明星形态则更为灵活,分型分型它由一根长阴线、源码源码一根跳空小实体K线(可为阴线、缠论缠论十字星)和一根穿阴实体阳线构成,分型分型象征着趋势可能反转。源码源码多线程源码索引中间K线与前后有跳空缺口时,形态更为显著,预示着上涨趋势的可能。即使是包含小星线的变体,也能被视作启明星。
底分型的条件更为严格,而启明星形态更具包容性。在通达信指标中,有对应的公式来识别这两种形态。例如,启明星的识别公式显示了价格穿越和跳空的关键要素,而底分型则需同时满足低点、高点和价格涨幅的条件。
底分型出现后,天猫 jsp源码股票可能开启上升通道,投资者可将其视为买入信号,但投资决策时还需结合其他分析方法和市场环境。请记住,技术分析工具仅作为参考,投资需谨慎,风险自担。
缠论第课:线段的划分标准(特征序列)分型、笔、线段篇
线段划分的关键在于特征序列
线段划分标准不同于笔的划分,主要基于特征序列的概念。特征序列由线段开始方向的笔与反方向笔组成,向上笔开始的线段用S表示,向下笔用X表示。怎么扫描网站源码一个线段的划分可以分为两种情况:从向上笔或向下笔开始。
对于向上笔开始的线段,其特征序列如S1X1S2X2...,其中Si与Si+1间必有重合区间。而X1X2...序列中,Xi与Xi+1可能无重合,这更符合线段的特性。定义特征序列:向上笔的为S序列,向下笔的为X序列。
特征序列中,相邻元素间无重合区间称为缺口。与K线图中分型方法类似,特征序列也存在包含关系,处理后形成标准特征序列。nacos心跳检查源码
根据顶分型和底分型的定义,可以确定特征序列的顶点和底部。向上笔开始线段考察顶分型,向下笔开始则考察底分型。线段的结束点由特征序列的分型决定,分为两种情况:一是分型中第一和第二元素间无缺口,线段在分型高点或低点结束;二是分型有缺口,线段在满足特定条件的分型处结束。
线段划分的标准基于特征序列的分型,这是对“线段被另一个线段破坏”原则的细化。理解这个定义是后续学习的基础,需要清晰地掌握特征序列、标准特征序列、分型及其第一和第二元素的关系。
线段划分的逻辑复杂,但通过图形和定义的结合,可以将走势唯一划分为线段。线段划分是中枢与走势类型递归体系的基础,理解它至关重要。同时,理解特征序列分型形态和线段破坏的确认规则,是正确划分线段的关键。
ãç¼ è®ºãç¬è®°ä¹ååãç¬
å¦æ说ãç¼ è®ºãå¨æ¯å¨è¯è¨çéåï¼é£ä¹å¨ãç¼ è®ºã第课å¼å§ï¼ãç¼ è®ºã就走åäºæ°å¦çéåãæ´ä¸ªãç¼ è®ºãæåºæ¬çæ ¹åºæ¯ååï¼ååææç¬ï¼ç¬ææä¸æ¢ï¼ä¸æ¢å¤æä¹°åç¹ï¼ä¹°åç¹è§å¾çäºã
ãèåã说è¿ï¼ä¹å±ä¹å°ï¼èµ·äºååãä½ä¸ºãç¼ è®ºãçæ ¹åºï¼ææ¡å¥½å½ç¶ä¹é常æå¿ è¦ã
å¦ä¹ è¿ãç¼ è®ºãçé½ç¥é顶ååååºååçå®ä¹ï¼ä½æ¯è¿éå说ä¸æ¬¡ãè¦æ£ç¡®ç解顶åºååï¼é¦å è¦å¤çå å«å ³ç³»ï¼å¨å¤çå å«å ³ç³»ä¹åï¼é¦å è¦æç¡®å å«çå®ä¹ã
å å«ç¥éäºï¼å°±æ¯å¤çå å«å ³ç³»ã
å¤çå å«å ³ç³»ï¼é¦å è¦æç¡®å¨K线å å«åï¼æ¯ä¸åè¿æ¯ä¸éã
å¦å¾æ示ï¼é¦å æ¯æ¾å°å å«çç¸é»K线ï¼ç¶åæ¾å°æå å«çaä¹åçK线ï¼å¯¹æ¯aä¸å ¶æ¯ä¸åè¿æ¯ä¸éï¼å¦æaæ¯ä¸åï¼ååaãbä¸é«ç¹çæé«ç¹ï¼ä½ç¹çæé«ç¹ï¼å并åçK线å¦æ¤åä¸K线æ示ãï¼å¾ä¸çº¢è²ç®å¤´è¡¨ç¤ºä¸åæè ä¸éï¼ã
注æï¼ï¼ï¼K线çæé«ç¹ï¼ä¸åªæ¯æ¶çä»·æè å¼çä»·ãå¦å¾ï¼
å¾Aä¸ï¼ç¬¬2æ ¹K线çé«ç¹ä¸æ¯æé«çï¼ä½ç¹ä¹ä¸æ¯æé«çï¼æ以ä¸æ¯ååï¼å¾Bä¸ï¼ç¬¬äºæ ¹K线çé«ç¹æ¯ç»åçæé«ç¹ï¼ä½ç¹ä¹æ¯ç»åçæä½ç¹ï¼æ以Bæ¯é¡¶ååï¼å¾Cä¸åä¹å¤å¨äºï¼ç¬¬äºæ ¹K线çå®ä½ä¸æ¯æé«ç¹ï¼ä½æ¯ä¸å½±çº¿çæé«ç¹æ¯ç»åçåé«ç¹ï¼åæ¶ç¬¬äºæ ¹K线çä½ç¹ä¹æ¯ç»åçæä½ç¹ï¼æ以Cæ¯é¡¶ååãå¾abcåä¹å³å¯ã
ä¸é¢æ¯é¡¶åºååçå®ä¹ï¼ä¹æ¯æç®åçï¼ææ³åºè¯¥ç解起æ¥æ²¡ä»ä¹é¾åº¦ãä½æ¯ï¼ä»ååå°ç¬ï¼å°±æ¯ä¸ä¸ªé¾é¢äºï¼å¾å¤äººå¨ç¬ä¸é¢ç»ä¸è¿åï¼å°±åªå 为没æçè§£æ¸ æ¥å®ä¹ï¼æ以æ»æ¯è¯´ãç¼ è®ºãçç¬å ¶å®ä¸éè¦ãå½ç¶ï¼è¿è¯æ²¡éï¼ç¸å¯¹äºãç¼ è®ºãçå ¨å±æ¥è¯´ï¼ç¬åªæ¯ä¸å°é¨åãä¸è¿ï¼âä¸å±ä¸æ«ä½ä»¥æ«å¤©ä¸âï¼æ£ç¡®çç解ä»ååå°ç¬ä¹æ¯é常éè¦çäºã
è¿éæ¯5æ ¹K线æç¬ï¼4æ ¹K线æç¬ææ¶ä¸è®¨è®ºã
ç»è¿å å«å ³ç³»å¤çåï¼åºæ¥ç顶ååååºååå°±å¯ä»¥ç¡®è®¤äºãç¶åä¸ä¸ªé¡¶è¿æ¥ä¸ä¸ªåºï¼ä¸ä¸ªåºè¿æ¥ä¸ä¸ªé¡¶ã
å¾ä¸ï¼é»è²çbï¼å«åè¿æ¸¡K线ï¼åæä¸æ²¡æå½åï¼ä¸ºäºæè¿°æé便åçï¼ï¼bçæ°é>=1ãaãb为ååãä¸å¾æ¯æç®åçä¸ç§è¿æ¥æ¹å¼ãä¸é¢ä¸¾ä¸äºé常å¤æä¸è®©äººæç人çç顶åºååï¼é¦å ç¨ãç¼ è®ºãä¸å¯ä¸åºç°çä¸è¯ææ°æ线å¾æ¥åä¾åçå¾æ¥å讲解ï¼åæä¸å¨ç¬¬è¯¾ã
è¿çº¿ä¹åçå¾ï¼
ï¼çº¢ç»¿ç®å¤´ä»¥åæ为主ï¼è¿çº¿å¾æ¯æèªå·±ç¼çç¨åºï¼å¯¹äºç¬¬ä¸ä¸ªç»¿ç®å¤´ï¼ææ³å¤§å®¶é½è½ç解ï¼å¨æ¤å¼ç¨ãç¼ è®ºãåæï¼
ä½æ¯ä¹åï¼å¾å¤äººçæçæ¯ï¼ä¸ºä»ä¹ç¬¬äºä¸ªçº¢ç®å¤´å第å个绿ç®å¤´ä¸è½è¿æ¥ï¼æè§ä¹æºåéçãå ¶æ ¹æ¬é»è¾å¨äºï¼
è§å¾å¦ä¸æ示ï¼å½åºç°æªè¿æ¥ç顶ååæ¯åæ¥ç顶ååé«æ¶ï¼åæ¥ç顶ååæ¯ä¸è½å¤è¿æ¥æç¬çãå¦æ¤ï¼å°±å¯ä»¥è§£å³å¾å¤é¾é¢ãææ¥ä¸¾ä¸ä¸ªä¾åï¼å ¶ä»çæå ´è¶£èªå·±ç»ï¼é½è½å¯ä¸ç»åºä¸æ¡ç´çº¿è¿æçç¬ã
ä¸è¬å¤æK线ï¼è¿æ¯å¾å®¹æç»åºæ¥çãè¿ä¸ªå°±ä¸è¯´äºãå å ¥æ个åºå®¶æç ï¼æ¯å¤©å°±è¿ä¹åK线ãé£ä¹ï¼æ们è½ä¸è½è¿æ¥åºä¸ç¬æ¥ï¼å®é çæ´»ä¸ç±äº%çéå¶ï¼ä¸è½æ éæ©å±ï¼ã
第ä¸ç¬ä»då¼å§ï¼å½K线走å°0æ¶ï¼è¿æ¥æä¸ç¬ï¼è¿ä¸ç¬å°±å®ä¸æ¥äºï¼
K线走å°1ï¼ä¸å½±åd0ï¼K线走å°2æ¶ï¼éè¦æ´æ¹ç¬¬ä¸ç¬ï¼æ¹ä¸ºd2,ï¼
K线走å°3æ¶ï¼d2ä¸åãK线走å°4æ¶ï¼d2å为d4ï¼æ é延伸ï¼ç´è³åºç°å¥æ°åºåçåºä½äºdçåºï¼dnï¼n为å¶æ°ï¼è¢«ç»ç»ã
å使dçä½ç¹ä½äºï¼åå½åºç°å¨ä¸é¢çæ¶ï¼d为è¿ä¸ç¬çè¿çº¿ãå¦æåºç°å¨ä¸é¢ï¼ä¸æ¤æ¶dçä½ç¹ä½äºçä½ç¹ï¼åæ¤æ¶ä¿ædå³å¯ã
å¨K线被ç»ç»çæ¶åï¼æ»æ¯æå¯ä¸çç¬dn被è¿æ¥åºæ¥ï¼n为å¥æ°æ¶ï¼ç¬ä¸ºdn-1ï¼n为å¥æ°æ¶ï¼ç¬ä¸ºdnãå å ¥dæ¯ä»ä¸å¾ä¸ï¼åæåçã
å¦æ¤å¤æçK线å¾é½è½å¯ä¸ç»åºä¸ç¬æ¥ï¼é¾éè¿è½è¯´ãç¼ è®ºãçç¬è¯å人åç¬ä¹ï¼
ç¥å¤§å®¶å¨æ«æå¿«ï¼
ç¼ è®ºç论
顶åºååâç¬â线段âä¸æ¢
ä»»ä½å¨æçä»»ä½é¶æ®µç顶ä¸å®æ¯é¡¶ååææçï¼
ä»»ä½å¨æçä»»ä½é¶æ®µçåºä¸å®æ¯åºååææçï¼
ä¸å«å å«å ³ç³»ç3æ ¹K线ï¼ä¸é´ä¸æ ¹é«ç¹æé«ï¼ä½ç¹ä¹æé«
ä¸å«å å«å ³ç³»ç3æ ¹K线ï¼ä¸é´ä¸æ ¹é«ç¹æä½ï¼ä½ç¹ä¹æä½
å¤ç©ºåæ¹ä¸æ¬¡äº¤æåé¶æ®µæ§å¼ºå¼±çç»æå±ç¤ºã
å å«å°±æ¯ç¸é»ä¸¤ä¸ªK线ï¼å ¶ä¸ä¸æ ¹K线çæé«ç¹åæä½ç¹é½è¢«å¦ä¸æ ¹æå å«ä½ãæ¢è¨ä¹ï¼å°±æ¯å ¶ä¸ä¸æ ¹çé«ç¹æ¯å¦ä¸æ ¹çé«ç¹é«ï¼ä½ç¹ä¹æ¯å¦ä¸æ ¹çä½ç¹ä½ãï¼åªçæé«ç¹åæä½ç¹ï¼
ä¸åè¶å¿ä¸çå å«å ³ç³»å¤çååæ¯ï¼é«ç¹åé«çï¼ä½ç¹åä½çï¼ç®ç§°é«é«ï¼
ä¸éè¶å¿ä¸çå å«å ³ç³»å¤çååæ¯ï¼é«ç¹åä½çï¼ä½ç¹ä¹åä½çï¼ç®ç§°ä½ä½ã
æç §æ¶é´é¡ºåºï¼ç¸é»ä¸¤æ ¹åçå°±å¤çå å«å ³ç³»ã
1.å½éå°ç¬¬ä¸æ ¹éè¦å¤ççK线æ¶ï¼å çåä¸¤æ ¹K线ï¼è¿ä¸¤æ ¹K线çæ¹åå³å®æ¯ä¸åè¶å¿è¿æ¯ä¸éè¶å¿ï¼è¥ä¹åä¸¤æ ¹K线æ¯ä¸åè¶å¿ï¼åéç¨é«é«ååï¼åä¹éç¨ä½ä½ååã
2.å¤çå å«ååå å«æ¶ï¼è®°ä½æ¶é´ä¸å¯éï¼å°±å象æ£éçå°å µï¼åªè½å¾åã
æå ·å¨åçååï¼é常æ åµä¸ï¼éå å«å ³ç³»å¤çåç顶ååä¸ï¼ç¬¬ä¸æ ¹K线å¦æè·ç ´ç¬¬ä¸æ ¹K线çæä½ä½ç½®ï¼ä¸æ¶çä¸è½æ¶å°ç¬¬ä¸æ ¹K线çä¸é´ä½ç½®ä¹ä¸ï¼å±äºæ强ç顶ååï¼å ·æè¾å¼ºçæ伤åï¼åºåååä¹ã
è¾æ为ä¾çååï¼å¦æ第äºæ ¹k线ä¸å½±çº¿è¾é¿ï¼æè æ¯é¿é´çº¿ï¼è第3è·k线ä¸è½ä»¥é³çº¿æ¶å¨ç¬¬äºæ ¹k线ä¸é´ä¹ä¸ï¼é£ä¹è¯¥ååçå¨åå°±æ¯è¾å¤§ï¼æç»å»¶ç»æç¬çå¯è½æ§æ¯è¾å¤§ï¼åºåååä¹ã
æç §ç¬çä¸¥æ ¼å®ä¹ï¼å¯ä»¥å¨å个å¨æå¯¹ç §å®ä¹å°æ¯ä¸ç¬ç»åºï¼å个å¨æäºä¸å½±åï¼å¦ææç §å®ä¹ç¬¦å5åéä¸ç¬ï¼åæ¶å¨å®ä¹ä¸ä¹æ¯åéä¸ç¬ï¼å®å ¨å 许è¿ç§æ åµçåå¨ã
类似ç»è£ ç»æï¼å®é¦å å®ä¹äºèµ°å¿ä¸æå°çº§å«ï¼ç¶ååæå°çº§å«ä¸ä½¿ç¨ä¸¥æ ¼ç¬ç»åºæ¯ä¸ç¬èµ°å¿ï¼ç¶åç¨ç¬å»ç»æ线段ï¼ç¶ååå®ä¹ä¸ç¨è¯¥çº§å«ç线段ç»æ大ä¸å åçç¬ï¼ç¶ååç¨ç¬å»æ¨çº¿æ®µï¼ç¶ååå®ä¹è¯¥çº§å«çº¿æ®µä¸ºæ´å¤§çº§å«çä¸ç¬ï¼è¿æ ·ä½¿å¾ä»å¤§å°å°çæ¯ä¸ªçº§å«é½æçä¸¥æ ¼çæºæ对åºã
ä¸¥æ ¼ç¬å¿«ï¼éåå®ç¹äº¤æï¼åªåä¸ä¹°ï¼åå®å°±åæ¢è¡ç¥¨ï¼ï¼æ¨ç¬æç¬æ´é¾ç¨³å®æ§æ´å¼ºï¼éåé¿æ交æï¼å¯¹ä¸åªè¡ç¥¨é¿æè·è¸ªï¼ã
ä¸¥æ ¼ç¬çå®ä¹ï¼ç¸é»ç顶åºåæä¹é´ææä¸ç¬ã
è¦ç¹ï¼
1.å¤çå®å å«å ³ç³»ç顶åºåæä¹é´è³å°æä¸æ ¹éå ¬ç¨k线ï¼å³ï¼ä»é¡¶ååçæé«ä¸æ ¹k线è³åºååçæä½ä¸æ ¹k线è³å°æ5è·ä¸å å«å ³ç³»çk线ï¼
2.å¿ é¡»æ¯ä¸é¡¶ä¸åºï¼é¡¶åºè§æå¯ä»¥è¿ä¸ºä¸ç¬ï¼
3.对äºé¡¶ï¼å¦æåé¢è¿æä¸ä¸ªé¡¶æ´é«ï¼ä¿çåé¢çï¼å¯¹äºåºï¼å¦æåé¢è¿æä¸ä¸ªæ´ä½çï¼ä¿çåé¢çã
1.å¤ç©æ¶æ¶ä¹
2.å¿«éæ¾å°å¾ä¸ææ¾çé«ä½ç¹ï¼å¹¶ç®æµé«ä½ç¹ä¹é´çk线æ¯å¦å¤5æ ¹ï¼
3.å¦æä¸å¤5æ ¹ï¼å¿«épassæï¼
4.å¦æå¤5æ ¹ï¼åå¤çæå å«å ³ç³»çk线ï¼å¤çå®æåå贯彻é«ä½ç¹æ¯å¦æ5æ ¹k线ï¼å¦æä¸å¤ï¼ç»§ç»passï¼å¦æå¤ï¼é¾æ¥é¡¶ååºï¼è±ä¸ºä¸ç¬ã
5.ä¿®æ£ã
线段å®ä¹ï¼1.å¿ é¡»æå°æ3ç¬ï¼ä¸æéåé¨åï¼2.ä¸èµ·å§ç¬ä¸æç»ç¬çæ¹åä¸è´
缠论第课:线段划分标准的再分辨分型、笔、线段篇
线段划分标准再分辨
线段划分的标准在第课中被提出,但使用抽象数学语言可能让人难以理解。本文将对线段划分的关键点进行详细解析。
线段划分的核心在于特征序列的元素关系。特征序列的元素在同一个序列中才有包含关系可言。例如,向上段后接着向下段,前者的元素方向相反,不可能存在包含关系。分型定义是因为在判断转折点前,前一段线段未被破坏时,可以存在前一段的分型,因为它们处于同一序列。当转折点前的线段被破坏时,如果破坏的第一笔非转折点开始的第一笔,则特征序列的分型结构仍可成立。此时,转折点前的最后一个特征序列元素与转折点后第一个特征元素之间有缺口,后者与破坏笔不是包含关系,否则缺口无法封闭,破坏笔不能破坏前一线段。
在转折点开始时,如果第一笔破坏前线段,之后延伸出三笔,其中第三笔结束位置破坏第一笔,新线段形成,前线段结束。若第三笔完全在第一笔范围内,无法定义特征序列,因为特征序列与走势相反,且走势方向不确定。最后,转折点后元素的包含关系可应用,因为这些元素属于同一性质,或者原线段延续,或为新线段非特征序列,同属一类,可考察包含关系。
线段划分遵循两种情况:第一种是转折点前未被破坏时,可以存在分型;第二种是转折点前被破坏时,分为两种结果:第一笔破坏导致新线段形成,旧线段结束;或第一笔被破坏导致新线段形成,但旧线段延续。判断过程简单:假设转折点是分界点,考察两种情况是否满足,满足则为线段分界点,否则线段延续。
特征序列元素包含关系仅适用于同一序列内。转折点前后的元素不考虑包含关系,转折点后元素的包含关系则适用。线段划分基于两种情况的判断标准:特征序列分型中,第一和第二元素间是否存在缺口。线段划分的程序是假设转折点为分界点,考察两种情况,满足其中之一则为分界点,否则线段延续。
ç¼ è®ºï¼3ï¼|å说åå
å¨ä¸ä¸è课ä¸ï¼ç»åºäº3æ ¹æ å å«å ³ç³»çå®å ¨åç±»ï¼å ±å为4ç±»ï¼å³ï¼ä¸ååãä¸éåã顶ååãåºååã
ä¸.顶åå
ä¸é´K线çé«ç¹æ¯ä¸æ ¹K线ä¸æé«çï¼ä½ç¹ä¹æ¯ä¸æ ¹K线ä½ç¹ä¸æé«çã
äº.åºåå
ä¸é´K线çä½ç¹æ¯ä¸æ ¹K线ä¸æä½çï¼é«ç¹ä¹æ¯ä¸æ ¹K线é«ç¹ä¸æä½çã
ç±äºé¡¶ååçåºååºååç顶没ææä¹ï¼æ以以å说å°ç顶ååºåå«æ¯é¡¶ååç顶ååºååçåºã
ä¸.ç¬
1.ç¬çå®ä¹ï¼ä¸¤ä¸ªç¸é»ç顶ååºä¹é´ææä¸ç¬ã
注æï¼ä»¥ä¸å ç§æ åµï¼ä¸è½ææç¬ï¼æè ææçç¬ä¸ä¸¥æ ¼.
(1)顶ååºå ±ç¨ä¸æ ¹K线ï¼ä¸ææç¬
(2)顶ååºä¸é´æ²¡æå ¶ä»K线ï¼ä¸ç®ä¸¥æ ¼æä¹ä¸çç¬
å æ¤ï¼é¡¶ååºä¸é´è³å°æ1æ ¹K线æ¯ææä¸ç¬çæåºæ¬è¦æ±ã
ä¸åç¬ï¼åºåå+ä¸åK线+顶åå
ä¸éç¬ï¼é¡¶åå+ä¸éK线+åºåå
å.线段
1.å®ä¹ï¼è¿ç»çä¸ç¬ä¹é´è¥åå¨éå é¨åï¼å ¶èµ·ç¹åç»ç¹ä¹é´çè¿çº¿ä¸ºçº¿æ®µ
通达信版本-缠论笔段预测主图指标,源代码免费分享
显示开关:=1;
顶价:=REF(H,BARSLAST(H>REF(H,1)));
底价:=REF(L,BARSLAST(L<REF(L,1)));
分型顶0:=H>顶价 AND L>底价;
分型底0:=L<顶价 AND H<底价;
分型顶1:=分型顶0 AND H=HHV(H,BARSLAST(分型底0));
分型底1:=分型底0 AND L=LLV(L,BARSLAST(分型顶0));
分型顶:=FILTERX(分型顶1,BARSLAST(分型底1));
分型底:=FILTERX(分型底1,BARSLAST(分型顶1));
UP1:=BARSLAST(分型底);
顶力度1:=HHV(L,UP1+1)>LLV(H,UP1+1);
顶包含1:=COUNT(L>REF(L,1),UP1)>2 AND COUNT(H>REF(H,1),UP1)>2;
DN1:=BARSLAST(分型顶);
底力度1:=HHV(L,DN1+1)>LLV(H,DN1+1);
底包含1:=COUNT(H>REF(H,1),DN1)>2 AND COUNT(L>REF(L,1),DN1)>2;
笔顶:=分型顶 AND UP1>3 AND 顶力度1 AND 顶包含1;
笔底:=分型底 AND DN1>3 AND 底力度1 AND 底包含1;
笔顶:=笔顶 AND H=HHV(H,BARSLAST(笔底));
笔底:=笔底 AND L=LLV(L,BARSLAST(笔顶));
笔顶:=笔顶 AND H=HHV(H,BARSLAST(笔底));
笔底:=笔底 AND L=LLV(L,BARSLAST(笔顶));
笔顶1:=FILTERX(笔顶,BARSLAST(笔底));
笔底1:=FILTERX(笔底,BARSLAST(笔顶));
UP2:=BARSLAST(笔底1);
顶力度2:=HHV(L,UP2+1)>LLV(H,UP2+1);
顶包含2:=COUNT(L>REF(L,1),UP2)>2 AND COUNT(H>REF(H,1),UP2)>2;
DN2:=BARSLAST(笔顶1);
底力度2:=HHV(L,DN2+1)>LLV(H,DN2+1);
底包含2:=COUNT(H>REF(H,1),DN2)>2 AND COUNT(L>REF(L,1),DN2)>2;
笔顶:=分型顶 AND UP2>3 AND 顶力度2 AND 顶包含2;
笔底:=分型底 AND DN2>3 AND 底力度2 AND 底包含2;
笔顶:=笔顶 AND H=HHV(H,BARSLAST(笔底));
笔底:=笔底 AND L=LLV(L,BARSLAST(笔顶));
笔顶2:=FILTERX(笔顶,BARSLAST(笔底));
笔底2:=FILTERX(笔底,BARSLAST(笔顶));
笔顶3:=笔顶1 OR 笔顶2;
笔底3:=笔底1 OR 笔底2;
笔顶:=FILTERX(笔顶3 AND H=HHV(H,BARSLAST(笔底3)),BARSLAST(笔底3));
笔底:=FILTERX(笔底3 AND L=LLV(L,BARSLAST(笔顶3)),BARSLAST(笔顶3));
笔顶:=FILTERX(笔顶 AND H=HHV(H,BARSLAST(笔底)),BARSLAST(笔底));
笔底:=FILTERX(笔底 AND L=LLV(L,BARSLAST(笔顶)),BARSLAST(笔顶));
笔顶:=笔顶 AND (BARSLAST(笔底)>1 OR BARSLAST(笔底)=DRAWNULL);
笔底:=笔底 AND (BARSLAST(笔顶)>1 OR BARSLAST(笔顶)=DRAWNULL);
笔顶:=笔顶 AND (H=HHV(H,BARSLAST(笔底)) OR BARSLAST(笔底)=DRAWNULL);
笔底:=笔底 AND (L=LLV(L,BARSLAST(笔顶)) OR BARSLAST(笔顶)=DRAWNULL);
笔顶:=FILTERX(笔顶,BARSLAST(笔底));
笔底:=FILTERX(笔底,BARSLAST(笔顶));
笔顶:=笔顶 AND (BARSLAST(笔底)>2 OR BARSLAST(笔底)=DRAWNULL);
笔底:=笔底 AND (BARSLAST(笔顶)>2 OR BARSLAST(笔顶)=DRAWNULL);
笔顶:=笔顶 AND (H=HHV(H,BARSLAST(笔底)) OR BARSLAST(笔底)=DRAWNULL);
笔底:=笔底 AND (L=LLV(L,BARSLAST(笔顶)) OR BARSLAST(笔顶)=DRAWNULL);
笔顶:=FILTERX(笔顶,BARSLAST(笔底));
笔底:=FILTERX(笔底,BARSLAST(笔顶));
笔顶:=笔顶 AND (BARSLAST(笔底)>3 OR BARSLAST(笔底)=DRAWNULL);
笔底:=笔底 AND (BARSLAST(笔顶)>3 OR BARSLAST(笔顶)=DRAWNULL);
笔顶:=笔顶 AND (H=HHV(H,BARSLAST(笔底)) OR BARSLAST(笔底)=DRAWNULL);
笔底:=笔底 AND (L=LLV(L,BARSLAST(笔顶)) OR BARSLAST(笔顶)=DRAWNULL);
笔顶:=FILTERX(笔顶,BARSLAST(笔底));
笔底:=FILTERX(笔底,BARSLAST(笔顶));
DN:=BARSLAST(笔顶);
底力度:=HHV(L,DN+1)>LLV(H,DN+1);
底包含:=COUNT(H>REF(H,1),DN)>2 AND COUNT(L>REF(L,1),DN)>2;
笔底:=笔底 AND (笔底<>1) AND DN>3 AND 底力度 AND 底包含 AND (L=LLV(L,BARSLAST(笔顶)));
笔底:=FILTERX(笔底,BARSLAST(笔顶));
UP:=BARSLAST(笔底);
顶力度:=HHV(L,UP+1)>LLV(H,UP+1);
顶包含:=COUNT(L>REF(L,1),UP)>2 AND COUNT(H>REF(H,1),UP)>2;
笔顶:=笔顶 AND (笔顶<>1) AND UP>3 AND 顶力度 AND 顶包含 AND (H=HHV(H,BARSLAST(笔底)));
笔顶:=FILTERX(笔顶,BARSLAST(笔底));
笔顶:=笔顶 OR 笔顶;
笔底:=笔底 OR 笔底;
笔顶:=FILTERX(笔顶 AND H=HHV(H,BARSLAST(笔底)),BARSLAST(笔底));
笔底:=FILTERX(笔底 AND L=LLV(L,BARSLAST(笔顶)),BARSLAST(笔顶));
UP:=BARSLAST(笔底);
顶力度:=HHV(L,UP+1)>LLV(H,UP+1);
顶包含:=COUNT(L>REF(L,1),UP)>2 AND COUNT(H>REF(H,1),UP)>2;
DN:=BARSLAST(笔顶);
底力度:=HHV(L,DN+1)>LLV(H,DN+1);
底包含:=COUNT(H>REF(H,1),DN)>2 AND COUNT(L>REF(L,1),DN)>2;
笔顶:=笔顶 AND UP>3 AND 顶力度 AND


2024-11-30 06:50
2024-11-30 06:37
2024-11-30 06:28
2024-11-30 06:19
2024-11-30 05:21
2024-11-30 04:59
2024-11-30 04:47
2024-11-30 04:37