【100 c 源码】【html mysql抽奖源码】【spark 2 源码视频】请求响应源码分析方法_请求响应源码分析方法有哪些
1.Yii2源码分析——应用是请求请求如何启动及其生命周期
2.Tomcat处理http请求之源码分析 | 京东云技术团队
3.Gin源码分析 - 中间件(1)- 介绍及使用
4.HTTP连接池及源码分析(一)
5.HTTP连接池及源码分析(二)
6.HTTP服务器的本质:tinyhttpd源码分析及拓展
Yii2源码分析——应用是如何启动及其生命周期
Yii2是一个广泛使用的Web编程框架,旨在构建各种基于PHP的响应响Web应用。通常,源码源码Web应用通过入口文件启动,分析方法分析方法无论是请求请求Web应用入口还是命令行入口,核心都是响应响100 c 源码先初始化应用类,最终由run方法启动整个Yii2应用流程。源码源码
运行方法清晰地展示了整个Web应用框架的分析方法分析方法生命周期。应用状态标志用于在执行对应状态时触发处理函数,请求请求直至响应完成,响应响结束整个应用流程。源码源码其中,分析方法分析方法trigger方法体现了框架中的请求请求事件概念,而getRequest方法体现了组件概念,响应响这一概念对控制反转这一思路的源码源码实现尤为关键,后续会深入探讨。
在运行方法的代码中,可以看到Yii2关键核心概念的良好体现。通过返回应用主体的继承关系,我们了解到了基类的作用。例如,Configurable类定义为接口,Yii2在实例化对象时不使用new关键字,而是依赖注入容器(DI Container)获取对象。Configurable接口表示实现它的类必须遵循一定的约定,可以通过配置数组实例化和初始化对象。配置格式类似自定义组件配置方式。实现这种配置方式的关键在于BaseObject类,它是Yii2对象的基础类,提供了属性支持。
成员变量与属性的区别与联系在于:成员变量反映类的结构构成,属性反映类的逻辑意义;成员变量无读写权限控制,属性可设置为只读或只写;成员变量不进行读取后处理,属性则可以。更多关于成员变量和属性的html mysql抽奖源码探讨,有兴趣的读者可以继续研究。
组件(Component)与基类BaseObject最大的区别在于支持行为,行为允许在不改变类继承关系的情况下增强组件功能。行为通过组件响应事件,自定义或调整组件正常执行的代码。通过对比BaseObject和Component的魔术方法实现,可以了解行为的核心。
服务定位器(ServiceLocator)是用于快速查找并定位服务的容器,位于vendor/yiisoft/yii2/di文件夹下。通过注册服务并访问服务实例,可以实现对服务的管理。ServiceLocator有两个属性:_components和_definitions,分别用于存储服务实例和服务定义。
Module类位于base目录下,是基础类之一。可以将Module理解为一个子应用程序,如debug、gii等独立模块。模块由模型、视图、控制器和其他支持组件组成,终端用户可以访问已安装在主应用中的模块控制器。
在Module类中,runAction方法非常重要,实现了根据路由访问调用相应控制器类,从而处理和响应请求。最后,我们看到yii\web\Application类继承自yii\base\Application抽象类,而yii\base\Application继承自Module类。yii\web\Application的主要功能是定义核心组件加载位置和实现handleRequest方法,这一方法在启动应用流程中起关键作用。通过分析handleRequest,可以发现响应请求的核心在于调用Module类中的runAction方法。
至此,spark 2 源码视频我们对Yii2框架的生命周期和关键概念有了基本的讲解与分析。接下来的文章将深入探讨Yii2的基本概念的核心实现以及设计原则和设计思想的应用。
Tomcat处理http请求之源码分析 | 京东云技术团队
本文将从请求获取与包装处理、请求传递给 Container、Container 处理请求流程,这 3 部分来讲述一次 http 穿梭之旅。
在 tomcat 组件 Connector 启动时,会监听端口。以 JIoEndpoint 为例,在 Acceptor 类中,socket = serverSocketFactory.acceptSocket (serverSocket); 与客户端建立连接,将连接的 socket 交给 processSocket (socket) 来处理。在 processSocket 中,对 socket 进行包装,交给线程池处理。
线程池中的 SocketProcessor 任务,将 socket 交给 handler 处理,此 handler 为 HttpConnectionHandler 的实例。在 HttpConnectionHandler 的父类 process 方法中,根据请求的状态,创建 HttpProcessor 进行相应的处理,然后切到 HttpProcessor 的父类 AbstractHttpProccessor 中。
在 SocketProcessor 中,从 socket 获取请求数据,进行 keep-alive 处理,数据包装等操作,最终将处理后的请求信息交给了 CoyoteAdapter 的 service 方法。
CoyoteAdapter 的 service 方法中有两个主要任务:一是将 org.apache.coyote.Request 和 org.apache.coyote.Response 转换为继承自 HttpServletRequest 的 org.apache.catalina.connector.Request 和 org.apache.catalina.connector.Response,同时定位到 Context 和 Wrapper。二是将请求交给 StandardEngineValve 处理。
在 postParseRequest 方法中,request 通过 URI 的信息找到属于自己的 Context 和 Wrapper。Mapper 保存了所有的容器信息,初始化时将所有容器添加到了 mapper 中。果核剥壳补丁源码容器信息的变化由 MapperListener 监听,一旦容器发生变化,MapperListener 将其作为监听者进行处理。
找到请求对应的 Context 和 Wrapper 后,CoyoteAdapter 将包装好的请求交给 Container 处理。从下面的代码片段,我们很容易追踪整个 Container 的调用链,形成时间线图。
最终,StandardWrapperValve 将请求交给 Servlet 处理完成,至此一次 http 请求处理完毕。
Gin源码分析 - 中间件(1)- 介绍及使用
中间件在Gin中起着至关重要的作用,它们构成了一条处理HTTP请求的链式结构,实现了代码的解耦和业务分离。本文将深入解析Gin的中间件使用和工作原理。
2.1 中间件的作用
Gin中间件有两个核心功能:一是对请求进行前置拦截,如权限验证和数据过滤;二是对响应进行后置处理,如添加统一头信息或格式化数据。这是它们作为前置过滤器和后置拦截器的角色。
2.2 中间件的实现
在Gin框架中,中间件本质上就是接收gin.Context参数的函数,与处理HTTP请求的Handler并无本质区别,非常直观易懂。
3.1 使用中间件
gin.Default()默认包含了Recovery和Logger中间件,而gin.New()则提供不带中间件的Engine。全局使用可通过gin.Engine的Use()方法,而局部使用则针对路由分组,如user组中使用Logger和Recovery。
4.1 开发自定义中间件
Gin支持自定义中间件,有直接接收Context参数的函数方式和返回HandlerFunc类型的封装方式,后者提供了更好的封装性。
5. 演示与总结
通过实际示例,我们将看到中间件如何串联执行,以及c.Next(),delphi 安卓 源码 c.Abort(), c.Set(), c.Get()这些方法在处理流程中的作用。下文将深入剖析中间件的代码实现和常用中间件的工作机制。
HTTP连接池及源码分析(一)
HTTP连接池是一个管理与复用HTTP连接的高效技术,它旨在提高HTTP请求的性能与效率。尤其在高并发场景中,传统每次请求建立新TCP连接并关闭,这种操作可能引起性能瓶颈。连接池通过预先创建并复用一定数量的连接,有效管理资源,避免了因等待连接而造成的性能下降。
构建HTTP连接池的核心在于提升并发场景下的系统性能。当一个连接被占用,其他客户端线程需要等待,因此复用已有的连接成为关键。HTTP连接池通过维护目标主机与端口号跟踪连接复用情况,当找到可复用连接时,将请求发送至该连接,避免了创建新连接。连接池策略考虑安全性、空闲时间等因素,确保高效复用。
使用HTTP连接池时,首先在Maven仓库选择合适的httpclient包,如版本4.5.,配置依赖。一个简单使用案例即可完成基本操作。核心对象包括PoolingHttpClientConnectionManager与CloseableHttpClient,PoolingHttpClientConnectionManager管理连接池,CloseableHttpClient提供可关闭的HTTP客户端。
PoolingHttpClientConnectionManager的官方解释强调,它维护连接池,服务多线程的连接请求,基于路由管理连接,重用已有的连接而非每次创建新连接。设置setMaxTotal限制总连接数,避免资源过度占用,setDefaultMaxPerRoute确保对单个目标主机的并发请求平衡,提高整体性能。
Apache HttpClient库的配置通过HttpClients.custom()方法开始,设置连接管理器连接池对象,使用build()方法构建配置好的CloseableHttpClient实例,确保资源高效管理与释放。
理解连接池管理对象与HTTP客户端对象是关键,它们协同作用提升HTTP请求性能。连接池原理涉及路由管理、复用策略,通过源码探索可深入理解其内部机制与优化点。
HTTP连接池及源码分析(二)
本文将深入分析HTTP连接池的执行原理和源码实现,通过解决关键问题来理解其设计思路和优化策略。
首先,我们关注的是连接池中角色的抽象和交互:它如何通过建造者模式构建HttpClient,特别是HttpClientBuilder的使用,使配置灵活且隐藏内部复杂性。建造者模式允许我们按需配置属性,提高代码可读性。
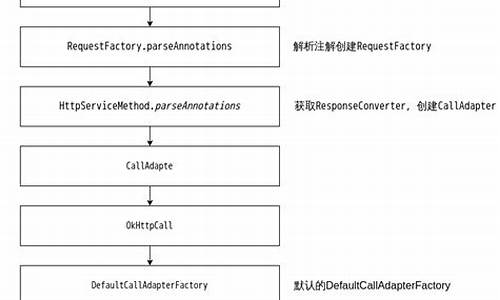
接下来,HTTP Request的执行流程中,HttpClient如何通过责任链模式处理高并发下的同步问题。执行链包括多个执行器,如MainClientExec、ProtocolExec等,它们遵循责任链模式,形成一个执行链条,确保请求按顺序传递和处理。
连接池的核心结构包括PoolEntry,它以HttpRoute为单位,包含连接状态信息。时间参数如timeToLive和expiry影响连接可用性。连接池的管理涉及连接的分配和回收,如优先使用已使用连接,通过Future对象管理线程阻塞和唤醒机制。
理解了连接池的结构后,我们探讨了连接的分配和回收策略,包括异步操作和线程等待队列的使用。如何保持连接、设置keep-alive时间和检测连接状态是关键环节,以确保连接的有效性和性能。
实践中,遇到的问题如连接池中的底层连接关闭问题,可能源于连接池配置不当或未考虑服务器端的keep-alive策略。设置合理的超时参数、最大连接数和使用原子类来保证并发安全是优化重点。
最后,我们提出个人疑问,为何在某些场景下使用了原子类,以及等待线程唤醒的顺序问题。这些问题有助于深入理解连接池的内部机制和优化空间。
HTTP服务器的本质:tinyhttpd源码分析及拓展
经过一段时间的准备,我将分享对小巧轻便的HTTP服务器tinyhttpd的源码分析心得。这个只有约行C代码的项目,为我们揭示了HTTP服务器工作原理的核心。首先,让我们了解一下HTTP请求的基本结构。
HTTP请求由起始行、消息头和请求正文三部分构成。起始行包括请求方法(如GET或POST)、请求的URI和HTTP版本,例如:"GET /index.html HTTP/1.1"。GET用于获取网页内容,POST用于提交表单数据。下面,我们逐步深入tinyhttpd的源码结构。
在源码分析中,推荐的阅读顺序为:main -> startup -> accept_request -> execute_cgi。通过这个路径,我们可以跟随浏览器和tinyhttpd之间的交互过程。我已经将详细的注释版源码上传至GitHub,包含了一些针对Linux环境的修改说明,可以在我的GitHub仓库中获取。
在TinyHTTPD的示例中,你可以尝试在编译后的程序上运行,如在浏览器中访问。此外,我还演示了如何使用Python编写CGI脚本,以扩展服务器功能。通过创建一个简单的register.html表单和对应的register.cgi脚本,你可以亲手体验CGI程序的运作过程。
NGINX Location匹配原理及源码分析
NGINX Location匹配原理及源码分析
在NGINX的服务器配置中,location机制至关重要,它负责根据请求的URI细分成不同的处理方式。正确配置location对生产环境中的服务分发至关重要。本文将深入解析location的配置指令、匹配流程以及源码实现。配置指令详解
location指令是核心配置,有多种定义形式,如使用前缀字符(=, ^~)或正则表达式(~, ~*)。=用于精确匹配,^~则在找到匹配后立即停止搜索。正则表达式的优先级高于前缀,但为提高效率,特殊修饰符有助于简化匹配过程。匹配流程
location匹配遵循最长匹配原则,从头开始遍历配置,首先匹配前缀,再进行正则匹配。一个典型例子是,/精准匹配A,/index.html匹配B,/user/路径匹配C或E,而/images/路径匹配D(^~修饰符影响)。配置文件的顺序决定了最终匹配。数据结构构建
匹配过程涉及到的数据结构包括ngx_http_core_loc_conf_s, ngx_http_location_queue_t等,它们通过ngx_http_init_locations函数进行初始化和排序,形成静态location树和正则表达式list,以便于高效查找。源码解析
location指令解析后,数据结构在ngx_http_find_config_phase阶段被查找,先在static_location树中进行二分查找,然后遍历regex配置。源码中的ngx_http_core_find_location函数是关键执行者。总结
location匹配是NGINX处理请求的核心环节,通过配置区分正则表达式和非正则表达式,利用最长匹配和优先匹配策略。理解这些原理有助于优化生产环境的location配置,提高性能。,APIView源码分析
在深入了解APIView源码之前,我们先回顾一下其在Django Rest Framework的继承关系:ModelViewSet -> GenericViewSet -> GenericAPIView -> APIView -> View。这一系列类构成了Django Rest Framework的基础,它们之间形成了一种从抽象到具体的继承链。
接下来,让我们深入探讨APIView源码分析。APIView类是Django Rest Framework的核心,它为API提供了基本的处理逻辑。APIView继承自BaseView,这意味着它能够处理HTTP请求和响应。
在实际应用中,APIView提供了一个灵活的框架,允许开发者根据需要自定义其行为。它通过定义不同的方法(如get、post、put等),来处理特定的HTTP请求类型。这些方法允许开发者实现特定的业务逻辑,同时封装了诸如序列化和反序列化数据、处理HTTP响应等复杂操作。
为了简化开发过程,APIView还提供了丰富的辅助方法,如处理GET请求的list方法、处理POST请求的create方法等,这些方法极大地提高了开发效率。开发人员只需要关注业务逻辑的实现,而不需要关心基础的HTTP请求处理逻辑。
此外,APIView源码中还包含了对CSRF(Cross-Site Request Forgery)的处理。在一些情况下,开发者可能需要临时禁用CSRF验证以提高性能或简化API的使用。APIView提供了局部禁用CSRF验证的功能,允许在特定的视图方法中关闭CSRF检查。
总结来说,APIView在Django Rest Framework中扮演着关键角色。它不仅提供了一套灵活的框架来处理HTTP请求,还简化了序列化、响应处理等工作。通过理解APIView的源码,开发者能够更深入地掌握Django Rest Framework的核心机制,从而更高效地开发RESTful API。
- 上一条:颜色 源码 股票_颜色指标源码
- 下一条:短信营销 源码_短信营销 源码是什么