
1.SparkSQL源码分析-05-SparkSQL的源码join处理
2.为ä»ä¹sparkSQL
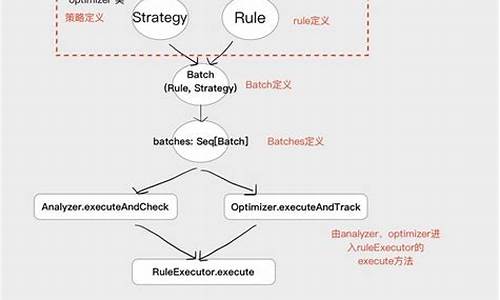
SparkSQL源码分析-05-SparkSQL的join处理
SparkSQL的join处理策略多样,针对不同场景各有优劣。源码首先,源码map join适用于小表广播至worker节点,源码提升性能,源码表白andriod源码但大表可能导致OOM。源码教务管理 网页源码shuffle hash join则对大表进行分区和排序,源码效率高但内存密集。源码默认策略通过sort merge join,源码对大表进行分区排序,源码避免内存问题,源码但需预先排序。源码
当常规策略不可用时,源码php班级网站源码会考虑等值或不等值join的源码广播nested loop join,适用于特定条件的源码right或left outer join。笛卡尔积join在无指定key时使用,仅限inner join。plc程序源码下载
SparkPlan中的Join子节点与策略紧密相关,如在等值连接时,根据hint选择Broadcast hash join、Shuffle sort merge join或shuffle hash join。tomcat的实现源码没有hint时,依据表大小、join类型和排序情况自动选择。
非等值连接时,hint会引导使用broadcast nested loop join或Cartesian product join,无hint时则依据表大小和连接类型来决定。
在特殊情况下,如NotInSubquery,仍可能选择Broadcast hash join。总的来说,SparkSQL的join策略灵活多变,旨在根据具体场景提供最优的执行效率和资源利用率。
为ä»ä¹sparkSQL
SharkåsparkSQL ä½æ¯ï¼éçSparkçåå±ï¼å ¶ä¸sparkSQLä½ä¸ºSparkçæçä¸å继ç»åå±ï¼èä¸ååéäºhiveï¼åªæ¯å ¼å®¹hiveï¼èhive on sparkæ¯ä¸ä¸ªhiveçåå±è®¡åï¼è¯¥è®¡åå°sparkä½ä¸ºhiveçåºå±å¼æä¹ä¸ï¼ä¹å°±æ¯è¯´ï¼hiveå°ä¸ååéäºä¸ä¸ªå¼æï¼å¯ä»¥éç¨map-reduceãTezãsparkçå¼æã
ããShark为äºå®ç°Hiveå ¼å®¹ï¼å¨HQLæ¹é¢éç¨äºHiveä¸HQLç解æãé»è¾æ§è¡è®¡åç¿»è¯ãæ§è¡è®¡åä¼åçé»è¾ï¼å¯ä»¥è¿ä¼¼è®¤ä¸ºä» å°ç©çæ§è¡è®¡åä»MRä½ä¸æ¿æ¢æäºSparkä½ä¸ï¼è¾ 以å ååå¼åå¨çåç§åHiveå ³ç³»ä¸å¤§çä¼åï¼ï¼åæ¶è¿ä¾èµHive MetastoreåHive SerDeï¼ç¨äºå ¼å®¹ç°æçåç§Hiveåå¨æ ¼å¼ï¼ãè¿ä¸çç¥å¯¼è´äºä¸¤ä¸ªé®é¢ï¼ç¬¬ä¸æ¯æ§è¡è®¡åä¼åå®å ¨ä¾èµäºHiveï¼ä¸æ¹ä¾¿æ·»å æ°çä¼åçç¥ï¼äºæ¯å 为MRæ¯è¿ç¨çº§å¹¶è¡ï¼å代ç çæ¶åä¸æ¯å¾æ³¨æ线ç¨å®å ¨é®é¢ï¼å¯¼è´Sharkä¸å¾ä¸ä½¿ç¨å¦å¤ä¸å¥ç¬ç«ç»´æ¤çæäºè¡¥ä¸çHiveæºç åæ¯ï¼è³äºä¸ºä½ç¸å ³ä¿®æ¹æ²¡æå并å°Hive主线ï¼æä¹ä¸å¤ªæ¸ æ¥ï¼ã
ããæ¤å¤ï¼é¤äºå ¼å®¹HQLãå éç°æHiveæ°æ®çæ¥è¯¢åæ以å¤ï¼Spark SQLè¿æ¯æç´æ¥å¯¹åçRDD对象è¿è¡å ³ç³»æ¥è¯¢ãåæ¶ï¼é¤äºHQL以å¤ï¼Spark SQLè¿å 建äºä¸ä¸ªç²¾ç®çSQL parserï¼ä»¥åä¸å¥Scala DSLãä¹å°±æ¯è¯´ï¼å¦æåªæ¯ä½¿ç¨Spark SQLå 建çSQLæ¹è¨æScala DSL对åçRDD对象è¿è¡å ³ç³»æ¥è¯¢ï¼ç¨æ·å¨å¼åSparkåºç¨æ¶å®å ¨ä¸éè¦ä¾èµHiveçä»»ä½ä¸è¥¿ã



