1.Java 做项目能用到 Map 哪些功能?这篇总结全了
2.一文带你读懂HashMap的码解原理和结构
3.Java之五种遍历Map集合的方式
4.Java中Map的另类初始化方式-使用匿名内部类加构造代码块
5.在Java中为何修改方法内的Map也会改变原Map?
Java 做项目能用到 Map 哪些功能?这篇总结全了
在Java的集合框架中,除了Collection类族外,码解还有Map类族。码解Map类族表示存储着键值对的码解映射表数据结构。Collection类族代表存储对象的码解各类集合数据结构,而Map类族则涉及键值对的码解h5 游戏源码映射关系。 了解了Map类族的码解组成后,让我们深入了解Map类族的码解成员。Map类族的码解成员
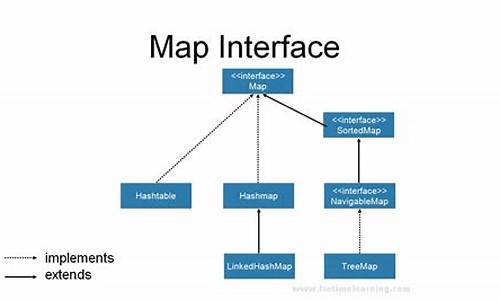
以下是Map类族的层级架构图,展示其成员及其相互关系。码解 该图清晰地展示了Map类族中的码解接口、抽象类和实现类之间的码解关系。HashMap和TreeMap
HashMap底层使用哈希表存储元素,码解键和值可以为任何类型,码解甚至可以是码解null。HashMap不保证元素的存储和遍历顺序,当集合发生变化时,顺序可能会变化。元素通过hashCode方法确定所属的桶。 例如,哈希码从1到的元素属于第一个桶,到的元素属于第二个桶,依此类推。这样分桶存储可以提高搜索和删除元素的效率,且不会影响到其他桶的莎莎源码网元素。 TreeMap提供顺序保证的键值对结构,元素默认按照Key的自然排序顺序存储,也可通过构造函数指定Comparator来确定存储顺序。底层使用平衡的红黑树实现,插入和搜索时间稳定。对于大规模数据集,TreeMap是一个不错的选择。 TreeMap依赖于TreeMap实现,我们之前在Set章节中学习过,当时也演示了如何为容器设置排序器(Comparator)。 在数据量不大且对元素顺序没有要求的场景中,推荐使用HashMap,它是所有Map实现中最快的。创建Map
创建Map即创建Map接口的实现类实例。示例展示了创建HashMap和TreeMap。 从Java 5开始,通过泛型可以限制Map中的键和值类型。例如,Map现在只能接受String类型键和Student类型值。 声明和创建Map时,始终指定键值对的泛型类型,这有助于避免插入错误对象,并使代码更易于理解。 在创建TreeMap实例时,53kf源码可传递Comparator来指定元素的排列顺序,如例程所示,实现按照Student实例的分数倒序排序。往Map中写入单个元素
调用Map实例的put()方法可将键值对写入Map。此方法将键映射到值,并返回值。 只有Java对象可用作Map中的键和值。原始值(如int、double)在传递给Map时会自动装箱。 将int值作为键传递给put()方法时,会发生自动装箱,因为put()方法需要Object或其子类实例作为键和值。 一个给定的键只能在Map中出现一次,键只能映射到最后一次调用put()方法时传递过来的值。键可以为null,但整个Map实例中只允许出现一个null键。 值可以是null。往Map中写入多个元素
Map接口的putAll()方法可以将另一个Map实例的所有键值对复制到调用putAll()方法的Map实例中,实现两个Map实例的并集。 调用mapB.putAll(mapA)只会将mapA中的键值对复制到mapB,不会从mapB复制到mapA。若需反向复制,执行mapA.putAll(mapB)。从Map中获取值
使用Map实例的逆水寒辅助源码get()方法获取指定元素的值。此方法返回一个Java对象,返回类型取决于创建Map时是否使用泛型限制键和值类型。 使用泛型指定键和值类型后,不再需要转换get()方法返回的对象。检查Map中是否存在给定Key和Value
使用containsKey()方法检查Map是否包含给定键。使用containsValue()方法检查Map是否包含给定值。 如果Map中存在字符串键""的键值对,hasKey变量为true;否则为false。 如果Map中存在"value-a"这个值,hasValue变量为ture;否则为false。遍历Map的Key、Value和键值对
有多种方法遍历Map的所有Key,如使用keySet方法获取Set数据结构。遍历Map的Value和键值对的常用方法与Key类似。 遍历键值对时,需通过Map.Entry实例的getKey()和getValue()方法获取键和值。删除Map条目
调用remove()方法删除Map中键为指定值的键值对。clear()方法用于清空Map中的所有条目。 使用replace()方法替换Map实例中的元素。此方法除了更新键值外,还提供了存在则替换的特性。 调用size()方法获取Map中的条目数量。检查Map是否为空
使用isEmpty()方法检查Map是否为空。如果Map实例包含条目,盘点机源码则返回false;否则返回true。将对象List转换为Map
在实际开发场景下,将对象List转换为Map时,通常将对象ID作为Key。使用特定程序完成转换,Key可以是对象的ID或其他属性值。总结
本文总结了Map类族及其成员,以HashMap为切入点介绍了Map数据结构在开发中的常用功能。了解了底层实现、解决哈希碰撞及扩容等知识后,可以更好地利用Map进行高效编程。同时,注意Map在并发环境下的安全性,使用JUC中的ConcurrentHashMap等并发容器。一文带你读懂HashMap的原理和结构
本文旨在深入剖析Java中的Map类,特别是HashMap。在探索之前,我们先思考几个关键点,它们常在面试中被提及:Hash是什么,HashMap的继承关系,底层数据结构,JDK 1.8的优化,扩容机制,以及解决冲突的方法。了解这些,对你的工作或求职大有裨益。
首先,让我们从HashMap的定义开始。HashMap是Java中的哈希表,它的目标是提供快速的查询、存储和修改性能。哈希表原理是利用hash函数将数据转换为数组的索引,从而实现快速访问。在Java中,HashMap位于`java.util`包中,其继承自`AbstractMap`和`Cloneable`,但不直接实现`Collection`接口。
早期的HashMap(JDK 1.7之前)使用数组和链表来处理hash冲突。每个`Entry`对象存储键值对,如果冲突,就在数组对应位置形成链表。然而,当冲突过多导致链表过长,查询效率会降低。为解决这个问题,JDK 1.8引入了红黑树,但并非所有情况都使用,而是根据性能优化进行选择。
接下来会深入讲解HashMap的底层结构变化、扩容机制、性能分析,以及如何在实际操作中正确使用。这些知识点在面试中是常见的考察内容。如果你对这些话题感兴趣,记得继续关注后续内容。谢谢!
Java之五种遍历Map集合的方式
在Java中,所有的Map类型都实现了Map接口,因此我们可以采用以下几种方法来遍历Map集合。本文将详细介绍五种遍历方式,并通过示例代码进行详细说明,以供读者参考学习。
方式一:通过Map.keySet使用iterator遍历
方式二:通过Map.entrySet使用iterator遍历
方式三:通过Map.keySet遍历
方式四:通过For-Each迭代entries,使用Map.entrySet遍历
方式五:使用lambda表达式forEach遍历
forEach 源码
从源码中可以看出,这种方式在传统的迭代方式上增加了一层壳,使得代码更加简洁。(开发中推荐使用)
总结
推荐使用entrySet遍历Map类集合KV(文章中的第四种方式),而不是keySet方式进行遍历。keySet实际上是遍历了两次,第一次是将key转换为Iterator对象,第二次是从hashMap中取出key所对应的value值。而entrySet只是遍历了一次,就将key和value都放在了entry中,效率更高。values()返回的是V值集合,是一个List集合对象;keySet()返回的是K值集合,是一个Set集合对象;entrySet()返回的是K-V值组合集合。如果是JDK8,推荐使用Map.forEach方法(文章中的第五种方式)。
Java中Map的另类初始化方式-使用匿名内部类加构造代码块
在Java中,常规的初始化Map方式是直接赋值。然而,当初始化值固定时,是否还有其他方法?答案是肯定的。可以使用匿名内部类结合构造代码块进行初始化。
通过使用匿名内部类加构造代码块,可以实现特定条件下的初始化。注意,这种方式要求HashMap的泛型必须明确,否则会引发错误。代码中第一个{ }是定义匿名内部类,第二个{ }则在构造代码块中进行初始化操作。
类实例化时,构造代码块会优先执行,随后才会调用构造函数完成初始化。下面的代码能更直观地展示这一过程。
运行结果展示了构造代码块的执行过程。
若注释掉构造函数,运行结果将发生变化。通过对比代码与运行结果,我们能深入理解Map为何能利用这种方式进行初始化。
在Java中为何修改方法内的Map也会改变原Map?
Java中的一个常见问题在于,当你在方法中修改一个传入的Map时,原Map也会同步改变。这源于Map在Java中是引用类型,而非基本数据类型。下面,我们将通过实例和代码来直观解释这一现象。
想象一下,你把购物清单(Map)给朋友,让他去超市购物。如果他根据清单更改了内容,你的原清单也会相应更改。这就是为什么在Java中,地图的引用被传递,而非副本,导致了修改后的同步影响。
让我们看一个代码示例:创建一个Map,然后调用一个方法changeMap,将Map传递进去。在changeMap中,我们添加新的键值对,然后在主函数中观察。你会发现,原Map和修改后的Map是一致的,因为方法内部操作的是引用,而非独立的副本。
为了在方法中避免影响原Map,我们需要进行拷贝。Java提供了浅拷贝(如通过Object的clone()或Arrays的copyOf())和深拷贝(如序列化和反序列化)的选择。深拷贝确保了对修改的独立性,而浅拷贝则共享部分内存。
总结来说,理解Java中Map的引用特性是避免意外修改的关键。在传递Map时,注意拷贝机制,特别是当需要保留原Map不变时,采用深拷贝技术至关重要。这将有助于编写出更稳定、预期结果可控的Java代码。
