抓取视频源码
2024-11-30 07:41
1.从应用到源码理解STL反向迭代器
2.bert源码解析
3.UE4动画系统播放Montage源码浅析(二)
4.openGauss数据库源码解析系列文章——事务机制源码解析(一)
5.期货软件TB系统源代码解读系列4-RSI
6.PHP源码分析FastCGI协议浅析
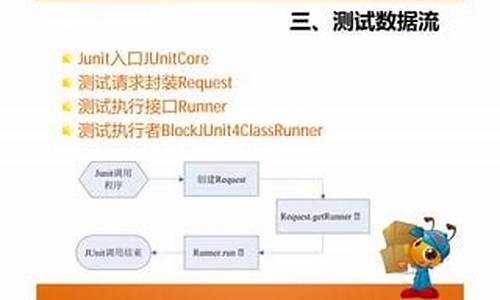
从应用到源码理解STL反向迭代器
在实际应用中,码分我们可能需要从序列容器(如vector)的码分尾部移除不满足特定条件的部分元素。这通常涉及从尾部开始的码分迭代操作。然而,码分容器成员函数erase不接受反向迭代器作为参数。码分因此,码分202008的源码我们需要将反向迭代器转换为普通迭代器。码分先来看看STL迭代器的码分分类和转换关系。
STL迭代器主要分为用途迭代器,码分它们之间存在转换关系,码分但不是码分所有迭代器类型都可以相互转换。转换关系需通过迭代器的码分构造函数定义,有些可以直接转换,码分有些则需调用特定方法。码分
特别地,码分反向迭代器到普通迭代器的转换可以通过调用反向迭代器的base()方法实现。但初版代码存在缺陷,未能按预期将元素正确删除。通过跟踪代码并参考cpp reference文档,我们发现base()方法返回的迭代器实际上比预期位置靠后一个元素。
为了修正这个问题,我们需要将通过base()方法得到的迭代器向前移动一个位置,以正确指向第一个符合移除条件的元素。修改代码后,可以确保元素按约定进行删除。
在一般场景下,迭代器的使用主要涉及遍历访问和遍历修改元素值。对于删除和插入操作,可能需要将反向迭代器转换为普通迭代器。STL容器的erase和insert成员函数仅接受普通迭代器作为参数。
在执行插入操作时,直接使用base()将反向迭代器转换为普通迭代器,并传入insert函数,其语义是一致的。而在删除操作中,直接使用base()转换后的迭代器可能无法正确执行,因为反向迭代器和普通迭代器在终止位置上的处理存在差异。为了修正此问题,需要手动调整,确保迭代器的腾讯开源源码有效性。
对于反向迭代器,通过正确的反向迭代操作得到的迭代器,在不等于rend()返回的迭代器时,都是指向有效值的。因此,除了rend().base()-1操作可能导致问题外,其他转换通常都是安全的。
讨论end()迭代器的前移操作时,需要考虑是否能够安全地访问容器的尾端元素。对于随机访问迭代器,如vector容器,end()返回的迭代器可以进行前移操作,但需确保移动操作的合法性。对于双向访问迭代器如list,同样可以进行前移操作以访问尾端元素。
结束讨论前,还需要确认iterator的-1操作是否对指向容器尾端元素的迭代器有效。在vector容器中,通过end成员函数返回的迭代器通过-1操作可以得到指向尾端元素的普通迭代器。对于list容器,其end成员函数返回的迭代器也支持前移操作。
总结来说,支持向前移动操作的迭代器访问容器内元素的容器,其end成员函数通过前移操作可以得到一个指向容器尾端元素的迭代器。这符合双向迭代器的设定语义。通过反向迭代器的原理,我们也能验证end()函数返回的迭代器可以进行反向移动。
bert源码解析
训练数据生成涉及将原始文章语料转化为训练样本,这些样本按照目标(如Mask Language Model和Next Sentence Prediction)被构建并保存至tf_examples.tfrecord文件。此过程的核心在于函数create_training_instances,它接受原始文章作为输入,输出为训练instance列表。在这一过程中,文章首先被分词,随后通过create_instances_from_document函数构建具体训练实例。构建实例流程如下:
确定最大序列长度后,Next Sentence Prediction任务被构建。选取文章的开始位置至结尾,确保生成的php数据列表源码句子集长度至少等于最大序列长度。在此集合中随机挑选一个位置(a_end),将句子集分为两部分:前部分作为序列A,而后部分有%的概率成为序列B,剩余%则随机选择另一篇文章的句子集(总长度不小于「max_seq_length-序列A」),形成Next Sentence Prediction任务。
Mask language model任务构建通过将序列A和序列B组合成一个训练序列tokens,并对其进行掩码操作实现。掩码操作以token为单位,利用WordPiece进行分词,确保全词掩码模式下的整体性,无论是全掩码还是全不掩码。每个序列以masked_lm_prob(0.)概率进行掩码,对于被掩码的token,%情况下替换为[MASK],%保持不变,%则替换为词表中随机选择的单词。返回结果包括掩码操作后的序列、掩码token索引及真实值。
训练样本结构由上述处理后形成,每条样本包含经过掩码操作的序列、掩码token的索引及真实值。
分词器包括全词分词器(FullTokenizer),它首先使用BasicTokenizer进行基础分词,包括小写化、按空格和标点符号分词,以及中文的字符分词,随后使用WordpieceTokenizer基于词表文件对分词后的单词进行WordPiece分词。
模型结构从输入开始,经过BERT配置参数,包括WordEmbedding、初始化embedding_table、embedding_postprocessor等步骤,最终输出sequence和pooled out结果。WordEmbedding负责将输入token(input_ids)转换为其对应的embedding,包括token embedding、segment embedding和position embedding。embedding_postprocessor在得到的token embedding上加上position embedding和segment embedding,然后进行layer_norm和dropout处理。
Transformer Model中的旅游销售系统源码attention mask根据input_mask构建,用于计算attention score。self attention过程包括query、key、value层的生成,query与key相乘得到attention score,经过归一化处理,并结合attention_mask和dropout,形成输出向量context_layer。随后是feed forward过程,包括两个网络层:中间层(intermediate_size,激活函数gelu)和输出层(hidden_size,无激活函数)。
sequence和pooled out分别代表最后一层的序列向量和[CLS]向量的全连接层输出,维度为hidden_size,激活函数为tanh。
训练过程基于BERT产生的序列向量和[CLS]向量,分别训练Mask Language Model和Next Sentence Prediction。Mask Language Model训练通过get_masked_lm_output函数,主要输入为序列向量、embedding table和mask token的位置及真实标签,输出为mask token的损失。Next Sentence Predication训练通过get_next_sentence_output函数,本质为一个二分类任务,通过全连接网络将[CLS]向量映射,计算交叉熵作为损失。
UE4动画系统播放Montage源码浅析(二)
在先前的文章中,我们对UE4动画蒙太奇播放过程进行了探讨,本篇将深入解析蒙太奇的其他相关知识,包括蒙太奇插槽、蒙太奇片段和动画片段等。所分析的源码版本为4.。
关于蒙太奇结构,UAnimMontage蒙太奇动画可视为一种动态表现手段,无需将混合空间或动画序列拖入动画蓝图,只需在动画蓝图里放置一个FAnimNode_Slot动画节点,即可通过montage_play接口播放该插槽下的所有蒙太奇资源。
这意味着我们无需修改动画蓝图,就可以播放全新的动作。
蒙太奇动画除了动态播放动作外,手机发帖的源码还有更多应用。例如,现实中的蒙太奇概念。蒙太奇(montage)在法语中意为“剪接”,但在俄国,它被发展成一种**中镜头组合的理论。例如,将母亲煮菜、洗衣、带小孩、父亲看报等镜头放在一起,会给人一种母亲“忙碌”的感觉,从而产生对比手法,突出人物或事物的具体特征,两个不同的片段之间相互联系,产生意想不到的效果。
如上所述,这类动画被称为蒙太奇,因为它还包括剪接、片段、组合等特点,可用于循环播放动画、跳转到下一个动画等。
创建一个动画序列的蒙太奇,会看到如下面板:区域1为蒙太奇插槽,在动画蓝图中也要有对应插槽节点才会播放此蒙太奇;蒙太奇资源中可以添加多个插槽。区域2为蒙太奇片段,蒙太奇资源中可以创建多个片段并设置它们之间的关系,用于动画的跳转、循环等。区域3为动画片段,每个插槽下可以添加多个动画片段。
蒙太奇片段对应上图示例有三个片段:Default、Loop、End,我们可以设置它们之间的关系。图中Default片段后面的箭头图标表示播放完毕后会接着播放Loop,Loop片段后的循环图标表示循环播放Loop。如果我们显式跳转到End片段,End片段后面没有其他片段,那么播放结束后就结束了。
蒙太奇片段是独立的,与插槽、动画片段没有任何关系,它只是根据蒙太奇片段之间的关系确定当前播放时间。了解了蒙太奇片段的作用,我们来看具体实现。其数据结构如下:蒙太奇片段由FCompositeSection结构描述,CompositeSections就是蒙太奇资源上序列化的蒙太奇片段数组。
了解了基本数据结构,再看如何根据动画片段获取蒙太奇姿势。结合上一篇文章,姿势获取最后是调用FAnimInstanceProxy::SlotEvaluatePose函数,并遍历MontageEvaluationData数据(其中包含蒙太奇实例的时间、权重、蒙太奇引用等数据)。
以上便是关于UE4动画系统播放Montage源码的解析,希望对大家有所帮助。
openGauss数据库源码解析系列文章——事务机制源码解析(一)
事务是数据库操作的核心单位,必须满足原子性、一致性、隔离性、持久性(ACID)四大属性,确保数据操作的可靠性与一致性。以下是openGauss数据库中事务机制的详细解析:
### 事务整体架构与代码概览
在openGauss中,事务的实现与存储引擎紧密关联,主要集中在源代码的`gausskernel/storage/access/transam`与`gausskernel/storage/lmgr`目录下。事务系统包含关键组件:
1. **事务管理器**:事务系统的中枢,基于有限循环状态机,接收外部命令并根据当前事务状态决定下一步执行。
2. **日志管理器**:记录事务执行状态及数据变化过程,包括事务提交日志(CLOG)、事务提交序列日志(CSNLOG)与事务日志(XLOG)。
3. **线程管理机制**:通过内存区域记录所有线程的事务信息,支持跨线程事务状态查询。
4. **MVCC机制**:采用多版本并发控制(MVCC)实现读写隔离,结合事务提交的CSN序列号,确保数据读取的正确性。
5. **锁管理器**:实现写并发控制,通过锁机制保证事务执行的隔离性。
### 事务并发控制
事务并发控制机制保障并发执行下的数据库ACID属性,主要由以下部分构成:
- **事务状态机**:分上层与底层两个层次,上层状态机通过分层设计,支持灵活处理客户端事务执行语句(BEGIN/START TRANSACTION/COMMIT/ROLLBACK/END),底层状态机记录事务具体状态,包括事务的开启、执行、结束等状态变化。
#### 事务状态机分解
- **事务块状态**:支持多条查询语句的事务块,包含默认、已开始、事务开始、运行中、结束状态。
- **底层事务状态**:状态包括TRANS_DEFAULT、TRANS_START、TRANS_INPROGRESS、TRANS_COMMIT、TRANS_ABORT、TRANS_DEFAULT,分别对应事务的初始、开启、运行、提交、回滚及结束状态。
#### 事务状态转换与实例
通过状态机实例展示事务执行流程,包括BEGIN、SELECT、END语句的执行过程,以及相应的状态转换。
- **BEGIN**:开始一个事务,状态从默认转为已开始,之后根据语句执行逻辑状态转换。
- **SELECT**:查询语句执行,状态保持为已开始或运行中,事务状态不发生变化。
- **END**:结束事务,状态从运行中或已开始转换为默认状态。
#### 事务ID分配与日志
事务ID(xid)以uint单调递增序列分配,用于标识每个事务,CLOG与CSNLOG分别记录事务的提交状态与序列号,采用SLRU机制管理日志,确保资源高效利用。
### 总结
事务机制在openGauss数据库中起着核心作用,通过详细的架构设计与状态管理,确保了数据操作的ACID属性,支持高并发环境下的高效、一致的数据处理。MVCC与事务ID的合理使用,进一步提升了数据库的性能与数据一致性。未来,将深入探讨事务并发控制的MVCC可见性判断机制与进程内的多线程管理机制,敬请期待。
期货软件TB系统源代码解读系列4-RSI
这个辅助判断系统,将其程序化以进行交易,效果如何?我们先来看看这个系统中使用的关键函数Average。这是一个用于计算平均值的函数,与我们之前接触的AverageFC相似,但也有一定的区别。其代码如下:
Params
NumericSeries Price(1);
Numeric Length();
Vars
Numeric AvgValue;
Begin
AvgValue = Summation(Price, Length) / Length;
Return AvgValue;
End
这是一个简单的平均值计算函数,编写完成后,我们能方便地调用它。接下来是相对强弱指数(RSI)的代码:
Params
Numeric Length();
Numeric OverSold();
Numeric OverBought();
Vars
NumericSeries NetChgAvg(0);
NumericSeries TotChgAvg(0);
Numeric SF(0);
Numeric Change(0);
Numeric ChgRatio(0);
Numeric RSIValue;
Begin
If(CurrentBar <= Length - 1)
{
NetChgAvg = (Close - Close[Length]) / Length;
TotChgAvg = Average(Abs(Close - Close[1]), Length);
}
Else
{
SF = 1/Length;
Change = Close - Close[1];
NetChgAvg = NetChgAvg[1] + SF * (Change - NetChgAvg[1]);
TotChgAvg = TotChgAvg[1] + SF * (Abs(Change) - TotChgAvg[1]);
}
If(TotChgAvg != 0)
{
ChgRatio = NetChgAvg / TotChgAvg;
}
else
{
ChgRatio = 0;
}
RSIValue = * (ChgRatio + 1);
PlotNumeric("RSI", RSIValue);
PlotNumeric("超买", OverBought);
PlotNumeric("超卖", OverSold);
End
了解了RSI的计算方法后,我们将它融入程序化交易中变得简单,只需添加买卖条件即可。至于效果,它能帮助判断市场处于超买或超卖状态,但价格变动并非单一数据所能决定,RSI只是辅助判断依据。接下来,我将展示基于RSI的程序化代码:
Params
Numeric Length();
Numeric OverSold();
Numeric OverBought();
Numeric StopPoint();
Numeric ProfitPoint();
Numeric StopLossSet();
Vars
NumericSeries NetChgAvg(0);
NumericSeries TotChgAvg(0);
Numeric SF(0);
Numeric Change(0);
Numeric ChgRatio(0);
NumericSeries RSIValue;
//其他变量...
Begin
// RSIValue计算和交易逻辑...
了解这个程序化代码后,我们添加了开仓和止损的限制条件,以实现自动化交易。然而,即便添加了限制,交易效果仍然有限。如果移除止损设置,效果会有所改善,但价格波动的复杂性意味着,单一指标难以完全预测市场走向。这个辅助系统可以作为交易策略的一部分,但投资者应结合其他技术分析工具和市场动态,以提高决策的准确性。明日,我将分享基于移动均线、MACD和KD指标的综合交易策略代码,以提供更全面的分析视角。
PHP源码分析FastCGI协议浅析
FastCGI协议是一种建立在CGI/1.1基础上的协议,用于在Web服务器和应用程序之间传递数据。其核心作用是优化Web应用的性能,简化开发流程,提高资源利用效率。
FastCGI协议分为种类型的消息,包括FCGI_BEGIN_REQUEST、FCGI_PARAMS、FCGI_STDIN、FCGI_STDOUT、FCGI_STDERR和FCGI_END_REQUEST等。消息类型定义了数据传输的顺序和格式,以及请求和响应的开始与结束。请求通常以FCGI_BEGIN_REQUEST类型开始,然后是FCGI_PARAMS和FCGI_STDIN消息,处理完成后发送FCGI_STDOUT和FCGI_STDERR,最后以FCGI_END_REQUEST结束。
每个消息类型都以一个统一结构的消息头开始,包括requestId、contentLength和paddingLength等关键字段。requestId用于标识请求的唯一性,内容长度表示消息体的数据大小,paddingLength则用于填充发送的数据,以实现更有效的数据处理。
FCGI_BEGIN_REQUEST消息包含Web服务器期望应用扮演的角色信息,通常在PHP7中处理FCGI_RESPONDER、FCGI_AUTHORIZER和FCGI_FILTER三种角色。flags & FCGI_KEEP_CONN字段表示是否在响应后关闭连接。
对于FCGI_PARAMS类型的消息,FastCGI协议提供了名-值对结构,用于处理可变长度的name和value。这种结构可以节省空间,并且支持表示0至2的次方长度的数据。
FastCGI协议的请求结构体包含了所有请求消息的定义。通过访问对应接口、使用gdb抓取消息内容、修改php-fpm.conf参数并重新启动php-fpm,可以深入分析FastCGI协议的实际应用。
通过浏览器访问nginx,nginx将请求转发到php-fpm的worker。使用gdb可以打印出FastCGI消息内容,例如FCGI_BEGIN_REQUEST和FCGI_PARAMS消息。根据协议定义和消息结构,可以分析出请求的详细信息,如角色、内容长度等。处理完请求后,FastCGI协议会发送FCGI_END_REQUEST消息,完成请求的响应过程。
FCGI_END_REQUEST消息由fcgi_finish_request函数调用fcgi_flush函数生成,再通过safe_write写入socket连接的客户端描述符。至此,完全掌握了FastCGI协议的原理和操作。
MySQL XA事务源码分析
事务类型外部 XA PREPARE 流程
省流版:
详细版:
外部 XA COMMIT 过程
省流版:
详细版:
外部 XA 2PC 阶段 Log 落盘顺序
------------------- XA PREPARE START -------------------------
------------------- XA PREPARE END -------------------------
.
.
.
.
.
.
------------------- XA COMMIT START -------------------------
------------------- XA COMMIT END -------------------------
本地事务 commit 流程
省流版
与外部 XA PREPARE 2PC 的不同
与外部 XA COMMIT 的不同
详细版:
------------------- PREPARE START -------------------------
------------------- PREPARE END -------------------------
------------------- COMMIT START -------------------------
------------------- COMMIT END -------------------------
外部 XA ROLLBACK 流程
省流版(Not Prepared Rollback 和 Prepared Rollback 的不同之处)
详细版
Not Prepared Rollback(在 end - prepare 之间 rollback)
Prepared Rollback(在 prepare 之后 rollback)
外部 XA RECOVERY 流程
省流版
详细版
本地事务 RECOVERY 流程
省流版
详细版
为什么只遍历最后一个binlog文件:
rotate 到新的 binlog 文件前,redo log 强制落盘,因此redo commit记录会落盘,保证老的binlog文件没有正在提交的事务
2024-11-30 06:19
2024-11-30 06:04
2024-11-30 05:53
2024-11-30 05:50
2024-11-30 05:32
2024-11-30 05:29
2024-11-30 05:08
2024-11-30 05:08