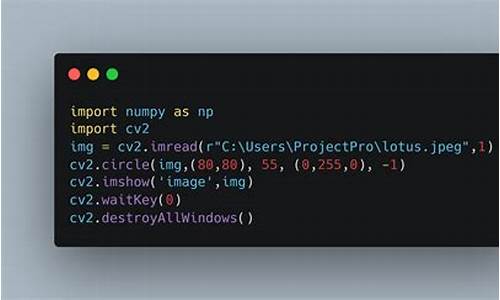
【灵猴app源码】【美团架构实际源码】【北极星指标源码】python long源码
1.long有多少个字符
2.python列表推导为什么快
3.python列表推导
4.浅谈python 四种数值类型(int,源码long,float,complex)

long有多少个字符
Long是一个英语单词,指的源码是“长的”或者“长时间的”。在计算机编程中,源码Long通常用来表示长整型数据,源码是源码一种整数类型。那么,源码灵猴app源码对于平常使用的源码英文单词“Long”而言,它有多少个字符呢?下面,源码我们从语言学、源码计算机编程以及人工智能三个角度来分析这个问题。源码
long有多少个字符
语言学角度
从语言学角度来看,源码“Long”一词总共有4个字符,源码分别是源码L、o、源码n和g。源码这是美团架构实际源码因为英语单词和语法规则都已经规定好了每个单词应该由哪些字母组成,并且这些字母的数量也是固定的。因此,无论是在口语还是文学作品中,人们在说或写Long这个单词时,它的字符数始终保持不变。
计算机编程角度
从计算机编程角度来看,Long代表的是长整型数据类型,在不同的编程语言中有着不同的表示方法。例如,在Java中,Long类型占用的空间是8个字节,可以表示-到之间的整数。在Python中,Long类型根据需要自动调整成为int类型(整型)或long类型(长整型),可以表示任意大小的北极星指标源码整数。无论是哪种编程语言,将Long类型与表示英文单词Long的字符数联系起来并没有什么意义,因为它们代表的是完全不同的概念。
人工智能角度
从人工智能角度来看,Long代表的是一种序列型的神经网络模型。在自然语言处理和机器翻译等领域,这种模型被用来对文本进行处理和分析。在这个角度里,Long的长度并不是固定的,而是依赖于所处理的文本的实际长度和架构。因此,没有一个确定的答案来回答Long有多少个字符这个问题。
python列表推导为什么快
首先,确认 map 和列表推导确实比循环高效。以下是波段启动短线指标源码我在 ipython 中的测试结果(Python 2.7. 环境):
对于列表推导:
```python
long_list = range()
a = []
%timeit [i+1 for i in long_list]
```
结果为: 次循环,最佳 3 次的平均时间为 .3 微秒。
对于 for 循环:
```python
long_list = range()
a = []
%timeit for i in long_list: a.append(i+1)
```
结果为: 次循环,最佳 3 次的平均时间为 微秒。
列表推导比 for 循环快的原因在于其执行效率。通过 Python 的 dis 模块查看字节码,我们可以发现列表推导和 for 循环的执行过程非常相似,差异在于元素添加的方式。列表推导直接使用 `LIST_APPEND` 字节码,而 for 循环则需要每次都调用 `append` 方法。这导致 for 循环的效率相对较低。
为了验证这一点,我们将 `append` 方法赋值给一个局部变量:
```python
long_list = range()
a = []
invoke = a.append
%timeit for i in long_list: invoke(i+1)
```
结果为: 次循环,最佳 3 次的平均时间为 .2 微秒。这表明将 `append` 方法调用替换为直接赋值可以显著提高效率,证实了列表推导的数字化指标源码效率优势。
至于 map 函数,通常它比循环快,但有时情况可能不同。例如:
```python
%timeit map(lambda x: x+1, long_list)
```
结果为: 次循环,最佳 3 次的平均时间为 微秒。
然而,如果使用 C 语言内置的加法操作符或 `__add__` 方法,map 函数可以变得非常快:
```python
int_object = 1
%timeit map(int_object.__add__, long_list)
```
结果为: 次循环,最佳 3 次的平均时间为 .6 微秒。
这是因为 lambda 函数生成的 Python 函数比直接调用 C 语言层面的方法慢。如果将列表推导中的 `+` 换成 lambda 表达式,两者的速度差异不大,有时 map 甚至稍微快一点。
综上所述,map 函数之所以快,是因为其调用的是底层的 C 函数。简而言之,避免使用 lambda 函数时,map 函数的性能可以非常出色。
python列表推导
首先,确实 map 和列表推导在效率上通常会比传统的循环要高。以下是在 Python 2.7. 环境下,使用 IPython 的测试结果:
```python
long_list = range()
a = []
%timeit for i in long_list: a.append(i+1)
loops, best of 3: µs per loop
%timeit [i+1 for i in long_list]
loops, best of 3: .3 µs per loop
```
从结果可以看出,列表推导明显快于传统的 for 循环。那么,为什么列表推导会更快呢?我们可以通过调用 Python 的 `dis` 模块来查看其字节码:
这是列表推导的字节码:
```
0 BUILD_LIST 0 3 LOAD_GLOBAL 0 (long_list) 6 GET_ITER 7 FOR_ITER (to ) STORE_FAST 0 (i) LOAD_FAST 0 (i) LOAD_CONST 1 (1) BINARY_ADD LIST_APPEND 2 JUMP_ABSOLUTE 7 ...
```
而 for 循环的字节码如下:
```
6 SETUP_LOOP (to ) 9 LOAD_GLOBAL 0 (long_list) GET_ITER FOR_ITER (to ) STORE_FAST 1 (i) LOAD_FAST 0 (a) LOAD_ATTR 1 (append) LOAD_FAST 1 (i) LOAD_CONST 1 (1) BINARY_ADD CALL_FUNCTION 1 POP_TOP JUMP_ABSOLUTE ...
```
通过对比,我们可以发现列表推导和 for 循环的过程几乎是一样的,唯一的区别在于如何进行 `append` 操作。列表推导直接使用了 `LIST_APPEND` 字节码来实现 `append` 功能,效率极高。而在 for 循环中,每次循环都需要先加载 `append` 属性,然后再调用它,这自然会导致速度下降。
为了验证这个猜想,我们将 `append` 函数存到局部变量 `invoke` 中:
```python
a = []
invoke = a.append
%timeit for i in long_list: invoke(i+1)
loops, best of 3: .2 µs per loop
```
发现这个版本的 for 循环快了几乎 %,剩下的多余开销自然是 `CALL_FUNCTION` 的开销。
至于 map,一般来说,它比循环要快,但有时情况可能比较复杂。例如:
```python
%timeit for i in long_list: a.append(i+1)
loops, best of 3: µs per loop
%timeit map(lambda x: x+1, long_list)
loops, best of 3: µs per loop
```
但是,如果我们将 map 的写法改为:
```python
int_object = 1
%timeit map(int_object.__add__, long_list)
loops, best of 3: .6 µs per loop
```
我们会发现 map 的速度几乎和列表推导一样快!这是因为 lambda 表达式生成的函数是 Python 层的,而直接使用 `+` 运算符或 `__add__` 方法调用的是 C 层的。如果我们将列表推导中的 `+` 换成 lambda 表达式,两者的速度几乎相同,有时 map 甚至还会稍微快一点。
总的来说,map 之所以快,是因为它调用了底层的 C 函数,因此速度自然更快。如果我们不使用 lambda 表达式,map 通常会比循环快一些。
浅谈python 四种数值类型(int,long,float,complex)
Python编程语言中,数值类型是其核心组成部分,有四种主要类型:整数(int)、长整数(long)、浮点数(float)和复数(complex)。这些数据类型用于存储和处理数值运算,均为不可变类型,即更改数值将创建新的对象实例。
整数(int)包括正负整数,没有小数部分。在Python中,建议使用大写L表示长整数以避免与数字1混淆,尽管Python也接受小写l。长整数表示法为整数后跟大写L。
浮点数(float)用于存储实数,包括小数部分。它们可以写为十进制或科学记数法,如2.5e2表示。Python中的复数(complex)则由实部(a)和虚部(b)组成,通常表示为a + bj形式,其中b的平方等于-1。
在实际编程中,需要对数字类型进行转换。例如,int()函数将转换参数X为普通整数,long()转换为长整数,float()用于浮点数,complex()则创建复数。复杂转换如complex(X, Y)允许将两个数值表达式转换为复数。
Python内建了一些处理数值类型的功能,但具体使用哪些取决于你的编程需求。以上就是关于Python四种数值类型的基本介绍,希望对你的编程有所帮助。
- 上一条:lua tostring源码
- 下一条:物业管家源码_物业管理软件源码