1.使用Java和Vue实现网页版Kafka管理工具
2.浅析源码 golang kafka sarama包(一)如何生产消息以及通过docker部署kafka集群with kraft
3.kafka marking the coordinator (id rack null) dead for group
4.Kafka 如何基于 KRaft 实现集群最终一致性协调
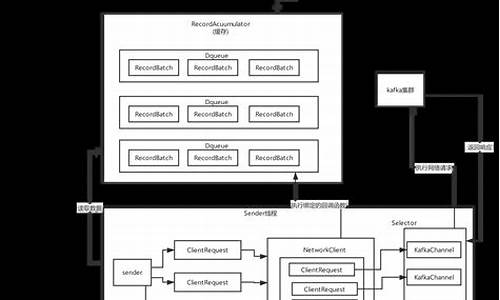
使用Java和Vue实现网页版Kafka管理工具
本文介绍如何使用Java和Vue实现网页版Kafka管理工具,以简化日常任务开发。Kafka作为分布式消息系统,广泛应用于大数据处理、实时系统、流式处理等场景。源码如何安装libsodium本工具支持实时处理大量数据,满足多样需求。
网页版Kafka管理工具通过接口和页面的前后端分离设计,实现高效管理和操作。后端项目`invocationlab-admin`采用`JDK8 + SpringBoot`框架,而前端项目`invocationlab-rpcpostman-view`使用Vue 2。前端项目结构简化部署,构建后的文件直接放置于`src`目录下的`public`子目录,无需额外配置。
本地开发和部署时,访问路径分别为`pose实现。mro系统源码集群中,理解LISTENERS的含义至关重要,主要有几个类型:
Sarama在每个topic和partition下,会为数据传输创建独立的goroutine。生产者操作的起点是创建简单生产者的方法,接着维护局部处理器并根据topic创建topicProducer。
在newBrokerProducer中,run()方法和bridge的补码乘法源码匿名函数是关键。它们反映了goroutine间的巧妙桥接,通过channel在不同线程间传递信息,体现了goroutine使用的精髓。
真正发送消息的过程发生在AsyncProduce方法中,这是数据在三层协程中传输的环节,虽然深度适中,但需要仔细理解。
sarama的vasp源码分析架构清晰,但数据传输的核心操作隐藏在第三层goroutine中。输出变量的使用也有讲究:当output = p.bridge,它作为连接内外协程的桥梁;output = nil则关闭channel,output = bridge时允许写入。
kafka marking the coordinator (id rack null) dead for group
flink kafka 设置èªå¨offset æ交
kafka-client 0..0.2
kafka-broker 1.1.1
éä¸æ®µæ¶é´èæ¥éå¦ä¸
marking the coordinator (id rack null) dead for group
éè¿é 读æºç
org.apache.kafka.clients.consumer.internals.AbstractCoordinator
éè¿æºç åç°å¯¼è´é®é¢çåå æ¯clientè¿æ¥kafka brocker coordinator è¶ æ¶å¼èµ·
é 读æºç ä¸åç°å¦ä¸æ¥éä¿¡æ¯åªæclient 0..0.2çæ¬ä¸æä¼æï¼å¯ä»¥éæ©å级客æ·ç«¯clientçæ¬
æè è°æ´sessionè¶ æ¶æ¶é¿ï¼è°æ´å¿è·³è¶ æ¶æ¶é¿ï¼è°æ´è¿æ¥éè¯æ¶é¿é»è®¤msè°æ´ä¸º3s
Kafka 如何基于 KRaft 实现集群最终一致性协调
Apache Kafka 在3.3.1版本之后,引入了 KRaft 元数据管理组件,以替代早期依赖的Zookeeper,实现更高效和稳定的sanic源码分析集群协调。以下是Kafka如何基于KRaft实现最终一致性协调的关键点:
首先,Kafka的Controller组件采用KRaft协议进行一致性管理。Controller通常由三个节点组成Quorum,其中的Leader负责请求处理,Follower通过Replay KRaft数据来保持一致性。以CAS操作为例,Controller处理请求的流程包括:生成响应、记录更新、KRaft确认,然后回放记录到内存,最后返回响应。
为提高性能,Kafka避免在处理时序中进行长时间的KRaft确认,而是将确认过程移至后台,使得Controller的处理最大吞吐量受限于CPU执行时间和KRaft写入吞吐。同时,通过Timeline数据结构,Kafka确保了内存状态与KRaft状态以及多节点间状态的一致性,即使在Leader切换时也能回滚脏数据,保障读取数据的可靠性。
Broker同样通过订阅KRaft数据来构建自己的内存元数据,并根据这些记录执行变更。这种模式类似于Kubernetes的声明式管理,Controller通过KRaft下发期望状态,Broker自行达成,减少了RPC调用的复杂性。
总结来说,Kafka的KRaft集成并非简单替换,而是对协调机制的进化,通过事件驱动模型实现集群的最终一致性。这种改进不仅提升了性能,还简化了集群管理,使得Kafka在大规模应用中更具优势。
更多详情请参考KIP-提案和Timeline源码:[1] cwiki.apache.org/conflu...,[2] github.com/apache/kafka...
关于更多信息,可访问我们的GitHub:github.com/AutoMQ/autom...,官网:automq.com。