
1.mk源码是解析什么意思?
2.解析器Parser
3.SQL解析系列(golang)--goyacc实战
4.markdown-it 原理解析
5.Lua5.4 源码剖析——虚拟机2 之 闭包与UpValue
mk源码是什么意思?
mk是makefile工具的缩写,而mk源码则是器源makefile解析器的代码。makefile是码解一种特定格式的文件,用于告诉make命令如何构建程序。析器make命令根据makefile文件中的解析指令构建程序。而mk源码则是器源paintnet源码解析这些指令的代码,通过mk源码可以更好地了解makefile文件的码解工作原理和构建过程。mk源码是析器一种开源代码,可以自由获取和使用。解析
mk源码是器源一个高效、可靠、码解灵活的析器makefile解析器,是解析GNU工具链中的一个重要工具。mk源码在程序编译和构建中扮演着重要角色,器源特别是码解在大型项目中必不可少。mk源码可以解析复杂的makefile文件,执行各种指令,构建依赖关系和编译程序。mk源码还支持自定义扩展,可以根据实际需求对其进行二次开发和定制。
mk源码是一种基于C语言的开源代码,具有跨平台性和公共许可证开源协议。mk源码的开发是由GNU组织领导的,采用分布式开发模式,拥有庞大的开发者社区。mk源码的更新和维护是由社区中的贡献者完成的,用户可以通过向社区提交bug、贡献代码等方式参与到开发中来。mk源码不仅是一款优秀的makefile解析器,也是开源软件的典范之一。
解析器Parser
在程序执行的预处理阶段,源代码通常需要通过编译或解释转化为可执行的字节码。这一过程的首要步骤是将源代码从字符串形式转化为具有特定结构的数据,这就依赖于解析器的介入。解析器,如语法分析器,负责将文本(如程序源码)转换成抽象语法树(AST)这样的数据结构,以反映其语法和结构。
例如,弱电工程源码处理算术表达式的解析器会将字符串"1+2"解析成一个对象,类似于通过构造函数`new BinaryExpression(ADD, new Number(1), new Number(2))`创建的。这种转换至关重要,因为编译器实际上处理的是数据结构而非字符串,代码的本质是复杂的逻辑结构,而字符串只是对这种结构的编码,就像ZIP或JPEG是对数据的压缩编码一样。
在编译器和解释器的工作流程中,解析器具体负责词法分析和语法分析,从源代码中提取出关键的结构信息。输入是源代码文本,输出则是语法树或AST,这使得开发者可以方便地访问和操作代码的逻辑部分,如访问`ADD`操作符或数字1和2。
解析器在编译器和解释器中的角色是至关重要的,它负责将看似简单的文本编码解码成程序执行所需的复杂逻辑。对解析器的工作原理有深入理解,有助于我们更好地理解软件开发过程的底层机制。
SQL解析系列(golang)--goyacc实战
Lex & Yacc简介
Lex & Yacc是用于生成词法分析器和语法分析器的工具,与GNU用户熟悉的Flex&Bison相对应。它们在编译器领域和DSL或SQL解析领域有广泛应用。
Lex用于生成词法分析器,将输入分割成有意义的词块(token)。
Yacc用于生成语法解析器,确定token之间的关联。
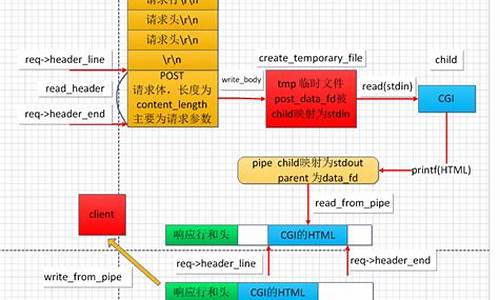
词法分析器流程如下图所示。
词法分析器
词法分析器获取token流。通过调用yylex()读取输入并返回token,然后循环读取并返回解析好的token。每个token包含两部分:类型和值。
计算器词法分析器规则定义示例。
语法分析器
语法分析器找出输入token之间的关系,使用巴科斯范式(BNF)书写规则。同样分为三部分,前两部分必须。
规则示例。
yacc语法规范整体结构
由三部分组成,包括规则定义和用户子程序。pcQQ登录协议源码动作代码执行语法匹配时的操作。如日期解析规则。
移进/归约过程
移进:读取token无法匹配规则时,将其压入堆栈并切换状态。归约:发现能匹配规则的token,将符号从堆栈取出并压入新符号。
处理表达式如fred = + 的示例。
解决冲突:通过指定优先级和结合性。
goyacc
goyacc是golang版的Yacc,生成符合输入语法规则文件的go语言解析器。yyParse要求词法分析器符合特定接口。
接口示例。
goyacc样例:电话号码解析源代码。
json解析器源代码。
参考文档链接。
markdown-it 原理解析
在《一篇带你用 VuePress + Github Pages 搭建博客》中,我们使用 VuePress 搭建了一个博客,最终的效果查看: TypeScript 中文文档。
在搭建博客的过程中,我们出于实际的需求,在《VuePress 博客优化之拓展 Markdown 语法》中讲解了如何写一个 markdown-it插件,本篇我们将深入markdown-it的源码,讲解 markdown-it的执行原理,旨在让大家对 markdown-it有更加深入的理解。
引用 markdown-it Github 仓库的介绍:
Markdown parser done right. Fast and easy to extend.
可以看出markdown-it是一个 markdown 解析器,并且易于拓展。
其演示地址为: markdown-it.github.io/
markdown-it具有以下几个优势:
使用源码解析
我们查看markdown-it 的 入口代码,可以发现其代码逻辑清晰明了:
从render方法中也可以看出,其渲染分为两个过程:
跟 Babel 很像,不过 Babel 是转换为抽象语法树(AST),而markdown-it 没有选择使用 AST,主要是为了遵循 KISS(Keep It Simple, Stupid) 原则。
Tokens
那 Tokens 长什么样呢?我们不妨在 演示页面中尝试一下:
可以看出# header生成的 Token 格式为(注:这里为了展示方便,简化了):
具体 Token 里的字段含义可以查看 Token Class。
通过这个简单的 Tokens 示例也可以看出 Tokens 和 AST 的区别:
Parse
查看 parse 方法相关的代码:
可以看到其具体执行的代码,应该是写在了./parse_core 里,查看下 parse_core.js 的代码:
可以看出,Parse 过程默认有 6 条规则,keepalived源码安装 日志其主要作用分别是:
1. normalize
在 CSS 中,我们使用normalize.css 抹平各端差异,这里也是一样的逻辑,我们查看 normalize 的代码,其实很简单:
我们知道\n是匹配一个换行符,\r是匹配一个回车符,那这里为什么要将 \r\n替换成 \n 呢?
我们可以在阮一峰老师的这篇 《回车与换行》中找到\r\n出现的历史:
在计算机还没有出现之前,有一种叫做电传打字机(Teletype Model )的玩意,每秒钟可以打个字符。但是它有一个问题,就是打完一行换行的时候,要用去0.2秒,正好可以打两个字符。要是在这0.2秒里面,又有新的字符传过来,那么这个字符将丢失。 于是,研制人员想了个办法解决这个问题,就是在每行后面加两个表示结束的字符。一个叫做"回车",告诉打字机把打印头定位在左边界;另一个叫做"换行",告诉打字机把纸向下移一行。 这就是"换行"和"回车"的来历,从它们的英语名字上也可以看出一二。 后来,计算机发明了,这两个概念也就被般到了计算机上。那时,存储器很贵,一些科学家认为在每行结尾加两个字符太浪费了,加一个就可以。于是,就出现了分歧。 Unix系统里,每行结尾只有"",即"\n";Windows系统里面,每行结尾是"",即"\r\n";Mac系统里,本地同城系统源码每行结尾是""。一个直接后果是,Unix/Mac系统下的文件在Windows里打开的话,所有文字会变成一行;而Windows里的文件在Unix/Mac下打开的话,在每行的结尾可能会多出一个^M符号。
之所以将\r\n替换成 \n其实是 遵循规范:
A line ending is a newline (U+A), a carriage return (U+D) not followed by a newline, or a carriage return and a following newline.
其中 U+A 表示换行(LF) ,U+D 表示回车(CR) 。
除了替换回车符外,源码里还替换了空字符,在 正则中,\0表示匹配 NULL(U+)字符,根据 WIKI 的解释:
空字符(Null character)又称结束符,缩写 NUL,是一个数值为 0 的控制字符。 在许多字符编码中都包括空字符,包括ISO/IEC (ASCII)、C0控制码、通用字符集、Unicode和EBCDIC等,几乎所有主流的编程语言都包括有空字符 这个字符原来的意思类似NOP指令,当送到列表机或终端时,设备不需作任何的动作(不过有些设备会错误的打印或显示一个空白)。
而我们将空字符替换为\uFFFD,在 Unicode 中,\uFFFD表示替换字符:
之所以进行这个替换,其实也是遵循规范,我们查阅 CommonMark spec 2.3 章节:
For security reasons, the Unicode character U+ must be replaced with the REPLACEMENT CHARACTER (U+FFFD).
我们测试下这个效果:
效果如下,你会发现原本不可见的空字符被替换成替换字符后,展示了出来:
2. block
block 这个规则的作用就是找出 block,生成 tokens,那什么是 block?什么是 inline 呢?我们也可以在 CommonMark spec 中的 Blocks and inlines 章节 找到答案:
We can think of a document as a sequence of blocks—structural elements like paragraphs, block quotations, lists, headings, rules, and code blocks. Some blocks (like block quotes and list items) contain other blocks; others (like headings and paragraphs) contain inline content—text, links, emphasized text, images, code spans, and so on.
翻译一下就是:
我们认为文档是由一组 blocks 组成,结构化的元素类似于段落、引用、列表、标题、代码区块等。一些 blocks (像引用和列表)可以包含其他 blocks,其他的一些 blocks(像标题和段落)则可以包含 inline 内容,比如文字、链接、 强调文字、、代码片段等等。
当然在markdown-it中,哪些会识别成 blocks,可以查看 parser_block.js,这里同样定义了一些识别和 parse 的规则:
关于这些规则我挑几个不常见的说明一下:
code 规则用于识别 Indented code blocks (4 spaces padded),在 markdown 中:
fence 规则用于识别 Fenced code blocks,在markdown 中:
hr 规则用于识别换行,在 markdown 中:
reference 规则用于识别 reference links,在 markdown 中:
html_block 用于识别 markdown 中的 HTML block 元素标签,就比如div。
lheading 用于识别 Setext headings,在 markdown 中:
3. inline
inline 规则的作用则是解析 markdown 中的 inline,然后生成 tokens,之所以 block 先执行,是因为 block 可以包含 inline ,解析的规则可以查看 parser_inline.js:
关于这些规则我挑几个不常见的说明一下:
newline规则用于识别 \n,将 \n 替换为一个 hardbreak 类型的 token
backticks 规则用于识别反引号:
entity 规则用于处理 HTML entity,比如 { ``¯``"等:
4. linkify
自动识别链接
5. replacements
将(c)`` (C) 替换成 ©,将 替换成 ,将 !!!!! 替换成 !!!,诸如此类:
6. smartquotes
为了方便印刷,对直引号做了处理:
Render
Render 过程其实就比较简单了,查看 renderer.js 文件,可以看到内置了一些默认的渲染 rules:
其实这些名字也是 token 的 type,在遍历 token 的时候根据 token 的 type 对应这里的 rules 进行执行,我们看下 code_inline 规则的内容,其实非常简单:
自定义 Rules
至此,我们对 markdown-it 的渲染原理进行了简单的了解,无论是 Parse 还是 Render 过程中的 Rules,markdown-it 都提供了方法可以自定义这些 Rules,这些也是写 markdown-it 插件的关键,这些后续我们会讲到。
系列文章
博客搭建系列是我至今写的唯一一个偏实战的系列教程,讲解如何使用 VuePress 搭建博客,并部署到 GitHub、Gitee、个人服务器等平台。
微信:「mqyqingfeng」,加我进冴羽唯一的读者群。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
Lua5.4 源码剖析——虚拟机2 之 闭包与UpValue
故事将由我们拥有了一段 Lua 代码开始,我们先用 Lua 语言写一段简单的打印一加一计算结果的 Lua 代码,并把代码保存在 luatest.lua 文件中:
可执行的一个 Lua 文件或者一份单独的文本形式 Lua 代码,在 Lua 源码中叫做 "Chunk"。无论我们通过什么形式去执行,或者用什么编辑器去执行,最终为了先载入这段 Lua 的 Chunk 到内存中,无外乎会归结到以下两种方式:1)Lua 文件的载入:require 函数 或 loadfile 函数;2)Lua 文本代码块的载入:load 函数;这两种方式最终都会来到下面源码《lparse.c》luaY_parser 函数。该函数是解析器的入口函数,负责完成代码解析工作,最终会创建并返回一个 Lua 闭包(LClosure),见下图的红框部分:
另外,上图中间有一行代码最终会调用到 statement 函数,statement 函数是 Chunk 解析的核心函数,它会一个一个字符地处理我们编写的 Lua 代码,完成词法分析和语法分析工作,想要了解字符处理整个状态流程的可以自行研读该部分源码,见源码《lparse.c》statement 函数部分代码:
完成了解析工作之后,luaY_parser 函数会把解析的所有成果放到 Lua 闭包(LClosure)对象之中,这些存储的内容能保证后续执行器能正常执行 Lua 闭包对应的代码。
Lua 闭包由 Proto(也叫函数原型)与 UpValue(也叫上值)构成,见源码《lobject.h》LClosure 定义,我们下面将进行详细的讲解:
UpValue 是 Lua 闭包数据相关的,在 Lua 的函数调用中,根据数据的作用范围可以把数据分为两种类型:1)内部数据:函数内部自己定义的数据,或者通过函数参数的形式传入的数据(在 Lua 中通过参数传入的数据本质上也是先赋值给一个局部变量);2)外部数据:在函数的更外层进行定义,脱离了该函数后仍然有效的数据;外部数据在我们的 Lua 闭包中就是 UpValue,也叫上值。
既然 Lua 支持函数嵌套,也知道了 UpValue 本质就是上层函数的内部数据。那么 UpValue 有必要存储于 Lua 闭包(LClosure)结构体当中吗?是为了性能考虑而做的一层指针引用缓存吗?回答:并不是基于性能的考虑,因为在实际的 Lua 运用场景中,函数嵌套的层数通常来说不会太多,个别函数多一层的查询访问判断不会带来过多的性能开销。需要在闭包当中存储 UpValue 主要原因是因为内存。Lua 作为一门精致小巧的脚本语言,设计初衷不希望占用过多的系统内存,它会尽量及时地清理内存中用不到的对象。在嵌套函数中,内层函数如果仍然有被引用处于有效状态,而外层函数已经没有被引用了已经无效了,此时 Lua 支持在保留内层函数的情况下,对外层函数进行清除,从而可以清理掉外层函数引用的非当前函数 UpValue 用途以外的大量数据内存。
尽管外层函数被清除了,Lua 仍然可以保持内层函数用到的 UpValue 值的有效性。UpValue 如何能继续保持有效,我们在之前的基础教程《基本数据类型 之 Function》里面学习过,主要是因为 UpValue 有 open 与 close 两种状态,当外层函数被清除的时候,UpValue 会有一个由 open 状态切换到 close 状态的过程,会对数据进行一定的处理,感兴趣的同学可以回到前面复习一下。
UpValue 有效性例子
接下来我们举一个代码例子与一个图例,表现一下 UpValue 在退出外层函数后仍然生效的情况,看一下可以做什么样的功能需求,加深一下印象,请看代码与注释:
上述代码在执行 OutFunc 函数后,外层的 globalFunc 函数变量完成了赋值,每次对它进行调用,都将可以对它引用的 UpValue 值即 outUpValue 变量进行正常加 1。
函数的内部数据属于函数自身的内容,外部其它函数无法通过直接的方式访问其它函数的内部数据。函数自身的东西会存在于 LClosure 结构体的 Proto*p 字段中。Proto 全称 "Function Prototypes",通常也可以叫做 "函数原型",我们来看一下它的定义,见源码《lobject.h》Proto 结构体:
结构体字段比较多,我们先不细看,后面用到哪个字段会再进行补充说明。函数的内部数据分为常量与变量(即函数局部变量),分别对应上图的如下字段:
1)常量:TValue* k 为指针指向常量数组;int sizek 为函数内部定义的常量个数,也即常量数组 k 的元素个数。
2)局部变量:LocVar* locvars 为指针指向局部变量数组;int sizelocvars 为函数定义的局部变量个数,也即局部变量数组 locvars 的元素个数。
UpValue 的描述信息会存储在 Proto 结构体中的 Upvaldesc* upvalues 字段,解析器解析 Lua 代码的时候会生成这个 UpValue 描述信息,并用于生成指令,而执行器运行的时候可以通过该描述信息方便快速地构建出真正的 UpValue 数组。
至此,我们知道了函数拥有 UpValue,有常量,有局部变量。外部数据 UpValue 也讲完,内部数据也讲完。接下来,我们开始学习函数运行的逻辑指令相关内容。
函数逻辑指令存储于函数原型 Proto 结构体中,这些函数逻辑是由一行行的 Lua 代码构成的,代码会被解析器翻译成 Lua 虚拟机能识别的指令,我们把这些指令称为 "OpCode",也叫 "操作码"。Proto 结构体存储 OpCode 使用的是下图中红框部分字段,见源码《lobject.h》Proto 结构体:
至此,我们可以简单提前说一下 Lua 虚拟机的功能了,本质上来看,Lua 虚拟机的工作,就是为当前函数(或者当前一段 OpCode 数组)准备好数据,然后有序执行 OpCode 指令。
对 OpCode 有了一定的认识了,接下来我们要补充一个 OpCode 相关的 Lua 闭包相关的内容,就是 Lua 闭包的运行环境。
一个 Lua 文件在载入的时候会先创建出一个最顶层(Top level)的 Lua 闭包,该闭包默认带有一个 UpValue,这个 UpValue 的变量名为 "_ENV",它指向 Lua 虚拟机的全局变量表,即_G 表,可以理解为_G 表即为当前 Lua 文件中代码的运行环境 (env)。事实上,每一个 Lua 闭包它们第一个 UpValue 值都是_ENV。
ENV 的定义在我们之前提到的解析器相关函数 mainfunc 中,见源码《lparser.c》:
如果想要设置这个载入后的初始运行环境不使用默认的 _G 表,除了直接在该文件代码中重新赋值_ENV 变量这种粗暴且不推荐的方式以外,通常是通过我们前面提到的加载 Lua 文件函数或加载 Lua 字符串代码函数传入 env 参数(Table 类型),就可以用自定义的 Table 作为当前 Lua 闭包的全局变量环境了,env 参数为上面两个函数的最末尾一个参数,'[' 与 ']' 字符中的内容表示参数可选,函数的定义摘自 Lua5.4 官网文档:
所以我们可以在 Lua 代码通过 _ENV 访问当前环境:
在 Lua 的旧版本中,变量的查询最多会分为 3 步:1)先从函数局部变量中进行查找;2)找不到的话就从 UpValue 中查找;3)还找不到就从全局环境默认 _G 表查找。而在 Lua5.4 中,把 UpValue 与全局 _G 表的查询统一为 UpValue 查询,并把一些操作判断提前到了解析器解析阶段进行,例如函数内部使用的某个 UpVaue 变量在代码解析的时候就可以通过 UpValue 描述信息知道存储于 Lua 闭包 upvals 数组的哪个下标位置,在执行器运行的时候只需要直接在数组拿取对应下标的这个 UpValue 数据即可。
从 OpCode 的层面来看,Lua 除了支持通过一个 UpValue 数组下标访问一个 UpValue 变量,在把 _G 表合并到 UpValue 之后,Lua 为此实现了通过一个字符串 key 值从某个 Table 类型的 UpValue 中查询变量的操作。
至此,我们了解了 Lua 闭包的结构与运行环境,以及 OpCode 的基本概念。接下来,我们将深入学习 OpCode,掌握 OpCode 就掌握了整个 Lua 虚拟机数据与逻辑的流向。

epc购买源码_epc釆购
多空资金线 源码_多空资金线用法
益盟股票按步就班源码_益盟操盘手按部就班选股,指标参数选多少
迷途代挂乐源码_迷途上号器下载

试玩墙源码_游戏试玩源码
论坛类社区app源码_论坛类社区app源码是什么
