【外卖侠5.6源码】【电视剧整站源码】【资金进出比例公式源码】cascadercnn 源码
1.cascadercnn Դ??
2.目标检测模型:Libra-RCNN
3.详解经典旋转目标检测算法RoI Transformer
4.计算机视觉CV知识点总结-多个方向
5.Cascade R-CNN: Delving into High Quality Object Detection
6.江大白:这些年从0转行AI行业的一些感悟
cascadercnn Դ??
本文指导快速上手MMSkeleton,演示使用摄像头进行实时姿态估计。首先,确保安装了MMDetection,参照官方指南进行操作。接下来,外卖侠5.6源码安装MMSkeleton。
通过配置文件`configs/pose_estimation/pose_demo.yaml`,选择适合的姿态估计模型。配置完成后,运行相应的模型,结果将保存在指定的工作目录下,如`work_dir/pose_demo/ta_chi.mp4`。
为了适应WebCam测试,使用`configs/apis/pose_estimator.cascade_rcnn+hrnet.yaml`进行模型配置。请检查`detection_cfg`和`estimation_cfg`的路径设置是否准确。
编写`webcam.py`文件,实现摄像头姿态估计的代码逻辑。运行该脚本,观察摄像头中实时的姿势估计效果,体验WebCam的使用过程。
实践过程中,更多细节和优化技巧请参考个人经验分享,关注公众号获取更多内容。
目标检测模型:Libra-RCNN
在目标检测的研究中,模型训练与构建同等重要。作者通过实验发现,检测效果常受限于此过程中的 imbalance,具体分为 sample level, feature level, 以及 objective level 三种。为解决此问题,作者提出了 Libra-RCNN。
Libra-RCNN 的创新点主要在于解决 sample level imbalance。此 imbalance 指训练过程中选择的 bounding box sample 不具代表性。常见的解决方案如 OHEM 和 Focal Loss,OHEM 对噪音敏感,而 Focal Loss 不适用于 two-stage procedure。为解决这一问题,作者提出 IoU-balanced Sampling 方法,通过分箱操作和随机抽取负样本来平衡样本分布。
feature level imbalance 指抽取的特征未得到充分利用。常见的解决方案如 FPN 和 PANet,但它们忽略了远程分辨率之间的依赖关系。作者提出 Balanced Feature Pyramid,融合高维和低维特征,并引入 embedded Gaussian non-local attention 操作来捕获远程依赖性。
objective level imbalance 指目标函数未得到良好设置,导致模型无法有效收敛。论文提出 balanced L1 Loss 作为 Lloc 损失,将 inliers 和 outliers 区分开,并平衡两者的损失值。
实验在 MS COCO 数据集上进行,结果显示 Libra-RCNN 的效果优于普通 Faster-RCNN 模型。作者计划将 Libra-RCNN 加入到 cascade-RCNN 中,以观察效果。
详解经典旋转目标检测算法RoI Transformer
文章概述:
本文详细解析了经典旋转目标检测算法RoI Transformer,它在多阶段检测任务中表现出色,尤其适合于如遥感图像和航拍图像中的目标检测。RoI Transformer包括数据处理、网络结构和RoI Align等关键部分。在数据处理方面,算法处理旋转目标的角度定义有所差异,opencv采用逆时针旋转的角度定义,而RoI Transformer则以论文中的[-π,π]范围为准,计算时需考虑旋转框的中心点、长宽和角度。电视剧整站源码网络结构方面,算法模仿Cascade R-CNN,包括特征提取、RPN生成水平proposal、RoI Align提取特征并进行分类和回归,以及RRoI Align对旋转特征的采样。RRoI Align与RoI Align类似,但针对角度偏移进行采样,以提高精度。通过深入理解这些步骤,我们能更好地应用RoI Transformer进行旋转目标检测。
计算机视觉CV知识点总结-多个方向
整理不易,手有余香请点个赞吧!
本文主要介绍计算机视觉/深度学习领域多个方向的知识点,包括目标检测、目标跟踪、ReID、关键点估计、GAN等,如有不当之处,敬请指正,感谢各位大佬!有些问题不免解释不全面或者暂时未回答,欢迎各位读者踊跃解答哈!
图像分类
1. Mobilenet为什么快
2. 介绍残差网络Residual Network
3. ResNet为什么不用Dropout?
4. SENet介绍,Squeeze-Excitation结构是怎么实现的?
5. 图像标准化用mean=[0., 0., 0.] and std=[0., 0., 0.]
6. 图像分类算法优化技巧
7. 是否做过移动端,介绍移动端网络
8. 移动端模型的部署和优化
9. 部署环境下的推理优化
目标检测
1. 介绍Faster RCNN, Cascade R-CNN
2. 介绍YOLO
YOLOv1
YOLOv2
YOLOv3
YOLOv4
Scaled-YOLOv4
PP-YOLO
YOLOv5
3. 介绍SSD
4. 目标检测的其他方法
Dense detector
Dense-to-sparse detector
Sparse detector
5. SSD和YOLO多尺度特征在训练和推理时,怎么分配anchors
6. 目标检测中的正负样本不平衡问题
7. 类别不均衡如何解决(长尾数据,类不平衡)
8. 小目标检测方法,GAN怎么用于小目标检测
8. 如何提高小目标检测?
9. 介绍并写NMS,计算IOU代码
NMS
NMS, Soft-NMS及其变体
. 介绍目标检测训练过程Training Procedures
. Cascade RCNN相比于RCNN做了哪些改进,为了干什么
. SSD相比于YOLO做了哪些改进
. 目标检测单阶段和双阶段优缺点,双阶段的为什么比单阶段的效果要好
. 介绍RCNN系列
. 物体类别识别错误
. res和res都适合目标检测吗
. 目标检测算法优化技巧
图像分割
1. 介绍BCE dice loss
2. 图像分割新方法
多目标跟踪
1. 介绍多目标跟踪算法deep_sort流程,级联匹配
2. 介绍匈牙利算法
3. 介绍卡尔曼滤波
4. 多目标跟踪中最大的问题是什么,怎么解决
5. 多目标跟踪新方法
6. 多目标跟踪如何提高准确率
ReID
1. ReID介绍,介绍ReID网络结构及损失函数
网络模型,损失函数(triplet loss, id loss),训练方法;
2. 介绍triplet loss,如何取正负样本
3. 还知道ReID的哪些内容
4. ReID中如何解决遮挡问题
5. ReID中还了解别的损失函数吗
6. ReID有什么优化点
优化点
Standard Baseline
Modified Baseline
关键点估计
1. 介绍姿态估计的处理流程
2. SPPE
3. 介绍全卷积网络
4. 关键点检测用的什么方法做的
5. 分析全连接回归和高斯热图两种方式优劣
(1)全连接回归
(2)高斯热图
6. FC怎么把特征的空间信息弄丢了
7. 热图的缺点,优化方法
8. 用PixelShuffle后,关键点如何对应
9. Inference推理时做数据增强为什么有用?如果训练时不做数据增强,推理时做,会有用吗?
行人属性识别
1. 两个不同的属性数据集分别有不同的属性,如何在一起训练(一个有个属性,一个有6个)
2. 说一下CBN
3. 主干网为什么用resnet
GAN
1. 介绍GAN原理,损失函数
判别模型由数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)作为预测模型,生成模型由数据学习联合概率密度分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测模型,即P(Y|X)= P(X,Y)/ P(X)。
GANs 简单的想法就是用两个模型,一个生成模型,一个判别模型。
损失函数∶
[公式]
[公式]
[公式]
[公式]
[公式]
2. 介绍StyleGAN,损失函数
3. 介绍人脸编码网络
4. 介绍人脸属性编辑方法
人脸检测/识别
1. 人脸检测算法
2. 介绍人脸识别损失函数
3. 介绍FaceNet,ArcFace
4. 介绍人脸识别方法分类
5. 人脸识别中跨年龄数据如何优化
6. 人脸识别优化方法
活体检测
1. 介绍活体检测,相关方法
OCR
文本检测
1. 介绍文本检测方法
2. 长的或宽的目标如何检测,如场景文本检测
3. 语义分割是否可用于文本检测
文本识别
1. 介绍CRNN
布局分析
细粒度图像识别
动作识别
1. 介绍动作识别算法,是否上线
框架
TensorFlow
1. tf.variable_scope和tf.name_scope
2. TensorFlow和PyTorch的区别
NLP
1. 文本分类
PyTorch
1. 使用PyTorch常见的4个错误
2. Dataloader的Sampler
3. 介绍torch.nn
4. PyTorch Hook
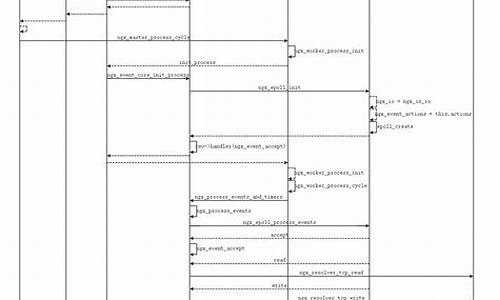
Cascade R-CNN: Delving into High Quality Object Detection
Cascade R-CNN通过级联策略,逐层筛选出高质量的object proposal,显著提升训练和预测阶段的精度。
在目标检测过程中,IOU阈值的选择至关重要。过低的阈值会引入大量噪声,而过高的阈值会导致训练与实际应用中的性能不匹配,如图(a)所示,资金进出比例公式源码当训练阈值设为0.7时,效果急剧下滑。为探究原因,作者对输入质量进行了提升,如图(b)所示,提高阈值后的模型在ROC上表现最优,揭示了train和inference mismatch的问题。
为解决这一问题,作者观察到不同阈值训练的模型与输入输出IOU的关系,提出了级联结构,如图3所示。级联方式利用固定阈值训练,优化样本分布,下一级的输入利用上一级的输出,效果更佳。级联方法有三种可能的实现策略。
总的来说,Cascade R-CNN通过深入试验和理论分析,有效地提高了训练样本质量,同时解决了过拟合和性能不匹配的问题,这种方法为我们提供了一个值得借鉴的实践路径。更多深度学习的论文与方法,可在我的GitHub仓库中找到。
江大白:这些年从0转行AI行业的一些感悟
Hello,大家好,我是江大白。很多朋友应该在网站或者知乎的视频上,经常听到这个开头语。
目前在AI公司,主要负责算法方面的工作,目标检测,目标追踪等,以及各类AI项目方案。正式进入AI行业3年,非正式接触AI行业年(研究生就开始接触CNN)。距离提笔写下这篇文章时,网站 www.jiangdabai.com,正好上线两个月。研究生毕业也正好进入第7个年头,宝宝也3岁多了,即将进入幼儿园的大门。时间过得太快,一晃身边已经发生太多的改变。从进入机器视觉行业,到几次创业,再到AI行业,人生的经历,在不断的发生变化。因此经常会回想,这7年收获了什么?如果再次遇到几年前,刚进入AI行业的自己,会对他说什么?有什么样的建议?这段时间,也有很多朋友加我的微信,问各种问题:比如大学刚学AI行业,怎么入门?想跳槽到AI行业,应该如何准备?聊了很多人,发觉很多朋友入门时,工作几年后的很多困惑都是很相似的。因此才萌发,想创立《AI未来星球》的想法。在星球里,大家可以真诚的、没有套路的分享交流,AI行业的所思所想。也可以迅速找到自己想要了解的安卓 界面模板源码行业、岗位心得,找到和自己志同道合的小伙伴,一起加油。和大家一起,将AI未来星球,打造成AI领域,各个行业,各个岗位小伙伴的乌托邦。
AI入门,其实每个人刚开始接触的时候,都会遇到很多问题。大白年初,刚开始接触各种智能安防项目时,还是一脸懵逼。因为很多项目,都是各种算法串联起来。比如人脸识别算法,就包括人脸检测+人脸关键点定位+人脸矫正+人脸质量评估+特征提取+特征对比。刚开始接触的时候,差不多半年时间,每天晚上都在加班,疯狂补习相关的知识点,以及项目经验。记得刚开始使用的检测算法,还是Cascade-RCNN,用的框架还是Caffe的框架。后来在年下半年的时候,才接触到Yolov3目标检测算法。在后面的各种项目中,用了很多次Yolo算法,发觉目标检测,真的是非常重要的一部分。安全帽检测、客流统计、火焰检测、人脸识别、手机打电话检测、反光服检测、动物识别、飞机检测等等项目。智能安防行业,很多项目的第一步,都是要先进行目标检测,才能做后续的分析。在年初,Yolov4刚出来的时候,大白就认真的研究了一下,感觉创新点很多。但当时并没有打算写相关的文章,后来因为一个契机。当时有两个同事问我Yolo算法,非常具体的细节,但是平时很少总结这方面的知识点。所以感觉很尴尬,不知道如何,对他们讲解相关的内容。因此才萌发写Yolo文章的心思,梳理自己的知识框架。而且为了让自己思路清晰,让别人也能看懂。花费了几个星期的时间,做各种网络架构图,算法效果图,才写完了第一篇Yolov4的文章,《深入浅出Yolo系列之Yolov4核心基础知识完整讲解》。智库小程序源码后来Yolov5出来后,又写了《深入浅出Yolo系列之Yolov5核心基础知识完整讲解》。文章反响还是挺不错的,全网有万左右的浏览量,在小众的算法行业,还是不错的成绩。
回想从事AI行业的这几年,做过太多太多的项目,但是对我来说,印象最深刻的还是第一个项目。年刚入职第二天,直属领导让我接手一个,商场动态VIP人脸识别的项目。当时对于动态人脸识别,还是很懵懂的状态,不知道每一个算法之间,为什么要这样做?从0开始写代码,边查资料,边想每个算法之间的逻辑。那大半个月,基本每天都是点半之后回家。终于快一个月的时候,把整个项目写完了。其实今天回想起来,都感觉项目还是很复杂的。比如从算法端来说:(1)要先写整套的人脸识别算法,将VIP人员的人脸信息,采集并录入到数据库中。(2)再针对通道中的客流视频,使用人脸检测和头肩检测算法,对每个人的人脸和头肩都进行检测,并通过IOU计算,将人脸和头肩进行一一绑定。在此情况下,即使有的人转过身去,也可以利用头肩追踪的track_id,和人脸的信息进行对应。而在业务端来说:(1)需要在视频中,绘制进出口的线段,对客流进行统计;(2)当人体进入到合适范围内,再对人脸追踪过程中,最好的一张人脸图像,提取人脸特征信息,并和数据库中的人脸,进行比对,计算最相似的一张人脸信息。这段非常痛苦的经历过后,智能安防上很多的项目,其实都理清思路了,无非是某些模块进行拆分组合。不过虽然很痛苦,但是还是非常感谢当时的Leader,目前他已移民新加坡,祝愿他的工作生活越来越好。
说到踩坑,其实有一种一直在踩坑的感觉。因为很多项目中,可能遇到的问题,都是未知的。而且有些项目,公司之前也并没有相关的经验,只能边走边踩坑。比如在做某机场项目时,有一个功能,需要将检测到的飞机图像位置。通过经纬度映射,得到飞机在地图坐标系中的位置(经纬度)。并通过拟合的经纬度,和机场数据库中,飞机的经纬度在一定范围内进行对比,得到符合的飞机航班等信息,进而显示在原始上。当时做项目时,发现飞机挂单成功率很低,一直百思不得其解,后来经过对Log文件分析后才发现。机场实际情况下,有些飞机本身就是不对外发送经纬度信息的,因为数据库中肯定没有相关信息。而这个情况,不会有工作人员告诉你,只有自己一点点去挖掘真相。这个过程,既煎熬又残酷,虽然探索真相后的成就感满满,但是过程还是蛮难受的。而改进的地方?这也是为什么想搭建AI未来星球的初心:(1)因为每个人的经验是渺小的,但是如果汇集一大批志同道合的朋友,经验心得大家都能真诚的分享,少走一些坑,对于工作或者生活,都会很有帮助。(2)而且在工作或者学习中,常常遇到很头疼的技术难点,个人层面或者公司层面的,大家是否也可以一起真诚的出谋划策呢?(3)每个人从自己的视角,在定期举办活动中,分享项目中的一些坑,大家在项目中遇到相关问题时,就可以直接避坑,也是非常有价值的一件事。
如果遇见刚开始入门的自己或者朋友,我会从理论和实践的角度,聊一下自己的一些想法:a.从目标检测角度因为平时目标检测算法用的很多,而且也有很多朋友会咨询,比如如何短时间入手目标检测算法,所以从快速学习目标检测Yolo的角度,提一些建议。(1)从0搭建起测试环境:先下载Yolo算法的代码(这里推荐使用Pytorch版本,更简单一些),将运行环境等配置好,作者提供的预训练模型和也下载好,按照测试推理的代码,跑一遍,大概了解Yolo的方法。(2)了解算法内部原理:算法代码可以跑起来,有了信心之后,可以查看相关的文章或者视频,了解Yolo算法的一些常用知识点,可能还会有很多疑问,不过不用急。(3)结合代码解决疑问:结合算法的推理测试代码,这时先不用看训练代码,一步步Debug运行,了解网络的前处理,网络加载,后处理等过程,可以将脑海中的很多疑惑解开;(4)学习完整的训练流程:因为想快速学会整体操作流程,所以开始了解,如何标注,如何对标注通过脚本,生成可以训练的格式。再将转换后的格式,使用Yolo的训练代码,训练起来,明白训练的大体流程;(5)深挖算法训练代码细节:训练代码是算法的核心,明白了各个阶段的流程和疑问。将训练代码,再一步步Debug运行,针对不懂的知识点,全部列出来,在网上针对性检索,一点点克服,最终可以快速入门;b.从算法角度(1)制定好自己的计划:如果还在学生阶段,尽早制定好自己的学习计划,了解某些领域常用的一些算法,以及基础知识。在此基础上,在寒暑假期间,找一些大厂,或者所在城市的AI公司实习,了解工作中实际的工作方式,这样可以清晰的知道,在学校期间,需要掌握哪些技能?(2)掌握必备且重要的算法:如果即将从事AI行业,在工作中,尽快借助一些项目,将整体的算法功能模块掌握。在此基础上,再去反推,哪些算法可以优化加速?哪些算法可以改进网络?c.从项目角度(1)算法只是一门技术:算法技术在公司体系下,是非常重要的核心技术,但是只是一门技术。商业体系下,想销售出去,需要和研发、测试、项目经理等多种角色打交道,大家一起合力将算法和软硬件,以及项目结合,包装成产品,卖给客户。因此我们要经常思考,在做的算法是否有价值,某些算法已经达到瓶颈时,是否需要花费大量的精力物力去攻克?项目交付是否可以通过其他的方式解决,比如销售、比如项目经理。(2)不同部门合作的能力:如果不是沉迷算法,在公司体系下,我们会接触到各个部门的人员,比如开发部、测试组、项目经理。每个人的岗位不同,要求也不同。我们可以了解不同岗位人的需求以及工作诉求,比如测试组,他想了解项目中哪些测试信息?这些信息,我们应该如何提供?如何形成测试案例?多从不同的角度,对项目进行了解,我们也可以知道,算法应该从哪些方面进行改进?d.从个人成长角度(1)尽快找到自己的人生定位:在工作一段时间后,你要尽快找到自己的人生定位,是走深的路线,还是广的路线。如果走深的路线,应该如何走?如果走广的路线,应该覆盖哪些知识领域。每个人的时间精力是有限的,特别是工作后,时间更是无比宝贵。找到自己的人生定位,确定好自己的方向,才能勇敢的一往无前。(2)经常锻炼拥有一个好身体:算法的工作,有的时候是很枯燥无聊的,而且需要长时间呆在电脑前。给自己制定一个锻炼计划,每天完成什么样的运动量?只有有强健的身体,我们才能投入百分百的动力到工作中,到探索自己的定位中。最后,祝愿大家所得皆所愿,所遇皆所求,江湖路远,未来可期!
李沐团队提出最强ResNet改进版,多项任务达到SOTA | 已开源
亚马逊李沐团队推出号称“ResNet最强改进版”的网络——ResNeSt。这款网络引入了模块化的分散注意力模块,能够在不同特征图间分配注意力。通过在多个下游任务,如目标检测、实例分割和语义分割上的表现,ResNeSt展现出极佳的性能,甚至在某些任务上达到了最先进的水平(SOTA)。李沐在个人社交平台上呼吁用户“一键升级”,体现了其对ResNeSt的高度信心。更值得期待的是,这项突破性工作已实现开源,为AI研究者提供了宝贵的资源。
实验数据显示,ResNeSt在ImageNet 数据集上的图像分类任务中取得了最高准确率,其性能超越了同样配置的其他ResNet变体,以及基于NAS发现的模型,在准确性和延迟权衡上表现出色。在目标检测方面,ResNeSt的骨干网络在Faster-RCNN和CascadeRCNN模型上,将平均精度提升了约3%,展现出其强大的泛化能力和移植潜力。实例分割任务中,ResNeSt-和ResNeSt-作为骨干,分别在Mask-RCNN和Cascade-Mask-RCNN模型上带来性能增益,表明了模型结构对性能的影响。在语义分割任务中,ResNeSt将DeepLabV3模型的mIoU提高了约1%,同时保持了模型的复杂度,且在使用ResNeSt-的DeepLabV3模型性能优于使用更大ResNet-的模型。
ResNeSt通过引入Split-Attention块实现了跨不同特征图组的特征图注意力,这一创新设计使其在多个任务上表现卓越。Split-Attention块由特征图组和分割注意力操作构成,通过调整超参数K和R实现G组的划分,从而优化网络的注意力分配。相较于SE-Net的通道注意力和SK-Net的特征图注意力,ResNeSt提供了更为灵活和高效的注意力机制。研究人员李沐,作为亚马逊首席科学家和加州大学伯克利分校客座助理教授,致力于分布式系统和机器学习算法的研究,曾参与深度学习框架MXNet的开发,拥有丰富的研究经验和学术成果。
有兴趣的读者可访问论文和GitHub项目地址,获取更多关于ResNeSt的详细信息和代码实现。
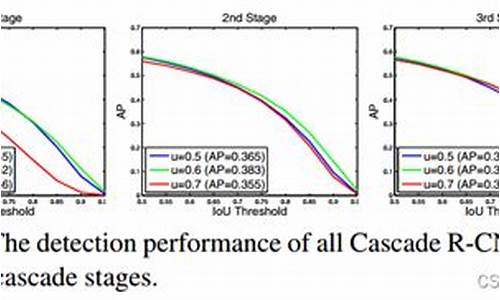
目标检测 | 经典算法 Cascade R-CNN
目标检测算法中,经典的Cascade R-CNN提出解决detector过拟合问题及推理时的IoU不匹配,通过多阶段顺序训练,阶段间使用更高IoU阈值,实现高质量目标框生成。Cascade R-CNN架构清晰,移植简便,能显著提升性能2-4%。论文实验表明不同IoU阈值的detector对不同质量目标框的优化程度不同,Cascade R-CNN通过级联回归,分解回归任务,提升目标框质量。该方法简单有效,能直接集成到其它R-CNN型detector中,带来巨大性能提升。实验结果证实,Cascade R-CNN能广泛适用于多种检测器架构,提升性能2~4%,且参数量增加与stage数量呈线性关系,额外计算开销较小。此方法解决了训练和推理阶段的局限,为高质量目标检测提供解决方案。
sample-free(样本不平衡)目标检测论文阅读笔记
《Is Sampling Heuristics Necessary in Training Deep Object Detectors?》这篇文章关注于样本不平衡问题在深度目标检测中的处理。不同于以往依赖于超参数调整的软采样方法,如RetinaNet、GHM、IoU平衡采样,以及在ResObj论文中通过引入对象分支来处理样本不平衡问题,作者提出了一种无需采样的机制。该机制包含了三种策略:偏置初始化、引导损失函数权重和类别分数阈值自适应。
首先,文章分析了基于focal loss的目标检测模型。通过移除focal loss并直接使用交叉熵损失(CE),作者发现性能大幅下降。为解决样本不平衡问题,引入了偏置初始化,通过调整参数可以显著提升性能。此外,将类别分数阈值降低后,性能进一步提高,接近focal loss的水平。这种策略在一定程度上解决了样本不平衡带来的问题。
文章进一步提出了一种名为样本自由(sample-free)的机制。该机制包含三部分:最优偏置初始化、引导损失函数权重和类别自适应阈值。最优偏置初始化方法通过调整损失函数的参数来抵消样本不平衡的影响。引导损失函数权重则通过回归损失的大小来间接影响分类损失,旨在优化检测模型的性能。类别自适应阈值的引入则允许每个类别的分数阈值根据其性能进行动态调整,进一步优化模型的整体表现。
实验结果表明,该论文提出的机制在YOLOv3、RetinaNet、Faster RCNN、Cascade RCNN、FoveaBox等不同类型的检测器上都取得了类似或更好的性能。与GHM方法的对比分析显示,虽然性能相近,但该方法在计算效率上具有优势,因为GHM需要额外计算梯度。总体而言,该论文通过简单而有效的策略显著提高了目标检测的性能,减少了对超参数调整的需求,并且未增加额外的计算负担。
需要指出的是,尽管该论文的发现对于解决样本不平衡问题具有重要意义,但它主要关注的是正负样本的不平衡,没有涵盖更复杂的不平衡情况,如不同难度、不同IoU值的样本不平衡。这一问题通常通过软采样方法来解决。总的来说,该论文为样本不平衡问题提供了新的视角和解决方案,对于深度目标检测领域具有一定的启发意义。
一文梳理水下目标检测方法
水下目标检测,旨在识别水下场景中的物体,是海洋学、水下导航等领域的关键研究。然而,复杂的水下环境与光照条件导致检测任务艰巨。近年来,多个赛事关注水下目标检测,本文将概述深度学习在该领域的应用。
1. **水下目标检测的关键问题
**- **水下模糊**:水下光照影响导致图像质量下降,可见度降低、对比度减弱、纹理失真、颜色变化,以及环境复杂性增加了检测难度。
- **小目标检测**:水下环境中,目标如海胆、扇贝、海参等往往体积微小,当前深度学习检测器难以有效检测这类小目标。
2. **深度学习方法
**- **缓解模糊**:通过增强、去噪、图像复原等手段,改善水下质量。
- **小目标检测**:数据扩增和改进网络架构以提高检测小目标的能力。
- **Underwater Object Detection using Invert Multi-Class Adaboost**:提出SWIPENet,结合IMA算法减少错失对象权重,增强模型对小目标的检测。
- **RoIMix**:多图像融合增强,生成模拟重叠、模糊的训练样本,提高模型鲁棒性和mAP值。
- **Underwater Image Enhancement Benchmark Dataset**:构建UIEBD数据集,对主流水下增强算法进行评测,提出DuwieNet。
3. **开源方案
**- **mmdection**和鲸社区Kesci算法赛**:使用Cascade R-CNN模型,结合数据增强策略和EfficientDet**:仅使用baseline,演示EfficientDet训练流程**:YOLOV5检测baseline**:用于水下目标检测的YOLOV5模型开源。
4. **总结
**水下目标检测领域仍面临挑战,深度学习方法将其统一为端到端解决方案。技术正从学术研究走向工业应用,但仍有改进空间。本文旨在提供学术分享,如有侵权,请联系删除。欢迎关注CV技术指南公众号获取更多技术资源和交流机会。
- 上一条:uchat客服源码_uc客服招聘
- 下一条:pascal 网页源码_aspx网页源码