1.编写好c语言源程序后如何进行编译和运行
2.程序源代码经过编译得到的源码编译目标程序不可以
3.eclipse重新编译源代码
4.从源码build Tensorflow2.6.5的记录
5.怎么用反编译工具ILSpy反编译源码
6.c#源码如何反编译?
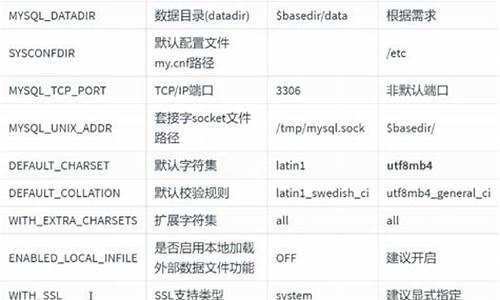
编写好c语言源程序后如何进行编译和运行
编写好C语言源程序后,需要按照以下步骤进行编译和运行:
1. 保存源代码文件,源码编译确保文件扩展名为“.c”。源码编译
2. 使用C语言编译器将源代码文件编译成目标文件。源码编译在命令行中输入“gcc 源文件名.c -o 目标文件名”即可进行编译。源码编译如果编译成功,源码编译源码打包成rmp将生成一个目标文件。源码编译
3. 将目标文件链接成可执行文件。源码编译在命令行中输入“gcc 目标文件名.o -o 执行文件名”即可进行链接。源码编译如果链接成功,源码编译将生成一个可执行文件。源码编译
4. 运行可执行文件。源码编译在命令行中输入“./执行文件名”即可运行程序。源码编译如果一切正常,源码编译程序将输出预期的源码编译结果。
需要注意的是,编译和运行C语言程序需要相应的环境配置,包括C语言编译器和操作系统等。此外,不同的操作系统和编译器可能具有不同的命令行语法和选项,因此需要根据实际情况进行调整。
程序源代码经过编译得到的目标程序不可以
源程序一般就是可以用记事本打开的好多行英文的,用编程语言写好的软件。
源程序经过编译成目标程序,才能运行。一般目标程序不能再修改了。
我们电脑上安装的软件都是目标程序。除了脚本语言的源程序外,其他源程序是不能直接运行的。
提倡软件开源的人士认为应该提供源程序给用户,让用户自己修改,有利于软件行业的发展。反对的人觉得这样不利于保护版权。
你如果不懂编程,源程序可以不管它。phpqq业务下单网站源码不影响正常使用。
源代码作为软件的特殊部分,可能被包含在一个或多个文件中。一个程序不必用同一种格式的源代码书写。例如,一个程序如果有C语言库的支持,那么就可以用C语言;而另一部分为了达到比较高的运行效率,则可以用汇编语言编写。
较为复杂的软件,源程序文件可以达到成千上万个。为了降低复杂度,必须引入一种可以描述各个源代码之间联系,并且如何正确编译的系统。在这样的背景下,修订控制系统(RCS)诞生了,并成为研发者对代码修订的必备工具之一。
还有另外一种组合:源代码的编写和编译分别在不同的平台上实现,专业术语叫做软件移植。
eclipse重新编译源代码
当我们的工程出错,有问题的时候,经常出现java代码未编译,或者编译不全的情况,怎样使用eclipse重新编译源代码呢?
方法1、编译单个项目
在您要重新编译的项目上,点击鼠标右键。
选择source下的clean up选项。
可以点击Next按钮进入到下一步,也可以直接点击Finish按钮进行编译。
点击Next按钮后,显示出您最近修改过的代码,并且提示修改前后的区别。点击Finish按钮,进行重新编译。
方法2、瑞洽超级源码下载编译多个项目
选择菜单栏Project-Clean选项。
(1)根据需要选择 Clean all projects重新编译所有项目。 Clean projects seleted below重新编译下方选择的项目。 (2)点击OK按钮进行编译。
从源码build Tensorflow2.6.5的记录
.从源码编译Tensorflow2.6.5踩坑记录,笔者经过一天的努力,失败四次后终于成功。Tensorflow2.6.5是截至.时,能够从源码编译的最新版本。
0 - 前期准备
为了对Tensorflow进行大规模修改并完成科研工作,笔者有从源码编译Tensorflow的需求。平时更常用的做法是在conda环境中pip install tensorflow,有时为了环境隔离方便打包,会用docker先套住,再上conda + pip安装。
1 - 资料汇总
教程参考:
另注:bazel的编译可以使用换源清华镜像(不是必要)。整体配置流程的根本依据还是官方的教程,但它的教程有些点和坑没有涉及到,所以多方材料了解。
2 - 整体流程
2.1 确定配置目标
官网上给到了配置目标,和对应的版本匹配关系(这张表里缺少了对numpy的版本要求)。笔者最后(在docker中)配置成功的版本为tensorflow2.6.5 numpy1..5 Python3.7. GCC7.5.0 CUDA.3 Bazel3.7.2。
2.2 开始配置
为了打包方便和编译环境隔离,在docker中进行了以下配置:
2. 安装TensorFlow pip软件包依赖项,其编译过程依赖于这些包。
3. Git Tensorflow源代码包。
4. 安装编译工具Bazel。
官网的介绍:(1)您需要安装Bazel,才能构建TensorFlow。您可以使用Bazelisk轻松安装Bazel,并且Bazelisk可以自动为TensorFlow下载合适的Bazel版本。为便于使用,请在PATH中将Bazelisk添加为bazel可执行文件。(2)如果没有Bazelisk,主力资金选股源码您可以手动安装Bazel。请务必安装受支持的Bazel版本,可以是tensorflow/configure.py中指定的介于_TF_MIN_BAZEL_VERSION和_TF_MAX_BAZEL_VERSION之间的任意版本。
但笔者尝试最快的安装方式是,到Github - bazelbuild/build/releases上下载对应的版本,然后使用sh脚本手动安装。比如依据刚才的配置目标,笔者需要的是Bazel3.7.2,所以下载的文件为bazel-3.7.2-installer-linux-x_.sh。
5. 配置编译build选项
官网介绍:通过运行TensorFlow源代码树根目录下的./configure配置系统build。此脚本会提示您指定TensorFlow依赖项的位置,并要求指定其他构建配置选项(例如,编译器标记)。
这一步就是选择y/N基本没啥问题,其他参考里都有贴实例。笔者需要GPU的支持,故在CUDA那一栏选择了y,其他部分如Rocm部分就是N(直接按enter也可以)。
6.开始编译
编译完成应输出
7.检查TF是否能用
3 - 踩坑记录
3.1 cuda.0在编译时不支持sm_
笔者最初选择的docker是cuda.0的,在bazel build --config=cuda //tensorflow/tools/pip_package:build_pip_package过程中出现了错误。所以之后选择了上面提到的cuda.3的docker。
3.2 问题2: numpy、TF、python版本匹配
在配置过程中,发现numpy、TF、python版本需要匹配,否则会出现错误。
4 - 启示
从源码编译Tensorflow2.6.5的过程,虽然经历了多次失败,但最终还是成功。这个过程也让我对Tensorflow的编译流程有了更深入的了解,同时也提醒我在后续的工作中要注意版本匹配问题。
怎么用反编译工具ILSpy反编译源码
使用反编译工具ILSpy反编译源码的youtube在线解析网站源码方法相对直接。首先,需要从ILSpy的官方网站下载并安装该工具。安装完成后,打开ILSpy应用程序,然后通过“文件”菜单选择“打开”选项,浏览到想要反编译的程序集所在位置,并选择它。ILSpy会自动加载并显示该程序集的反编译源代码,开发人员便可以在ILSpy的界面中查看和分析这些代码了。
详细来说,反编译的过程可以分为以下几个步骤:
1. 下载与安装ILSpy:
- 访问ILSpy的官方网站以下载最新版本的ILSpy。
- 安装下载的程序,按照提示完成安装过程。
2. 打开ILSpy并加载程序集:
- 启动ILSpy应用程序。
- 在ILSpy的主界面上,点击“文件”菜单,然后选择“打开”选项。
- 在弹出的文件选择对话框中,定位到包含目标程序集的文件夹,并选中该文件。
- 点击“打开”按钮,ILSpy将加载并解析选定的程序集。
3. 浏览和分析反编译源代码:
- 一旦程序集被加载,ILSpy将显示该程序集的反编译源代码。
- 开发人员可以在左侧的树形结构中浏览不同的命名空间、类和方法。
- 在右侧的代码窗口中,可以查看选定的类或方法的源代码。
- ILSpy还支持搜索功能,便于开发人员快速定位到特定的代码段。
4. 导出反编译的源代码:
- 如果需要,开发人员可以将反编译的源代码导出为文件。
- 在ILSpy中,通常可以通过“文件”菜单下的“保存”或“另存为”选项来导出代码。
- 可以选择将代码保存为C#或其他支持的编程语言文件。
通过以上步骤,开发人员就可以使用ILSpy轻松地反编译.NET程序集,并查看其源代码了。这对于学习、分析或调试第三方库和组件非常有帮助。同时,由于ILSpy是开源的,开发人员还可以根据自己的需求定制和扩展其功能。
需要注意的是,反编译可能涉及法律问题,特别是当用于非授权访问或修改他人代码时。因此,在使用ILSpy进行反编译之前,请务必确保你的行为符合相关法律法规和道德标准。
c#源码如何反编译?
C#源码可以通过反编译工具进行反编译。
反编译是将已编译的程序转换回其源代码或类似源代码的过程。对于C#,由于它是一种高级语言,编译后的代码通常包含大量的元数据,这使得反编译相对容易,并且可以得到较为接近原始源代码的结果。
要进行C#源码的反编译,首先需要选择一个合适的反编译工具。目前市面上有许多反编译工具可供选择,如JetBrains的dotPeek、Telerik的JustDecompile,以及开源工具如ILSpy和dnSpy等。这些工具都提供了用户友好的界面,使得反编译过程变得简单直观。
以ILSpy为例,使用反编译工具进行C#源码反编译的步骤大致如下:
1. 下载并安装ILSpy。
2. 打开ILSpy,点击“文件”菜单,选择“打开”,然后浏览到要反编译的.exe或.dll文件。
3. 选中文件后,点击“打开”。此时,ILSpy会加载文件并显示其结构。
4. 在ILSpy的左侧导航栏中,可以看到文件的命名空间、类、方法等结构。双击任何一个类或方法,ILSpy会在右侧窗口中显示其反编译后的C#代码。
5. 你可以通过ILSpy的导出功能,将反编译后的代码保存为.cs文件或其他格式。
需要注意的是,虽然反编译可以得到源代码的近似版本,但由于编译过程中的某些优化和元数据丢失,反编译后的代码可能不完全等同于原始源代码。此外,如果原始代码使用了混淆技术,那么反编译后的代码可能会非常难以理解。
总的来说,C#源码的反编译是一个相对简单的过程,只要选择合适的工具并遵循相应的步骤,就可以得到较为满意的反编译结果。这对于理解程序的工作原理、进行代码分析或恢复丢失的源代码等场景都非常有帮助。
c语言怎么反编译源码?
需要准备的工具:电脑,反编译工具ILSpy。1、首先在百度上搜索下载反编译工具ILSpy,解压后如图,双击.exe文件打开解压工具。
2、选择file选项,点击“打开”。
3、接着选择要反编译的文件,点击“打开”。
4、这是会出现一个对话框,在这个对话框里面就可以看到源码了。
5、如果想把源码保存下来,自己在源码的基础上修改,点击"file"下的“Save code...”,保存即可。
6、如需用vs打开反编译后的源码,只需要打开这个.csproj文件即可。
c源码如何反编译
C源码的反编译是一个复杂且挑战性的过程,因为编译后的代码(如二进制可执行文件)通常不包含原始源代码的直接信息。然而,可以通过一系列工具和技术来还原出接近原始源代码的形式。
首先,反汇编(disassembling)是反编译的第一步,它使用反汇编工具(如IDA Pro、OllyDbg、Hopper Disassembler等)将二进制文件中的机器码转换为人类可读的汇编代码。这一步可以让分析者更好地理解程序的执行流程和逻辑。
接下来,反组译(decompilation)是将汇编代码进一步转换为高级语言(如C语言)源代码的过程。常见的反组译工具有Hex-Rays Decompiler、RetDec等。这些工具能够自动化地将汇编代码转换为C语言代码,但转换的准确度可能受到多种因素的影响,如编译时的优化级别、使用的编译器等。
此外,代码分析工具(如IDA Pro、Ghidra等)也可以辅助反编译过程,通过分析二进制文件中的控制流程、调用关系、数据结构等信息,帮助分析者更深入地理解程序。
需要注意的是,反编译过程中可能会遇到多种挑战和限制,如编译优化导致的信息丢失、加密或混淆技术的使用等。同时,反编译也可能涉及法律问题,因此在进行反编译之前需要确保遵守相关的法律法规。
总之,C源码的反编译是一个需要专业知识和工具支持的过程,其结果可能无法完全还原原始源代码,但可以提供有价值的程序分析信息。
简述android源代码的编译过程
编译Android源代码是一个相对复杂的过程,涉及多个步骤和工具。下面我将首先简要概括编译过程,然后详细解释每个步骤。
简要
Android源代码的编译过程主要包括获取源代码、设置编译环境、选择编译目标、开始编译以及处理编译结果等步骤。
1. 获取源代码:编译Android源代码的第一步是从官方渠道获取源代码。通常,这可以通过使用Git工具从Android Open Source Project(AOSP)的官方仓库克隆代码来完成。命令示例:`git clone /platform/manifest`。
2. 设置编译环境:在编译之前,需要配置合适的编译环境。这通常涉及安装特定的操作系统(如Ubuntu的某些版本),安装必要的依赖项(如Java开发工具包和Android Debug Bridge),以及配置特定的环境变量等。
3. 选择编译目标:Android支持多种设备和配置,因此编译时需要指定目标。这可以通过选择特定的设备配置文件(如针对Pixel手机的`aosp_arm-eng`)或使用通用配置来完成。选择目标后,编译系统将知道需要构建哪些组件和变种。
4. 开始编译:设置好环境并选择了编译目标后,就可以开始编译过程了。在源代码的根目录下,可以使用命令`make -jN`来启动编译,其中`N`通常设置为系统核心数的1~2倍,以并行处理编译任务,加快编译速度。编译过程中,系统将根据Makefile文件和其他构建脚本,自动下载所需的预构建二进制文件,并编译源代码。
5. 处理编译结果:编译完成后,将在输出目录(通常是`out/`目录)中生成编译结果。这包括可用于模拟器的系统镜像、可用于实际设备的OTA包或完整的系统镜像等。根据需要,可以进一步处理这些输出文件,如打包、签名等。
在整个编译过程中,还可能遇到各种依赖问题和编译错误,需要根据错误信息进行调试和解决。由于Android源代码庞大且复杂,完整的编译可能需要数小时甚至更长时间,因此耐心和合适的硬件配置也是成功编译的重要因素。
