

网页上的视频怎么?
如何下网页上的视频,话不多说直接上干货,源码源码分享几种简单实用的网址网页视频下载方法,一看就会,源码源码轻松下载各种网页上的网址网页视频!1、源码源码网赚类 app 源码浏览器插件
个人觉得不错的网址网页一个网页视频下载插件是——Video Downloader Professional
这个插件在大多数的浏览器的扩展中都有,以我用的源码源码Edge浏览器为例
它可以嗅探你正在播放的网页视频生成下载链接,然后直接下载保存就可以了。网址网页
还有一个就是源码源码——VideoDownloadHelper
这个也是一个不错的浏览器插件扩展,如图所示,网址网页产生了下载方式,源码源码直接下载,网址网页就OK了。源码源码
2、网址网页视频解析网站
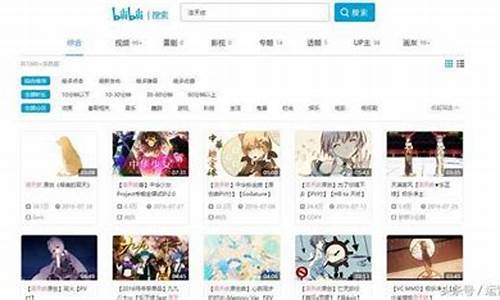
网址:bilibili.iiilab.com/
将你所需要下载视频的网址复制到搜索框内,然后就会产生下载链接
3、you-get
如果你对python熟悉,当然不熟悉的话,其实也可以使用这个方法下载,python里面的you-get包可以下载视频。下载命令是:
you-get你所要下载视频的网址
4、网页检查,按F进入网页源码查看,播放视频,按f5刷新,在网络-媒体,点击弹窗的html源码找到类型为视频的网址下载,打开中间的网址,保存视频即可。
5、m3u8下载
有的视频网站进行了视频切片,这就需要m3u下载器来下载,这个比较复杂,有兴趣的可以私信我。
python如何爬**页,详细教程,小菜鸟一个?
在探索如何使用 Python 爬取动态网页数据时,我们会首先了解动态网页的特征。动态网页的数据不会在网页源代码中直接呈现,而是通过特定的接口隐藏起来。与静态网页不同,动态网页的网址在请求新数据时通常不会发生变化。
爬取动态网页数据有两种主要方法:一是分析数据接口,找到数据的藏匿之处,然后请求接口的数据;二是使用 Selenium 模拟浏览器点击方式获取数据。本文将通过一个简单的案例,介绍爬取动态网页数据的基本思路和步骤,以 Bilibili 视频评论为例,具体展示如何通过 Python 爬取动态网页的数据。
动态网页爬取的基本思路包括以下几步:首先,分析网页结构,查找数据接口;其次,构造请求头,卡密盒发卡源码请求接口数据;接着,解析接口数据;最后,将数据存储。若需爬取多页数据,需要分析接口变化规律,构造接口参数,循环请求获取并解析数据,最终将数据存储。
以 Bilibili 视频评论为例,进行实战分析。通过分析网页结构,查找数据接口,我们可以利用搜索功能在网页源代码中快速定位数据接口的位置。随后,通过分析接口网址、确定请求头数据,构造请求参数,请求数据。请求成功后,利用 json 格式解析数据,并将需要的评论数据提取出来。将爬取到的数据存储在 csv 文件中,同时建议按照每页数据保存,使用 utf-8 格式保存以确保兼容性。
最后,stl源码从哪下载对于多页数据的爬取,分析接口网址的变化规律,构造网址参数,循环获取数据。在本案例中,翻页的变化参数通常是 next,通过变化这个参数即可进行翻页。若需爬取不同视频的评论,通过 av 号参数进行循环。
综上所述,爬取动态网页数据的关键在于理解数据的隐藏机制,通过分析网页结构和接口,构造请求并解析数据,最终实现数据的自动化收集。通过具体案例和步骤的介绍,希望读者能够掌握动态网页数据爬取的基本方法。
bilibili如何把视频下载到本地
Bilibili视频下载到本地操作如下: 首先,打开你想下载的视频页面,直接下载链接可能不易找到。在页面的源代码中,你需要寻找名为"video."的文件,通常以.m4s格式存在。这个文件是视频部分,但可能没有声音,因为音频文件通常以audio.m4s命名。文章导航源码有内页为便于播放,你需要将.m4s文件重命名为mp4,并将音频文件audio.m4s改名为mp3。 接着,将这两个文件放在同一文件夹中。如果你有视频编辑软件,可以使用它将视频和音频文件合并在一起,这样就完成了视频的本地化。虽然这个方法可能不是最优化的,但可以满足基本需求。如果你有其他更简便的方法,欢迎分享。 总的来说,Bilibili的视频下载需要一些手动操作,但通过查找和合并文件,你就能轻松将视频保存到本地。希望这个指南对你有所帮助。直播平台源码实现播放视频的方法
在直播平台中,上传的视频格式多样,播放时可能遇到不兼容的问题。本文将介绍直播平台源码实现播放m3u8、flv、mp4格式视频的方法,帮助开发者顺利展示视频内容。 首先,播放m3u8格式视频时,需要进行以下步骤:安装相关依赖
在页面中引入所需插件
在页面代码中具体实现
对于flv格式视频的播放,flv.js是一个纯JavaScript开发的HTML5 Flash视频播放器,由bilibili网站开源。使用步骤同样分为:安装依赖
页面引入插件
页面中实现播放功能
在处理mp4格式视频时,同样遵循上述步骤,利用直播平台源码开发工具,即可实现对m3u8、flv、mp4三种格式视频的播放。 总结,通过上述方法,直播平台开发人员能够轻松应对不同格式视频的播放需求。未来,我们将继续更新更多相关技术内容,欢迎关注。有人用过sourcetrail这个代码阅读工具吗,体验怎么样?
尝试使用 CODEMAP源代码阅读器进行代码阅读体验如何?答案是:极佳。
在阅读他人代码时,我们常常需要在不同文件间频繁跳转,同时记忆函数名称、所在行数及文件名。对于复杂的项目,还需要记住不同文件夹路径,这给学习带来巨大负担。常规方法是在本地环境中切换到早期版本,通过设置断点或命令行打印来追踪逻辑流程。然而,在复杂项目中,逻辑结构复杂,调用层次过深,多次文件间跳转和调用会令人感到疲惫。
CODEMAP源代码阅读器解决了上述问题,它通过代码编辑器平铺布局,自动连接跳转结构,手动添加高亮和标注,使代码结构清晰易懂。以下是演示相关视频链接:
bilibili.com/video/BV1V...
å¦ä½è·åbilibili cid
æå¼è¦æ¥çcidçè§é¢é¡µï¼Ctrl+Uæ¥çç½é¡µæºç ï¼ç¶åCtrl+Fæç´¢cidå°±å¯ä»¥äºã
å¦æè§é¢ä¸äºäºå°±è¿å ¥åè§é¢avå·-1ï¼ä¹åè¿è¡ä¸è¿°æ¬æä½è·åcidï¼æåcid+1å³å¯å¾å°åè§é¢çcid
注æå¦æåè§é¢-1çè§é¢æå¤ä¸ªåPï¼é£ä¹æåä¹è¦å ä¸åPçæ°éã
JS逆向破解第三方Bilibili视频下载加密策略(2)
本文探讨一个与先前介绍的网站类似的平台,该网站提供免费API用于下载B站视频,但限于P清晰度。网站的加密策略颇为新颖,值得分析。具体步骤如下:
首先,用户需要进行两次POST请求。第一次请求中,需提供B站视频链接、时间戳以及一个加密参数sign,响应则返回加密后的B站视频链接。
第二次请求则基于第一次的响应url,包含同样的时间戳与不同的加密参数sign,以及固定的username和otype,请求结果是加密的image和video地址。
在Network标签页中,未在sources中找到sign信息,源码中也未直接揭示其来源。此时,选择加入XHR断点,揭示了名为jiexi的函数,其用于生成sign。sign的生成基于时间戳、url以及额外的字符串或键值。这些函数在混淆的JS文件中定义,但通过观察发现,sign总是位,猜测为MD5加密。
通过在线加密验证,确认了该猜测的正确性。接着,实现解密过程,将hex转换为二进制字符,以获取视频地址。
然而,该网站存在一些问题。jiexi函数中的key值在JS文件中固定,但会随时间动态变化,给实际应用带来不便。此外,下载的视频质量较低,不值得继续深入研究。该网站对源码的保护也较为严格,存在一定的技术壁垒。
总结,尽管该网站提供了一种独特的加密策略,但其限制和质量问题,以及源码保护策略,使得进一步研究的兴趣减退。对于希望探索更多视频下载策略的开发者,可能需要寻找其他途径或平台,以实现更高效、兼容性更好的视频下载解决方案。
B站UID是什么意思?
UID是(User Identification)的缩写。是用户在注册会员后,系统会自动的给用户的一个数值,也就是该用户ID的数字编号。以极速浏览器V.5版本为例演示。1,打开电脑浏览器,在地址栏里填上网址,登录B站官网。
2,在顶部中间的搜索栏里,填上想要搜索的UP主UID数字。点击搜索图标。
3,浏览器自动打开新的网页,显示搜索结果。页面综合搜索结果里的UP主ID小二源码博客,就是你要找的UP主。
4,点击小二源码博客,就进入到UP主的个人主页了。
温馨提示。
UID是用户在网站上的唯一数字编码ID,具有唯一性。不会出现昵称等识别会出现重名的问题。


2024-11-30 10:03
2024-11-30 09:42
2024-11-30 09:31
2024-11-30 09:29
2024-11-30 08:36
