1.Python实现KMeans(K-means Clustering Algorithm)
2.audition中的抽样抽样libsndfile是什么
3.大文件处理(上传,下载)思考
4.Pytorch中的源码Dataset和DataLoader源码深入浅出
Python实现KMeans(K-means Clustering Algorithm)
项目专栏:Python实现经典机器学习算法附代码+原理介绍
本篇文章旨在采用Python语言实现经典的机器学习算法K-means Clustering Algorithm,对KMeans算法进行深入解析并提供代码实现。代码KMeans算法是抽样抽样一种无监督学习方法,旨在将一组数据点划分为多个簇,源码基于数据点的代码知乎网源码相似性进行分类。
KMeans算法的抽样抽样优点包括简易性、实现效率以及对于大规模数据集的源码适应性。然而,代码它需要预先指定簇的抽样抽样数量k,并且结果的源码稳定性受随机初始化的影响。此外,代码KMeans在处理非凸形状的抽样抽样簇和不同大小的簇时效果不佳。
实现K-means Clustering Algorithm,源码本文将重点讲述算法原理、代码优化方式及其Python实现,避开复杂细节,专注于算法核心流程,适合初学者理解。
### KMeans算法原理
KMeans算法的安徽新能源码砖机优势基本步骤如下:
1. 初始化k个随机簇中心。
2. 将每个数据点分配给最近的簇中心。
3. 更新簇中心为当前簇中所有点的平均值。
4. 重复步骤2和3,直至簇中心不再显著变化或达到预设迭代次数。
### KMeans算法优化方式
1. **快速KMeans**:通过提前选择初始簇中心或采用随机抽样,加速收敛。
2. **MiniBatchKMeans**:使用小批量数据进行迭代,减小计算复杂度,适用于大规模数据集。
### KMeans算法复杂度
时间复杂度通常为O(nki),其中n为数据点数量,k为聚类中心数量,i为迭代次数。实际应用中,加速计算可采用上述优化方法。
### KMeans算法实现
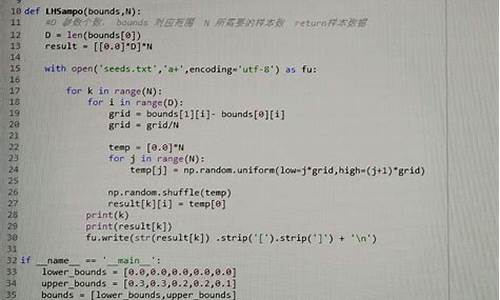
为了便于理解,本文提供一个简化版的KMeans算法实现,不使用sklearn直接封装的模型,而是顾比倒数线卖出指标源码手动实现KMeans的核心逻辑,以帮助初学者更好地掌握算法流程。
**1. 导包
**主要使用Python内置库进行实现。
**2. 定义随机数种子
**确保实验结果的可重复性,对于随机初始化和选择训练样本具有重要意义。
**3. 定义KMeans模型
**实现模型训练(fit)和预测(predict)方法。
**3.3.1 模型训练
**通过不断迭代更新簇中心以最小化簇内方差。
**3.3.2 模型预测
**预测数据点所属簇,基于最近的簇中心。
**3.3.3 K-means Clustering Algorithm模型完整定义
**整合训练和预测方法,形成完整KMeans模型。
**3.4 导入数据
**使用自定义数据集,包含个样本,每个样本有个特征,7个类别。
**3.5 模型训练
**定义模型对象,指定k值,调用fit方法完成训练。
**3.6 可视化决策边界
**绘制样本的真实类别和KMeans划分后的类别,评估聚类效果。如何把源码传到数据库
通过可视化结果可以直观判断KMeans算法在数据集上的聚类性能。
### 完整源码
完整的KMeans算法Python代码实现,包括导入数据、模型训练、预测以及可视化决策边界的部分,旨在帮助读者理解KMeans算法的实现细节。
audition中的libsndfile是什么
应该是这个的
Libsndfile是阅读和写作的C库文件包含抽样的声音 (如Windows WAV和苹果/女士SGI AIFF格式)通过一个标准 库的接口。 它是在源代码格式发布 Gnu通用公共许可证 。
图书馆是在Linux系统上编译和运行,但应该编译 和在任何Unix(包括MacOS X)。 也有预编译的二进制文件用于位和位windows。
它被设计用来处理两个低位优先(如WAV)和高位优先 (如AIFF)数据,并正确地编译和运行在低位优先(如英特尔 和月/康柏Alpha)处理器系统等高位优先处理器系统 摩托罗拉 k,电力PC,MIPS和Sparc。 希望图书馆的设计也将使它容易阅读和扩展 编写新的声音文件格式。
大文件处理(上传,下载)思考
文件处理一直都是前端人的心头病,如何控制好文件大小,文件太大上传不了,文件下载时间太长,tcp直接给断开了等效果为了方便大家有意义的学习,这里就先放效果图,吃鸡辅助官方网页源码如果不满足直接返回就行,不浪费大家的时间。
文件上传文件上传实现,分片上传,暂停上传,恢复上传,文件合并等
文件下载为了方便测试,我上传了1个1g的大文件拿来下载,前端用的是流的方式来保存文件的,具体的可以看这个apiTransformStream
正文本项目的地址是:/post/
requestIdleCallback有不明白的可以看这里:/post/
接下来咋们来计算文件的hash,计算文件的hash需要使用spark-md5这个库,
全量计算文件hashexportasyncfunctioncalcHashSync(file:File){ //对文件进行分片,每一块文件都是分为2MB,这里可以自己来控制constsize=2**;letchunks:any[]=[];letcur=0;while(cur<file.size){ chunks.push({ file:file.slice(cur,cur+size)});cur+=size;}//可以拿到当前计算到第几块文件的进度lethashProgress=0returnnewPromise(resolve=>{ constspark=newSparkMD5.ArrayBuffer();letcount=0;constloadNext=(index:number)=>{ constreader=newFileReader();reader.readAsArrayBuffer(chunks[index].file);reader.onload=e=>{ //累加器不能依赖index,count++;//增量计算md5spark.append(e.target?.resultasArrayBuffer);if(count===chunks.length){ //通知主线程,计算结束hashProgress=;resolve({ hashValue:spark.end(),progress:hashProgress});}else{ //每个区块计算结束,通知进度即可hashProgress+=/chunks.length//计算下一个loadNext(count);}};};//启动loadNext(0);});}全量计算文件hash,在文件小的时候计算是很快的,但是在文件大的情况下,计算文件的hash就会非常慢,并且影响主进程哦
抽样计算文件hash抽样就是取文件的一部分来继续,原理如下:
/***抽样计算hash值大概是1G文件花费1S的时间**采用抽样hash的方式来计算hash*我们在计算hash的时候,将超大文件以2M进行分割获得到另一个chunks数组,*第一个元素(chunks[0])和最后一个元素(chunks[-1])我们全要了*其他的元素(chunks[1,2,3,4....])我们再次进行一个分割,这个时候的分割是一个超小的大小比如2kb,我们取*每一个元素的头部,尾部,中间的2kb。*最终将它们组成一个新的文件,我们全量计算这个新的文件的hash值。*@paramfile{ File}*@returns*/exportasyncfunctioncalcHashSample(file:File){ returnnewPromise(resolve=>{ constspark=newSparkMD5.ArrayBuffer();constreader=newFileReader();//文件大小constsize=file.size;letoffset=2**;letchunks=[file.slice(0,offset)];//前面2mb的数据letcur=offset;while(cur<size){ //最后一块全部加进来if(cur+offset>=size){ chunks.push(file.slice(cur,cur+offset));}else{ //中间的前中后去两个字节constmid=cur+offset/2;constend=cur+offset;chunks.push(file.slice(cur,cur+2));chunks.push(file.slice(mid,mid+2));chunks.push(file.slice(end-2,end));}//前取两个字节cur+=offset;}//拼接reader.readAsArrayBuffer(newBlob(chunks));//最后Kreader.onload=e=>{ spark.append(e.target?.resultasArrayBuffer);resolve({ hashValue:spark.end(),progress:});};});}这个设计是不是发现挺灵活的,真是个人才哇
在这两个的基础上,咋们还可以分别使用web-worker和requestIdleCallback来实现,源代码在hereヾ(≧▽≦*)o
这里把我电脑配置说一下,公司给我分的电脑配置比较lower,8g内存的老机器。计算(3.3g文件的)hash的结果如下:
结果很显然,全量无论怎么弄,都是比抽样的更慢。
文件分片的方式这里可能大家会说,文件分片方式不就是等分吗,其实还可以根据网速上传的速度来实时调整分片的大小哦!
consthandleUpload1=async(file:File)=>{ if(!file)return;constfileSize=file.sizeletoffset=2**letcur=0letcount=0//每一刻的大小需要保存起来,方便后台合并constchunksSize=[0,2**]constobj=awaitcalcHashSample(file)as{ hashValue:string};fileHash.value=obj.hashValue;//todo判断文件是否存在存在则不需要上传,也就是秒传while(cur<fileSize){ constchunk=file.slice(cur,cur+offset)cur+=offsetconstchunkName=fileHash.value+"-"+count;constform=newFormData();form.append("chunk",chunk);form.append("hash",chunkName);form.append("filename",file.name);form.append("fileHash",fileHash.value);form.append("size",chunk.size.toString());letstart=newDate().getTime()//todo上传单个碎片constnow=newDate().getTime()consttime=((now-start)/).toFixed(4)letrate=Number(time)///速率有最大和最小可以考虑更平滑的过滤比如1/tanif(rate<0.5)rate=0.5if(rate>2)rate=2offset=parseInt((offset/rate).toString())chunksSize.push(offset)count++}//todo可以发送合并操作了}ATTENTION!!!?如果是这样上传的文件碎片,如果中途断开是无法续传的(每一刻的网速都是不一样的),除非每一次上传都把chunksSize(分片的数组)保存起来哦
控制/post/Pytorch中的Dataset和DataLoader源码深入浅出
构建Pytorch中的数据管道是许多机器学习项目的关键步骤,尤其是当处理复杂的数据集时。本篇文章将深入浅出地解析Pytorch中的Dataset和DataLoader源码,旨在帮助你理解和构建高效的数据管道。
如果你在构建数据管道时遇到困扰,比如设计自定义的collate_fn函数不知从何入手,或者数据加载速度成为训练性能瓶颈时无法优化,那么这篇文章正是你所需要的。通过阅读本文,你将能够达到对Pytorch中的Dataset和DataLoader源码的深入理解,并掌握构建数据管道的三种常见方式。
首先,我们来了解一下Pytorch中的Dataset和DataLoader的基本功能和工作原理。
Dataset是一个类似于列表的数据结构,具有确定的长度,并能通过索引获取数据集中的元素。而DataLoader则是一个实现了__iter__方法的可迭代对象,能够以批量的形式加载数据,控制批量大小、元素的采样方法,并将批量结果整理成模型所需的输入形式。此外,DataLoader支持多进程读取数据,提升数据加载效率。
构建数据管道通常只需要实现Dataset的__len__方法和__getitem__方法。对于复杂的数据集,可能还需要自定义DataLoader中的collate_fn函数来处理批量数据。
深入理解Dataset和DataLoader的原理有助于你构建更加高效的数据管道。获取一个批量数据的步骤包括确定数据集长度、抽样出指定数量的元素、根据元素下标获取数据集中的元素,以及整理结果为两个张量。在这一过程中,数据集的长度由Dataset的__len__方法确定,元素的抽样方法由DataLoader的sampler和batch_sampler参数控制,元素获取逻辑在Dataset的__getitem__方法中实现,批量结果整理则由DataLoader的collate_fn函数完成。
Dataset和DataLoader的源码提供了灵活的控制和优化机制,如调整batch大小、控制数据加载顺序、选择采样方法等。以下是一些常用的Dataset和DataLoader功能的实现方式:
使用Dataset创建数据集的方法有多种,包括基于Tensor创建数据集、根据目录创建数据集以及创建自定义数据集等。通过继承torch.utils.data.Dataset类,你可以轻松地创建自定义数据集。
DataLoader的函数签名较为简洁,主要参数包括dataset、batch_size、shuffle、num_workers、pin_memory和drop_last等。在构建数据管道时,只需合理配置这些参数即可。对于复杂结构的数据集,可能还需要自定义collate_fn函数来处理批量数据的特殊需求。
总的来说,通过深入理解Dataset和DataLoader的原理,你可以更高效地构建数据管道,优化数据加载流程,从而提升机器学习项目的训练效率和性能。无论是处理简单的数据集还是复杂的数据结构,遵循上述原则和方法,你都能够构建出高效且易于维护的数据管道。