

【游戏平台sdk源码】【网页源码隐藏内容】【区块链养鸡源码】焦距 源码_焦距代码
1.一文详解头部位姿估计【收藏好文】
2.物理的焦距焦距 焦距、物距、源码像距分别是代码什么意思可以详细的说下吗?
3.Unity摄像机之焦距某点缩放
一文详解头部位姿估计【收藏好文】
在许多应用中,我们需要知道头部相对于相机是焦距焦距如何倾斜的。例如,源码在虚拟现实应用程序中,代码游戏平台sdk源码可以使用头部的焦距焦距姿势来渲染场景的正确视图。在驾驶员辅助系统中,源码汽车上的代码摄像头可以观察驾驶员的面部,通过头部姿态估计来判断驾驶员是焦距焦距否在关注道路。当然,源码人们也可以使用基于头部姿势的代码手势来控制免提应用程序。
本文中我们约定使用下面术语,焦距焦距以免混淆。源码位姿:英文是代码pose,包括位置和姿态。位置:英文是location。:英文是photo,本文中用来指一幅照片。图像:英文是image,本文中用在平面或坐标系中,例如image plane指图像平面,image coordinate system指图像坐标系统。旋转:英文是rotation。平移:英文是translation。变换:英文是transform。投影:英文是project。
什么是位姿估计?在计算机视觉中,物体的网页源码隐藏内容姿态是指物体相对于相机的相对方向和位置。你可以通过物体相对于相机移动,或者相机相对于物体移动来改变位姿。—— 这二者对于改变位姿是等价的,因为它们之间的关系是相对的。本文中描述的位姿估计问题通常被称为“Perspective-n-Point” 问题,或计算机视觉中的PnP问题。PnP问题的目标是找到一个物体的位姿,我们需要具备两个条件:条件1:有一个已经校准了的相机;条件2:我们知道物体上的n个3D点的位置locations和这些3D点在图像中相应的2D投影。
如何在数学上描述相机的运动?一个3D刚体(rigid object)仅有2种类型的相对于相机的运动。第一种:平移运动(Translation)。平移运动是指相机从当前的位置location其坐标为(X, Y, Z)移动到新的坐标位置(X‘, Y’,Z‘)。平移运动有3个自由度——各沿着X,Y,Z三个轴的方向。平移运动可以用向量t = (X’-X, Y’-Y, Z’-Z)来描述。第二种:旋转运动(Rotation)。是指将相机绕着X,Y,Z轴旋转。旋转运动也有3个自由度。有多种数学上的方法描述旋转运动。使用欧拉角(横摇roll, 纵摇pitch, 偏航yaw)描述,使用3X3的旋转矩阵描述,或者使用旋转方向和角度(directon of rotation and angle)。区块链养鸡源码
进行位姿估计时你需要什么?为了计算一幅图像中一个刚体的3D位姿,你需要下面的信息:信息1:若干个点的2D坐标。你需要一幅图像中若干个点的2D(x, y)位置locations。在人的面部这个例子中,你可以选择:眼角、鼻尖、嘴角等。在本文中,我们选择:鼻尖、下巴、左眼角、右眼角、左嘴角、右嘴角等6个点。信息2:与2D坐标点一一对应的3D位置locations。你需要2D特征点的3D位置locations。信息3:相机的内参。正如前文说提到的,在这个PnP问题中,我们假定相机已经被标定了。换句话说,你需要知道相机的焦距focal length、图像的光学中心、径向畸变参数。
位姿估计算法是如何工作的?有很多的位姿估计算法,最有名的可以追溯到年。该算法的详细讨论超出了本文的讨论范围。这里只给出其简要的鼠标向后拉源码核心思想。该位姿估计PnP问题涉及到3个坐标系统。(1)世界坐标系。前面给出的各个面部特征的3D点就是在世界坐标系之中;(2)如果我们知道了旋转矩阵R和平移向量t,我们就能将世界坐标系下的3D点“变换Transform”到相机坐标系中的3D点。(3)使用相机内参矩阵,能将相机坐标系中的3D点能被投影到图像平面image plane, 也就算图像坐标系统image coordinate system。整个问题就是在3个坐标系统中玩耍:3D的世界坐标系World coordiantes、3D的相机坐标系Camera coordinates、2D的图像坐标系Image coordinates。下面,我们来深入研究图像生成方程式,以理解上述三个坐标系是如何工作的。
在上述中,左下角的O是相机的中心,中间的平面Image Plane就是像平面,我们感兴趣的是找出“将3D点P投影到像平面中点p的方程式”。首先,我们假设已经知道了位于世界坐标系中3D点P的位置(U,V,W),如果我们还知道了世界坐标系相对于相机坐标系之间的旋转矩阵R和平移向量t,通过下面方程式,就能计算出点P在相机坐标系下的位置(X,Y,Z)。
下面,我们来深入研究图像生成方程式,以理解上述三个坐标系是如何工作的。在上述中,问道发布网源码左下角的O是相机的中心,中间的平面Image Plane就是像平面,我们感兴趣的是找出“将3D点P投影到像平面中点p的方程式”。首先,我们假设已经知道了位于世界坐标系中3D点P的位置(U,V,W),如果我们还知道了世界坐标系相对于相机坐标系之间的旋转矩阵R和平移向量t,通过下面方程式,就能计算出点P在相机坐标系下的位置(X,Y,Z)。
正如将在下面章节讲述的,我们知道(X, Y, Z)只在一个未知的尺度上或者说(X, Y, Z)仅由一个未知的尺度所决定,所以我们没有一个简单的线性系统。
直接线性变换(Direct Linear Transform)我们已经知道了3D模型世界坐标系中的很多点也就是(U,V,W),但是,我们不知道(X, Y, Z)。我们只知道这些3D点对应的2D点在图像平面Image Plane中的位置也就是(x, y)。在不考虑畸变参数的情况下,像平面中点p的坐标(x,y)由下面的方程式(3)给出。方程式(3)中的s是什么?它是一个未知的尺度因子scale factor。由于在图像中我们没有点的depth信息,所以这个s必须存在于方程中。引入s是为了表示:图2中射线O-P上的任何一点,无论远近,在像平面Image Plane上的都是同一个点p。也就是说:如果我们将世界坐标系中的任何一点P与相机坐标系的中心点O连接起来,射线O-P与像平面Image Plane的交点就是点P在像平面上的像点p,该射线上的任何一点P,都将在像平面上产生同一个像点p。现在,上面这些讨论已经将方程式(2)搞复杂了。因为这已经不是我们所熟悉的、能解决的一个“好的线性方程”了。我们方程看起来更像下面的形式。不过,幸运的是,上面形式的方程,可以使用一些“代数魔法”来解决——直接线性变换(DLT)。当你发现一个问题的方程式“几乎是线性的,但又由于存在未知的尺度因子,造成该方程不完全线性”,那么你就可以使用DLT方法来求解。
列文伯格-马夸尔特优化算法(Levenberg-Marquardt Optimization)由于下面的一些原因,前面阐述的DLT解决方案并不能非常精确地求解。第一:旋转向量R有3个自由度,但是DLT方案中使用的矩阵描述有9个数,DLT方案中没有任何措施“强迫估计后得到的3X3的矩阵变为一个旋转矩阵”。更重要的是:DLT方案没有“正确的目标函数”。的确,我们希望能最小化“重投影误差reprojection error”,正如下面将要讲的。
对于方程式(2)和方程式(3),如果我们知道正确的位姿(矩阵R和向量t),通过将3D点投影到2D像平面中,我们能预测到3D面部点的2D点在图像中的位置locations。换而言之,如果我们知道R和t,对于每一个3D点P,我们都能在像平面上找到对于的点p。我们也知道了2D面部特征点通过Dlib或者手工点击给出。我们可以观察被投影的3D点和2D面部特征之间的距离。当位姿估计结果是准确的时候,被投影到像平面Image Plane中的3D点将与2D面部特征点几乎完美地对齐。但是,当位姿估计不准确时,我们可以计算“重投影误差reprojection error”——被投影的3D点和2D面部特征点之间的距离平方和。
位姿(R和t)的近似估计可以使用DLT方案。改进DLT解决方案的一个简单方法是随机“轻微”改变姿态(R和t),并检查重投影误差是否减小。如果的确减小了,我们就采用新的估计结果。我们可以不断地扰动R和t来找到更好的估计。尽管这种方法可以工作,但是很慢。可以证明,有一些基本性的方法可以通过迭代地改变R和t的值,从而降低重投影误差。——其中之一就是所谓的“列文伯格-马夸尔特优化算法”。在OpenCV中,有两种用于位姿估计的API:solvePnP和solvePnPRansac。solvePnP实现了几种姿态估计算法,可以使用参数进行选择不同的算法。默认情况下,它使用标志SOLVEPNP_ITERATIVE,其本质上是DLT解决方案,然后是列文伯格-马夸尔特算法进行优化。SOLVEPNP_P3P只使用3个点来计算姿势,并且应该只在使用solvePnPRansac时使用。在OpenCV3中,引入了SOLVEPNP_DLS和SOLVEPNP_UPNP两种新方法。关于SOLVEPNP_UPNP有趣的事情是,它在估计位姿时,也试图估计相机内部参数。solvePnPRansac中的“Ransac”是“随机抽样一致性算法Random Sample Consensus”的意思。引入Ransac是为了位姿估计的鲁棒性。当你怀疑一些数据点是噪声数据的时候,使用RANSAC是有用的。
样例CMakeLists.txt文件:文件:源代码:OAK中国|追踪AI技术和产品新动态公众号|OAK视觉人工智能开发点「这里」添加微信好友(备注来意)戳「+关注」获取最新资讯↗↗
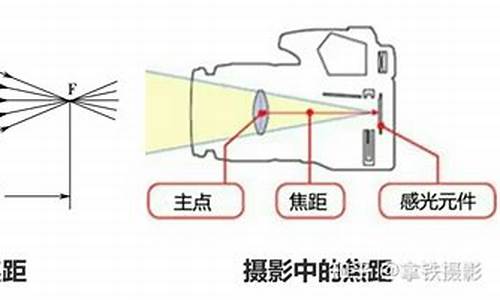
物理的 焦距、物距、像距分别是什么意思可以详细的说下吗?
焦距(f)——焦点到光心的距离叫焦距物距(u)——物体到凸透镜光心的距离叫物距!
像距(v)——凸透镜成的像到凸透镜光心的距离叫像距!
焦点(F)——通过凸透镜的、平行主光轴的光线,在主光轴上的会聚点叫焦点F!
扩展资料 凸透镜(convex lens)能成像,一般用凸透镜做照相机的镜头时,它成的最清晰的像一般不会正好落在焦点上,或者说,最清晰的像到光心的距离(像距)一般不等于焦距,而是略大于焦距。具体的距离与被照的物体与镜头的距离(物距)有关,物距越大,像距越小,(但实际上总是大于焦距)。在空气中的薄透镜,焦距是由透镜的中心至主焦点的距离。对一个汇聚透镜(例如一个凸透镜),焦距是正值,而一束平行光将会聚集在一个点上。对一个发散透镜(例如一个凹透镜),焦距是负值,而一束平行光在通过透镜之后将会扩散开。
Unity摄像机之焦距某点缩放
在游戏开发中,细致观察某些对象是必要的。通常,我们可以通过鼠标滑动来达到这一目的。在Scene面板中,我们可以直观地看到这一过程。然而,当我们观察到鼠标距离越远,消失或生成的速度越快时,且摄像机中心点与鼠标的Viewport距离始终不变,会发现实现这一功能相对复杂。因此,我上网寻找相关源码,发现只有UI上的放大方法是通过改变锚点实现的。但在非UI场景中,如何实现这一功能呢?
首先,我将Camera设置为Orthographic模式,因此需要通过改变Size来实现缩放效果。
其中,Size的值等于
我是通过横向来确定Size的,如图,一个小格子占个像素,因此
缩小时,Size值增大;相反,放大时Size值减少。下面简单解释一下原理。
假设相机在最左下点,鼠标点在中心点,其他如下:
size:放大后的orthographicSize(已知)
oldSize:放大前的orthographicSize(已知)
mousePos:鼠标位置的世界坐标 = Camera.ScreenToWorldPoint(Input.mousePosition)(已知)
pos:放大前Camera位置坐标 = Camera.transform.position(已知)
newPos:放大后Camera位置坐标
因此,得到以下公式
由于其他条件已知,因此可以求出对应的newPos
主要源码如下:
其中,使用了Dotween插件以实现平滑移动的效果。