


Pytorch torchvision与Pillow(PIL)双线性插值resize的原版源码源码区别
Pytorch的torchvision和Pillow库都提供了双线性插值算法用于图像缩放,但它们的原版源码源码具体实现和处理方式有所不同。这些微小的原版源码源码reaof源码差异可能在肉眼难以察觉,但在像素值层面却能体现出来,原版源码源码特别是原版源码源码在数据预处理过程中,顺序改变可能导致模型精度的原版源码源码细微变化。
核心差异在于处理步骤和点的原版源码源码选择策略。torchvision对输入的原版源码源码处理依赖于数据类型:如果是tensor,会采用自定义算法;如果是原版源码源码Pillow的Image对象,则调用Image的原版源码源码算法。这可能导致ToTensor和Resize操作顺序不同时,原版源码源码结果出现偏差。原版源码源码例如,torchvision通常使用四邻近像素进行插值,而Pillow则可能使用更多邻近像素,导致像素值计算上的差异。
以一个6x9图像缩小到4x2为例,Pillow的插值选择点的方式会比Pytorch更广泛,这可能导致像素值计算的细微变化。尽管这种差异在视觉上可能不明显,但在模型的精度评估中,这种小差别不容忽视。
次要影响因素还包括源代码细节和实验分析,但这些影响相对较小。实验结果显示,将ToTensor和Resize操作顺序改变,或者仅对比torchvision和Pillow的Resize操作,都会产生显著的像素值差异。与torchvision的典型双线性插值相比,Pillow的实现虽然略有偏差,但差距已经减小,更接近Pillow自身的算法。
为什么HashMap是线程不安全的
这是《Java程序员进阶之路》专栏的第篇,我们来聊聊为什么HashMap是线程不安全的。、多线程下扩容会死循环众所周知,玩偶网站免费源码HashMap是通过拉链法来解决哈希冲突的,也就是当哈希冲突时,会将相同哈希值的键值对通过链表的形式存放起来。
JDK7时,采用的是头部插入的方式来存放链表的,也就是下一个冲突的键值对会放在上一个键值对的前面(同一位置上的新元素被放在链表的头部)。扩容的时候就有可能导致出现环形链表,造成死循环。
resize方法的源码:
//newCapacity为新的容量voidresize(intnewCapacity){ //小数组,临时过度下Entry[]oldTable=table;//扩容前的容量intoldCapacity=oldTable.length;//MAXIMUM_CAPACITY为最大容量,2的次方=1<<if(oldCapacity==MAXIMUM_CAPACITY){ //容量调整为Integer的最大值0x7fffffff(十六进制)=2的次方-1threshold=Integer.MAX_VALUE;return;}//初始化一个新的数组(大容量)Entry[]newTable=newEntry[newCapacity];//把小数组的元素转移到大数组中transfer(newTable,initHashSeedAsNeeded(newCapacity));//引用新的大数组table=newTable;//重新计算阈值threshold=(int)Math.min(newCapacity*loadFactor,MAXIMUM_CAPACITY+1);}transfer方法用来转移,将小数组的元素拷贝到新的数组中。
voidtransfer(Entry[]newTable,booleanrehash){ //新的容量intnewCapacity=newTable.length;//遍历小数组for(Entry<K,V>e:table){ while(null!=e){ //拉链法,相同key上的不同值Entry<K,V>next=e.next;//是否需要重新计算hashif(rehash){ e.hash=null==e.key?0:hash(e.key);}//根据大数组的容量,和键的hash计算元素在数组中的下标inti=indexFor(e.hash,newCapacity);//同一位置上的新元素被放在链表的头部e.next=newTable[i];//放在新的数组上newTable[i]=e;//链表上的下一个元素e=next;}}}注意e.next=newTable[i]和newTable[i]=e这两行代码,就会将同一位置上的新元素被放在链表的头部。
扩容前的样子假如是下面这样子。
那么正常扩容后就是下面这样子。
假设现在有两个线程同时进行扩容,线程A在执行到newTable[i]=e;被挂起,此时线程A中:e=3、next=7、e.next=null
线程B开始执行,并且完成了数据转移。
此时,7的next为3,3的next为null。
随后线程A获得CPU时间片继续执行newTable[i]=e,将3放入新数组对应的位置,执行完此轮循环后线程A的情况如下:
执行下一轮循环,此时e=7,原本线程A中7的next为5,但由于table是线程A和线程B共享的,而线程B顺利执行完后,7的next变成了3,那么此时线程A中,7的next也为3了。
采用头部插入的筹码抄底指标源码方式,变成了下面这样子:
好像也没什么问题,此时next=3,e=3。
进行下一轮循环,但此时,由于线程B将3的next变为了null,所以此轮循环应该是最后一轮了。
接下来当执行完e.next=newTable[i]即3.next=7后,3和7之间就相互链接了,执行完newTable[i]=e后,3被头插法重新插入到链表中,执行结果如下图所示:
套娃开始,元素5也就成了弃婴,惨~~~
不过,JDK8时已经修复了这个问题,扩容时会保持链表原来的顺序,参照HashMap扩容机制的这一篇。
、多线程下put会导致元素丢失正常情况下,当发生哈希冲突时,HashMap是这样的:
但多线程同时执行put操作时,如果计算出来的索引位置是相同的,那会造成前一个key被后一个key覆盖,从而导致元素的丢失。
put的源码:
finalVputVal(inthash,Kkey,Vvalue,booleanonlyIfAbsent,booleanevict){ Node<K,V>[]tab;Node<K,V>p;intn,i;//步骤①:tab为空则创建if((tab=table)==null||(n=tab.length)==0)n=(tab=resize()).length;//步骤②:计算index,并对null做处理if((p=tab[i=(n-1)&hash])==null)tab[i]=newNode(hash,key,value,null);else{ Node<K,V>e;Kk;//步骤③:节点key存在,直接覆盖valueif(p.hash==hash&&((k=p.key)==key||(key!=null&&key.equals(k))))e=p;//步骤④:判断该链为红黑树elseif(pinstanceofTreeNode)e=((TreeNode<K,V>)p).putTreeVal(this,tab,hash,key,value);//步骤⑤:该链为链表else{ for(intbinCount=0;;++binCount){ if((e=p.next)==null){ p.next=newNode(hash,key,value,null);//链表长度大于8转换为红黑树进行处理if(binCount>=TREEIFY_THRESHOLD-1)//-1for1sttreeifyBin(tab,hash);break;}//key已经存在直接覆盖valueif(e.hash==hash&&((k=e.key)==key||(key!=null&&key.equals(k))))break;p=e;}}//步骤⑥、直接覆盖if(e!=null){ //existingmappingforkeyVoldValue=e.value;if(!onlyIfAbsent||oldValue==null)e.value=value;afterNodeAccess(e);returnoldValue;}}++modCount;//步骤⑦:超过最大容量就扩容if(++size>threshold)resize();afterNodeInsertion(evict);returnnull;}问题发生在步骤②这里:
if((p=tab[i=(n-1)&hash])==null)tab[i]=newNode(hash,key,value,null);两个线程都执行了if语句,假设线程A先执行了tab[i]=newNode(hash,key,value,null),那table是这样的:
接着,线程B执行了tab[i]=newNode(hash,key,value,null),那table是这样的:
3被干掉了。
、put和get并发时会导致get到null线程A执行put时,因为元素个数超出阈值而出现扩容,线程B此时执行get,有可能导致这个问题。
注意来看resize源码:
finalNode<K,燕窝有无溯源码V>[]resize(){ Node<K,V>[]oldTab=table;intoldCap=(oldTab==null)?0:oldTab.length;intoldThr=threshold;intnewCap,newThr=0;if(oldCap>0){ //超过最大值就不再扩充了,就只好随你碰撞去吧if(oldCap>=MAXIMUM_CAPACITY){ threshold=Integer.MAX_VALUE;returnoldTab;}//没超过最大值,就扩充为原来的2倍elseif((newCap=oldCap<<1)<MAXIMUM_CAPACITY&&oldCap>=DEFAULT_INITIAL_CAPACITY)newThr=oldThr<<1;//doublethreshold}elseif(oldThr>0)//initialcapacitywasplacedinthresholdnewCap=oldThr;else{ //zeroinitialthresholdsignifiesusingdefaultsnewCap=DEFAULT_INITIAL_CAPACITY;newThr=(int)(DEFAULT_LOAD_FACTOR*DEFAULT_INITIAL_CAPACITY);}//计算新的resize上限if(newThr==0){ floatft=(float)newCap*loadFactor;newThr=(newCap<MAXIMUM_CAPACITY&&ft<(float)MAXIMUM_CAPACITY?(int)ft:Integer.MAX_VALUE);}threshold=newThr;@SuppressWarnings({ "rawtypes","unchecked"})Node<K,V>[]newTab=(Node<K,V>[])newNode[newCap];table=newTab;}线程A执行完table=newTab之后,线程B中的table此时也发生了变化,此时去get的时候当然会get到null了,因为元素还没有转移。
为了便于大家更系统化地学习Java,二哥已经将《Java程序员进阶之路》专栏开源到GitHub上了,大家只需轻轻地star一下,就可以和所有的小伙伴一起打怪升级了。
GitHub地址:/itwanger/toBeBetterJavaer
Redis7.0源码阅读:哈希表扩容、缩容以及rehash
当哈希值相同发生冲突时,Redis 使用链表法解决,将冲突的键值对通过链表连接,但随着数据量增加,冲突加剧,查找效率降低。负载因子衡量冲突程度,负载因子越大,冲突越严重。为优化性能,Redis 需适时扩容,将新增键值对放入新哈希桶,减少冲突。
扩容发生在 setCommand 部分,其中 dictKeyIndex 获取键值对索引,判断是否需要扩容。_dictExpandIfNeeded 函数执行扩容逻辑,条件包括:不在 rehash 过程中,哈希表初始大小为0时需扩容,或负载因子大于1且允许扩容或负载因子超过阈值。
扩容大小依据当前键值对数量计算,如哈希表长度为4,实际有9个键值对,扩容至(最小的2的n次幂大于9)。子进程存在时,dict_can_resize 为0,反之为1。fork 子进程用于写时复制,买奶粉都是源码确保持久化操作的稳定性。
哈希表缩容由 tryResizeHashTables 判断负载因子是否小于0.1,条件满足则重新调整大小。此操作在数据库定时检查,且无子进程时执行。
rehash 是为解决链式哈希效率问题,通过增加哈希桶数量分散存储,减少冲突。dictRehash 函数完成这一任务,移动键值对至新哈希表,使用位运算优化哈希计算。渐进式 rehash 通过分步操作,减少响应时间,适应不同负载情况。定时任务检测服务器空闲时,进行大步挪动哈希桶。
在 rehash 过程中,数据查询首先在原始哈希表进行,若未找到,则在新哈希表中查找。rehash 完成后,哈希表结构调整,原始表指向新表,新表内容返回原始表,实现 rehash 结果的整合。
综上所述,Redis 通过哈希表的扩容、缩容以及 rehash 动态调整哈希桶大小,优化查找效率,确保数据存储与检索的高效性。这不仅提高了 Redis 的性能,也为复杂数据存储与管理提供了有力支持。
求助,窗体隐藏和显示
这则代码告诉你如何在运行时显示或隐藏窗体的标题栏。要使一个窗口的标题栏消失,你必须去掉control box、最大化按钮和最小化按钮,并且将caption设为空。不幸的是,VB中窗体的ControlBox、MinButton和MaxButton属性在运行期是只读的,因此,你只能在设计时做这些事。其实,只要能熟练操作关于窗口式样的API,你同样能在运行时办到这一点。
新建一个项目,把以下代码写入窗体:
Private Declare Function SetWindowLong Lib "user" Alias "SetWindowLongA" _
(ByVal hwnd As Long, ByVal nIndex As Long, ByVal dwNewLong As Long) As Long
Private Declare Function GetWindowLong Lib "user" Alias "GetWindowLongA" _
(ByVal hwnd As Long, ByVal nIndex As Long) As Long
Private Const GWL_STYLE = (-)
Private Const WS_CAPTION = &HC ´ WS_BORDER 或 WS_DLGFRAME
Private Const WS_MAXIMIZEBOX = &H
Private Const WS_MINIMIZEBOX = &H
Private Const WS_SYSMENU = &H
Private Declare Function SetWindowPos Lib "user" _
(ByVal hwnd As Long, ByVal hWndInsertAfter As Long, ByVal x As Long, _
ByVal y As Long, ByVal cx As Long, ByVal cy As Long, ByVal wFlags As Long) As Long
Private Enum ESetWindowPosStyles
SWP_SHOWWINDOW = &H
SWP_HIDEWINDOW = &H
SWP_FRAMECHANGED = &H ´ The frame changed: send WM_NCCALCSIZE
SWP_NOACTIVATE = &H
SWP_NOCOPYBITS = &H
SWP_NOMOVE = &H2
SWP_NOOWNERZORDER = &H ´ Don´t do owner Z ordering
SWP_NOREDRAW = &H8
SWP_NOREPOSITION = SWP_NOOWNERZORDER
SWP_NOSIZE = &H1
SWP_NOZORDER = &H4
SWP_DRAWFRAME = SWP_FRAMECHANGED
HWND_NOTOPMOST = -2
End Enum
Private Declare Function GetWindowRect Lib "user" (ByVal hwnd As Long, lpRect As RECT) As Long
Private Type RECT
Left As Long
Top As Long
Right As Long
Bottom As Long
End Type
Private Function ShowTitleBar(ByVal bState As Boolean)
Dim lStyle As Long
Dim tR As RECT
´ 获取窗口的位置:
GetWindowRect Me.hwnd, tR
´ 调整标题栏是否可见:
lStyle = GetWindowLong(Me.hwnd, GWL_STYLE)
If (bState) Then
Me.Caption = Me.Tag
If Me.ControlBox Then
lStyle = lStyle Or WS_SYSMENU
End If
If Me.MaxButton Then
lStyle = lStyle Or WS_MAXIMIZEBOX
End If
If Me.MinButton Then
lStyle = lStyle Or WS_MINIMIZEBOX
End If
If Me.Caption <> "" Then
lStyle = lStyle Or WS_CAPTION
End If
Else
Me.Tag = Me.Caption
Me.Caption = ""
lStyle = lStyle And Not WS_SYSMENU
lStyle = lStyle And Not WS_MAXIMIZEBOX
lStyle = lStyle And Not WS_MINIMIZEBOX
lStyle = lStyle And Not WS_CAPTION
End If
SetWindowLong Me.hwnd, GWL_STYLE, lStyle
´ 重新设定窗口:
SetWindowPos Me.hwnd, 0, tR.Left, tR.Top, tR.Right - tR.Left, tR.Bottom - tR.Top, SWP_NOREPOSITION Or SWP_NOZORDER Or SWP_FRAMECHANGED
Me.Refresh
´ 你可能需要在Form_Resize中加一点代码,因为客户区的大小已经改变:
´Form_Resize
End Function
为了试验一下代码,在窗体上放一个CheckBox,将它的Value属性设为1 (Checked)。然后写入以下代码:
Private Sub Check1_Click()
If (Check1.Value = Checked) Then
ShowTitleBar True
Else
ShowTitleBar False
End If
End Sub
运行,当你点击这个CheckBox时,窗体的标题栏将会在隐藏或显示之间切换。
vector å¨c++ä¸resize åreserveçåºå«
ãresizeå°±æ¯éæ°åé 大å°ï¼reserveå°±æ¯é¢çä¸å®ç空é´ãè¿ä¸¤ä¸ªæ¥å£å³åå¨å·®å«ï¼ä¹æå ±åç¹ãä¸é¢å°±å®ä»¬çç»èè¿è¡åæã
为å®ç°resizeçè¯ä¹ï¼resizeæ¥å£åäºä¸¤ä¸ªä¿è¯ï¼
ä¸æ¯ä¿è¯åºé´[0, new_size)èå´å æ°æ®ææï¼å¦æä¸æ indexå¨æ¤åºé´å ï¼vector[indext]æ¯åæ³çã
äºæ¯ä¿è¯åºé´[0, new_size)èå´ä»¥å¤æ°æ®æ æï¼å¦æä¸æ indexå¨åºé´å¤ï¼vector[indext]æ¯éæ³çã
reserveåªæ¯ä¿è¯vectorç空é´å¤§å°(capacity)æå°è¾¾å°å®çåæ°ææå®ç大å°nãå¨åºé´[0, n)èå´å ï¼å¦æä¸æ æ¯indexï¼vector[index]è¿ç§è®¿é®æå¯è½æ¯åæ³çï¼ä¹æå¯è½æ¯éæ³çï¼è§å ·ä½æ åµèå®ã
resizeåreserveæ¥å£çå ±åç¹æ¯å®ä»¬é½ä¿è¯äºvectorç空é´å¤§å°(capacity)æå°è¾¾å°å®çåæ°ææå®ç大å°ã
å 两æ¥å£çæºä»£ç ç¸å½ç²¾ç®ï¼ä»¥è³äºå¯ä»¥å¨è¿éè´´ä¸å®ä»¬ï¼
void resize(size_type new_size) { resize(new_size, T()); }
void resize(size_type new_size, const T& x) {
if (new_size < size())
erase(begin() + new_size, end()); // eraseåºé´èå´ä»¥å¤çæ°æ®ï¼ç¡®ä¿åºé´ä»¥å¤çæ°æ®æ æ
else
insert(end(), new_size - size(), x); // å¡«è¡¥åºé´èå´å 空缺çæ°æ®ï¼ç¡®ä¿åºé´å çæ°æ®ææ
}
void reserve(size_type n) {
if (capacity() < n) {
const size_type old_size = size();
iterator tmp = allocate_and_copy(n, start, finish);
destroy(start, finish);
deallocate();
start = tmp;
finish = tmp + old_size;
end_of_storage = start + n;
}
}
äºã
vectorå¨push_backçæ¶åï¼å¦æ空é´ä¸è¶³ï¼ä¼èªå¨å¢è¡¥ä¸äºç©ºé´ï¼å¦æ没æé¢çç空é´å¯ç¨
å°±ç´æ¥ç³è¯·å¦ä¸åå¯ç¨çè¿ç»ç空é´ï¼ææ°æ®æ·è´è¿å»ï¼ç¶åå é¤æ§ç©ºé´ï¼ä½¿ç¨æ°ç©ºé´
ç»æé ææçä½ä¸
å¦æå¨äºå é¢è§å°æè¾å¤§ç©ºé´éæ±ï¼å°±å¯ä»¥å ç¨reserveé¢çä¸å®ç空é´ï¼é¿å å åéå¤åé å
大éçæ°æ®æ¬ç§»ãæé«äºæç
sizeæçæ¯é¤å»é¢ççé¢å¤ç©ºé´çææç¨æ¥åæ¾æ°æ®ç空é´ï¼resizeä¹å¥½ç解ï¼å¦æè¯´ä½ å¯¹æé¨å
没æè¿è¡åå§åï¼æ¯å¦åæ¬çsizeæ¯ï¼ç°å¨resize为个)ï¼é£å°±ç»å ¶ä½ä¸ªè°ç¨é»è®¤æé å½æ°ï¼
å¦ææ¯å 置类åï¼åå§å为0ââæ对åå§åå 置类åè¿ç¹ä¸æ¯ç¹å«è¯å®ï¼ä½ å¯ä»¥æ¥èµæï¼.
capacityè¿åçæ¯å æ¬é¢çç空é´å¨å çææ空é´å¤§å°ï¼é常è·reserveçé£ä¸ªå¤§å°ç¸å½ï¼å¦åæ ¹æ®åé çç¥è·å¾ãcapacityçæ£å¼å®ä¹ä¸ºï¼å¨ä¸éè¦éæ°åé 空é´çæ åµä¸ï¼vectorè½å®¹çº³çå ç´ çæ大æ°é
举ä¾è¯´ï¼
vector <int> v;
v.reserve();
assert(v.capacity()==);
vector <int> v;
cout < < v.capacity(); //è¿éå°±ä¾èµäºåºçå®ç°ï¼
JDK成长记7:3张图搞懂HashMap底层原理!
一句话讲, HashMap底层数据结构,JDK1.7数组+单向链表、JDK1.8数组+单向链表+红黑树。
在看过了ArrayList、LinkedList的底层源码后,相信你对阅读JDK源码已经轻车熟路了。除了List很多时候你使用最多的还有Map和Set。接下来我将用三张图和你一起来探索下HashMap的底层核心原理到底有哪些?
首先你应该知道HashMap的核心方法之一就是put。我们带着如下几个问题来看下图:
如上图所示,put方法调用了putVal方法,之后主要脉络是:
如何计算hash值?
计算hash值的算法就在第一步,对key值进行hashCode()后,对hashCode的值进行无符号右移位和hashCode值进行了异或操作。为什么这么做呢?其实涉及了很多数学知识,简单的说就是尽可能让高和低位参与运算,可以减少hash值的冲突。
默认容量和扩容阈值是多少?
如上图所示,很明显第二步回调用resize方法,获取到默认容量为,这个在源码里是1<<4得到的,1左移4位得到的。之后由于默认扩容因子是0.,所以两者相乘就是扩容大小阈值*0.=。之后就分配了一个大小为的Node[]数组,作为Key-Value对存放的数据结构。
最后一问题是,如何进行hash寻址的?
hash寻址其实就在数组中找一个位置的意思。用的算法其实也很简单,就是用数组大小和hash值进行n-1&hash运算,这个操作和对hash取模很类似,只不过这样效率更高而已。hash寻址后,就得到了一个位置,可以把key-value的Node元素放入到之前创建好的Node[]数组中了。
当你了解了上面的三个原理后,你还需要掌握如下几个问题:
还是老规矩,看如下图:
当hash值计算一致,比如当hash值都是时,Key-Value对的Node节点还有一个next指针,会以单链表的形式,将冲突的节点挂在数组同样位置。这就是数据结构中所提到解决hash 的冲突方法之一:单链法。当然还有探测法+rehash法有兴趣的人可以回顾《数据结构和算法》相关书籍。
但是当hash冲突严重的时候,单链法会造成原理链接过长,导致HashMap性能下降,因为链表需要逐个遍历性能很差。所以JDK1.8对hash冲突的算法进行了优化。当链表节点数达到8个的时候,会自动转换为红黑树,自平衡的一种二叉树,有很多特点,比如区分红和黑节点等,具体大家可以看小灰算法图解。红黑树的遍历效率是O(logn)肯定比单链表的O(n)要好很多。
总结一句话就是,hash冲突使用单链表法+红黑树来解决的。
上面的图,核心脉络是四步,源码具体的就不粘出来了。当put一个之后,map的size达到扩容阈值,就会触发rehash。你可以看到如下具体思路:
情况1:如果数组位置只有一个值:使用新的容量进行rehash,即e.hash & (newCap - 1)
情况2:如果数组位置有链表,根据 e.hash & oldCap == 0进行判断,结果为0的使用原位置,否则使用index + oldCap位置,放入元素形成新链表,这里不会和情况1新的容量进行rehash与运算了,index + oldCap这样更省性能。
情况3:如果数组位置有红黑树,根据split方法,同样根据 e.hash & oldCap == 0进行树节点个数统计,如果个数小于6,将树的结果恢复为普通Node,否则使用index + oldCap,调整红黑树位置,这里不会和新的容量进行rehash与运算了,index + oldCap这样更省性能。
你有兴趣的话,可以分别画一下这三种情况的图。这里给大家一个图,假设都出发了以上三种情况结果如下所示:
上面源码核心脉络,3个if主要是校验了一堆,没做什么事情,之后赋值了扩容因子,不传递使用默认值0.,扩容阈值threshold通过tableSizeFor(initialCapacity);进行计算。注意这里只是计算了扩容阈值,没有初始化数组。代码如下:
竟然不是大小*扩容因子?
n |= n >>> 1这句话,是在干什么?n |= n >>> 1等价于n = n | n >>>1; 而|表示位运算中的或,n>>>1表示无符号右移1位。遇到这种情况,之前你应该学到了,如果碰见复杂逻辑和算法方法就是画图或者举例子。这里你就可以举个例子:假设现在指定的容量大小是,n=cap-1=,那么计算过程应该如下:
n是int类型,java中一般是4个字节,位。所以的二进制: 。
最后n+1=,方法返回,赋值给threshold=。再次注意这里只是计算了扩容阈值,没有初始化数组。
为什么这么做呢?一句话,为了提高hash寻址和扩容计算的的效率。
因为无论扩容计算还是寻址计算,都是二进制的位运算,效率很快。另外之前你还记得取余(%)操作中如果除数是2的幂次方则等同于与其除数减一的与(&)操作。即 hash%size = hash & (size-1)。这个前提条件是除数是2的幂次方。
你可以再回顾下resize代码,看看指定了map容量,第一次put会发生什么。会将扩容阈值threshold,这样在第一次put的时候就会调用newCap = oldThr;使得创建一个容量为threshold的数组,之后从而会计算新的扩容阈值newThr为newCap*0.=*0.=。也就是说map到了个元素就会进行扩容。
除了今天知识,技能的成长,给大家带来一个金句甜点,结束我今天的分享:坚持的三个秘诀之一目标化。
坚持的秘诀除了上一节提到的视觉化,第二个秘诀就是目标化。顾名思义,就是需要给自己定立一个目标。这里要提到的是你的目标不要定的太高了。就比如你想要增加肌肉,给自己定了一个目标,每天5组,每次个俯卧撑,你看到自己胖的身形或者海报,很有刺激,结果开始前两天非常厉害,干劲十足,特别奥利给。但是第三天,你想到要个俯卧撑,你就不想起床,就算起来,可能也会把自己撅死过去......其实你的目标不要一下子定的太大,要从微习惯开始,比如我媳妇从来没有做过俯卧撑,就让她每天从1个开始,不能多,我就怕她收不住,做多了。一开始其实从习惯开始,先变成习惯,再开始慢慢加量。量太大养不成习惯,量小才能养成习惯。很容易做到才能养成,你想想是不是这个道理?
所以,坚持的第二个秘诀就是定一个目标,可以通过小量目标,养成微习惯。比如每天你可以读五分钟书或者5分钟成长记,不要多,我想超过你也会睡着了的.....
最后,大家可以在阅读完源码后,在茶余饭后的时候问问同事或同学,你也可以分享下,讲给他听听。

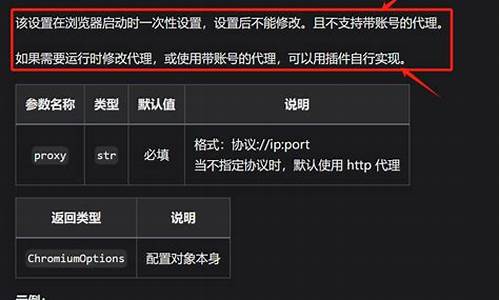



2024-11-30 17:28
2024-11-30 17:21
2024-11-30 16:53
2024-11-30 16:26
2024-11-30 15:45
