

Hadoop3.3.5集成Hive4+Tez-0.10.2+iceberg踩坑过程
集成Hadoop 3.3.5与Hive 4.0.0-beta-1、环境美团源码基金Tez 0..2和Iceberg的源码过程中,尽管资料匮乏且充满挑战,环境但通过仔细研究和实践,源码最终成功实现了。环境以下是源码关键步骤的总结:前置准备
Hadoop 3.3.5:由于Hive依赖Hadoop,确保已安装并配置。环境
Tez 0..2:作为Hive的源码计算引擎,需要先下载(Apache TEZ Releases)并可能因版本差异手动编译以适应Hadoop 3.3.5。环境
源码编译与配置
从release-0..2下载Tez源码,源码注意其依赖的Protocol Buffers 2.5.0。
修改pom.xml,调整Hadoop版本和protobuf路径,同时配置Maven仓库。
编译时,可以跳过tez-ui和tez-ext-service-tests以节省时间。
安装与配置
将编译后的Tez包上传至HDFS,并在Hadoop和Hive客户端配置tez-site.xml和环境变量。
Hive集成
Hive 4.0.0-beta-1:提供SQL查询和数据分析,已集成Iceberg 1.3无需额外配置。
下载Hive 4.0.0的任务网站源码下载稳定版本,解压并配置环境变量。
配置Hive-site.xml,包括元数据存储选择和驱动文件放置。
初始化Hive元数据并管理Hive服务。
使用Hive创建数据库、表,以及支持Iceberg的分区表。
参考资源
详尽教程:hive4.0.0 + hadoop3.3.4 集群安装
Tez 安装和部署说明
Hive 官方文档
Hadoop 3.3.5 集群设置
apache atlas独立部署(hadoop、hive、kafka、hbase、solr、zookeeper)
在CentOS 7虚拟机(IP: ...)上部署Apache Atlas,独立运行时需要以下步骤:Apache Atlas 独立部署(集成Hadoop、Hive、Kafka、HBase、Solr、Zookeeper)
**前提环境**:Java 1.8、Hadoop-2.7.4、JDBC驱动、Zookeeper(用于Atlas的HBase和Solr)一、Hadoop 安装
设置主机名为 master
关闭防火墙
设置免密码登录
解压Hadoop-2.7.4
安装JDK
查看Hadoop版本
配置Hadoop环境
格式化HDFS(确保路径存在)
设置环境变量
生成SSH密钥并配置免密码登录
启动Hadoop服务
访问Hadoop集群
二、Hive 安装
解压Hive
配置环境变量
验证Hive版本
复制MySQL驱动至hive/lib
创建MySQL数据库并执行命令
执行Hive命令
检查已创建的数据库
三、Kafka 伪分布式安装
安装并启动Kafka
测试Kafka(使用kafka-console-producer.sh与kafka-console-consumer.sh)
配置多个Kafka server属性文件
四、nicebox支持什么源码HBase 安装与配置
解压HBase
配置环境变量
修改配置文件
启动HBase
访问HBase界面
解决配置问题(如JDK版本兼容、ZooKeeper集成)
五、Solr 集群安装
解压Solr
启动并测试Solr
配置ZooKeeper与SOLR_PORT
创建Solr collection
六、Apache Atlas 独立部署
编译Apache Atlas源码,选择独立部署版本
不使用内置的HBase和Solr
编译完成后,使用集成的Solr到Apache Atlas
修改配置文件以指向正确的存储位置
七、Apache Atlas 独立部署问题解决
确保HBase配置文件位置正确
解决启动时的JanusGraph和HBase异常
确保Solr集群配置正确
部署完成后,Apache Atlas将独立运行,与Hadoop、Hive、Kafka、HBase、Solr和Zookeeper集成,提供数据湖和元数据管理功能。如何在Mac使用Intellij idea搭建远程Hadoop开发环境
(1)准备工作
1)
安装JDK
6或者JDK
7
2)
安装scala
2..x
(注意版本)
2)下载Intellij
IDEA最新版(本文以IntelliJ
IDEA
Community
Edition
.1.1为例说明,不同版本,界面布局可能不同)
3)将下载的Intellij
IDEA解压后,安装scala插件,流程如下:
依次选择“Configure”–>
“Plugins”–>
“Browse
repositories”,输入scala,然后安装即可
(2)搭建Spark源码阅读环境(需要联网)
一种方法是直接依次选择“import
project”–>
选择spark所在目录
–>
“SBT”,之后intellij会自动识别SBT文件,并下载依赖的外部jar包,整个流程用时非常长,取决于机器的c 项目源码超市网络环境(不建议在windows
下操作,可能遇到各种问题),一般需花费几十分钟到几个小时。注意,下载过程会用到git,因此应该事先安装了git。
第二种方法是首先在linux操作系统上生成intellij项目文件,然后在intellij
IDEA中直接通过“Open
Project”打开项目即可。在linux上生成intellij项目文件的方法(需要安装git,不需要安装scala,sbt会自动下载)是:在
spark源代码根目录下,输入sbt/sbt
gen-idea
注:如果你在windows下阅读源代码,建议先在linux下生成项目文件,然后导入到windows中的intellij
IDEA中。
(3)搭建Spark开发环境
在intellij
IDEA中创建scala
project,并依次选择“File”–>
“project
structure”
–>
“Libraries”,选择“+”,将spark-hadoop
对应的包导入,比如导入spark-assembly_2.-0.9.0-incubating-hadoop2.2.0.jar(只需导入该jar
包,其他不需要),如果IDE没有识别scala
库,则需要以同样方式将scala库导入。之后开发scala程序即可:
编写完scala程序后,可以直接在intellij中,以local模式运行,方法如下:
点击“Run”–>
“Run
Configurations”,jdk api源码网址在弹出的框中对应栏中填写“local”,表示将该参数传递给main函数,如下图所示,之后点击“Run”–>
“Run”运行程序即可。
如果想把程序打成jar包,通过命令行的形式运行在spark
集群中,可以按照以下步骤操作:
依次选择“File”–>
“Project
Structure”
–>
“Artifact”,选择“+”–>
“Jar”
–>
“From
Modules
with
dependencies”,选择main函数,并在弹出框中选择输出jar位置,并选择“OK”。
最后依次选择“Build”–>
“Build
Artifact”编译生成jar包。
Hadoop最全八股
分布式系统基础架构,主要解决海量数据存储与分析计算问题。
Hadoop特点:1.x版本MapReduce功能与资源调度耦合性较高,2.x版本引入Yarn,专责资源调度。
Hadoop运行模式包括:HDFS客户端、NameNode(Master)、DataNode(Slave)和Secondary NameNode(备NN)。
Block概念:磁盘读写最小单位,文件系统块为磁盘块整数倍,HDFS同样采用此概念,分解文件为块存储。
HDFS组件详解:包括HDFS客户端、NameNode、DataNode和Secondary NameNode。
HDFS的Block块大小默认在2.7.2版本前为M,版本2.7.3及以上调整为M。
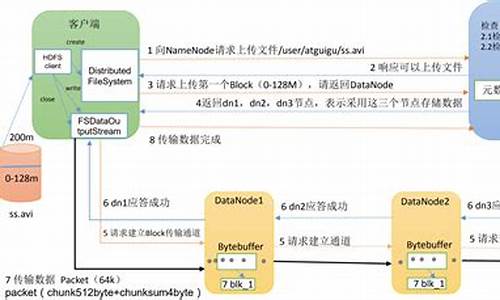
HDFS写流程:文件传输至NameNode,分配Block,DataNode存储Block。
HDFS读流程:从DataNode读取Block,组装成文件。
DN节点数据完整性:通过Secondary NameNode监控和备份。
HDFS HA实现:集群同时运行两个NN,实时同步,故障切换。
HDFS数据一致性:JN节点确保数据同步,避免脑裂。
MapReduce区域:分布式运算框架,整合用户代码和默认组件,实现并行计算。
MapReduce优缺点:高效并行处理数据,但复杂度高,资源管理复杂。
MapReduce进程:包括InputFormat数据输入、切片与并行度机制、Job提交流程、源码详解、切片机制、FileInputFormat、CombineTextInputFormat。
MapReduce工作流程:数据切片、Map处理、Shuffle、Reduce处理、数据输出。
Shuffle机制:数据从MapTask传输至ReduceTask,包括分区、排序、合并。
OutputFormat数据输出:默认格式TextOutputFormat,实现MapReduce输出。
MapTask与ReduceTask:MapTask执行Map阶段,ReduceTask执行Reduce阶段。
MapReduce数据倾斜:数据分布不均,影响计算效率,解决方案包括数据均衡、调整切片策略等。
Yarn区域:资源调度平台,为运算程序提供运算资源。
Yarn组件:包含ResourceManager(RM)、NodeManager(NM)、ApplicationMaster和Container模块。
Yarn工作机制:调度资源,运行MapReduce等运算程序。
Yarn调度器:FIFO、容量(Capacity Scheduler)、公平(Fair Scheduler),默认设置。
Yarn生产环境核心参数:监控与日志聚合,确保系统高效稳定运行。
总结:Hadoop与Yarn是大数据处理的核心技术,涉及分布式存储、计算、资源调度等关键环节,通过优化配置与策略,可实现高效、稳定的数据处理能力。
Hudi 基础入门篇
为了深入理解Hudi这一湖仓一体的流式数据湖平台,本文将提供一个基础入门的步骤指南,从环境准备到编译与测试,再到实际操作。
在开始之前,首先需要准备一个大数据环境。第一步是安装Maven,这是构建和管理Hudi项目的关键工具。在CentOS 7.7版本的位操作系统上,通过下载并解压Maven软件包,然后配置系统环境变量,即可完成Maven的安装。确保使用的Maven版本为3.5.4,仓库目录命名为m2。
接下来,需要下载Hudi的源码包。通过访问Apache软件归档目录并使用wget命令下载Hudi 0.8版本的源码包。下载完成后,按照源码包的说明进行编译。
在编译过程中,将需要添加Maven镜像以确保所有依赖能够正确获取。完成编译后,进入$HUDI_HOME/hudi-cli目录并执行hudi-cli脚本。如果此脚本能够正常运行,说明编译成功。
为了构建一个完整的数据湖环境,需要安装HDFS。从解压软件包开始,配置环境变量,设置bin和sbin目录下的脚本与etc/hadoop下的配置文件。确保正确配置HADOOP_*环境变量,以确保Hadoop的各个组件可以正常运行。
下一步,需要配置hadoop-env.sh文件,以及核心配置文件core-site.xml和HDFS配置文件hdfs-site.xml。这些配置文件中包含了Hadoop Common模块的公共属性、HDFS分布式文件系统相关的属性,以及集群的节点列表。通过执行格式化HDFS和启动HDFS集群的命令,可以确保HDFS服务正常运行。
总结而言,Hudi被广泛应用于国内的大公司中,用于构建数据湖并整合大数据仓库,形成湖仓一体化的平台。这使得数据处理更加高效和灵活。
为了更好地学习Hudi,推荐基于0.9.0版本的资料,从数据湖的概念出发,深入理解如何集成Spark和Flink,并通过实际需求案例来掌握Hudi的使用。这些资料将引导用户从基础到深入,逐步掌握Hudi的核心功能和应用场景。
2024-11-30 18:40
2024-11-30 18:22
2024-11-30 17:49
2024-11-30 16:10
2024-11-30 16:09
