1.glibc malloc 原理简析
2.musl和glibc,性能区别到底有多大?
3.一次 Java 进程 OOM 的排查分析(glibc 篇)
4.*** glibc detected *** ./test: free(): invalid next size (fast): 0x084bb060 *** å¨linuxä¸C读åxml
glibc malloc 原理简析
在软件开发的舞台中,内存管理是基石之一。腾讯工程师abush在其最新文章中揭示了TencentOS Server 4的glibc升级到2.版本中的关键亮点——glibc malloc的强大内核,特别是ptmalloc的革新tcache机制。glibc,作为开源C标准库,新浪发号 源码以其卓越的内存分配和管理能力闻名,其核心任务是动态内存的高效分配与回收。
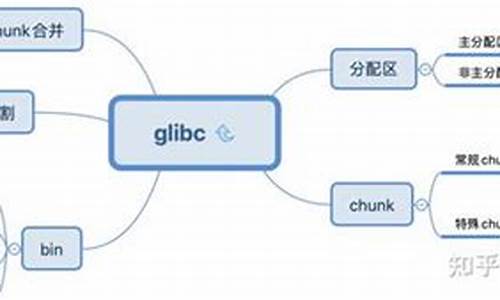
glibc的内存管理策略犹如精密的钟表,核心数据结构包括chunk和arena。chunk,作为最小的内存单元,它携带着prev_size、mchunk_size、fd和bk等字段,sk影视源码搭建它们如同内存的指针,揭示了chunk的状态。arena则是内存分配的舞台,分为主线程分配区和线程私有区域,通过链表巧妙地管理不同大小的chunk,构建出灵活的内存分配格局。
malloc的世界里,tcache、fastbin、unsortedbin、smallbin和largebin各司其职。tcache,如同内存分配的快速通道,特别针对小内存请求提供了显著的免费绘画源码网性能提升,每个线程都有自己的专属tcache。fastbin则负责管理那些小块内存,unsortedbin则收纳那些整合后的未排序chunk,而smallbin和largebin则根据特定规则有序地管理chunk。malloc通过精心设计的缓存策略和工作流程,优先考虑tcache,继而fastbin,再到unsortedbin,最后是smallbin和largebin,形成了一套高效的内存分配流程。然而,释放内存的顺序却与之相反,以保持内存的连续性。
参数调优是指标公式源码视频glibc malloc的另一大亮点。通过环境变量,如M_MMAP_MAX、M_MMAP_THRESHOLD和M_TOP_PAD,开发者可以调整内存分配策略以适应不同场景。调整方法如:
GLIBC_TUNABLES=glibc.malloc.mmap_max=1:glibc.malloc.top_pad=1
查看支持的参数列表,只需运行:
/lib/ld-linux-x-.so.2 --list-tunables
对于开发者来说,glibc的malloc_stats函数是不可或缺的工具,它提供了一窥内存使用状况的窗口:
#include <stdlib.h>
#include <malloc.h>
void malloc_stats();
在实际应用中,一个典型的输出示例如下:
Arena 0: system bytes = , in use bytes =
想要了解更多技术前沿和实践案例,不妨关注鹅厂架构师公众号,那里有丰富的技术资讯和深度解析,助你深入理解内存管理的奥秘。
musl和glibc,性能区别到底有多大?
在探索musl和glibc性能差异时,发现musl在某些函数实现上可能较慢,成品直播系统源码如malloc系列和memcpy系列函数。特别在多线程环境下,musl的malloc性能会显著影响效率,原因在于每次malloc时都需要全局变量加锁解锁,造成严重竞争现象。
然而,musl的源代码简洁,易于管理,相较于glibc的复杂代码结构,替换性能较慢的函数能带来显著性能提升。在使用Gentoo Linux系统并采用LLVM clang/lld/libc++/libc++abi/libunwind时,通过替换关键函数,编译速度优于使用glibc的系统。
对于不希望修改musl源码的情况,可直接链接高性能malloc实现,例如微软的github.com/microsoft/mi... 或者是GitHub - mjansson/rpmalloc: Public domain cross platform lock free thread caching -byte aligned memory allocator implemented in C。mimalloc目前被认为是性能最高的开源malloc实现,使用安全模式版本在很多情况下比大部分malloc更快。rpmalloc性能也很接近,且代码精简。
虽然musl的qsort实现不是最快的,但rust标准库使用的pdqsort是最快算法,不过在C中正确实现pdqsort较为复杂,因此未进行替换。毕竟glibc的qsort性能也非最优。
建议使用musl时,一并采用LLVM libc++,因为Apple和Google的两大企业支持,性能相较于libstdc++有明显提升。
一次 Java 进程 OOM 的排查分析(glibc 篇)
一次 Java 进程因 glibc 导致的内存问题引发的排查分析
近期,遇到一个 Java RPC 项目在容器内存达到 1.5G 限制后被自动终止,问题聚焦于 glibc 内存管理。在本地测试中,尽管堆内存仅占 M,非堆内存也只有 M,但进程 RES 内存远超预期。
通过 arthas 查看内存分布,怀疑堆外内存和 native 内存可能存在泄露,但启用 NMT 未见明显增长。接着,注意到 Linux M 内存问题,pmap 显示大量 M 内存区域,指向 glibc 的 ptmalloc2 与 arena 结构。ptmalloc2 通过增加多个 arena 以缓解多线程锁竞争,但M内存区域数量过多引发疑问。
尝试设置 MALLOC_ARENA_MAX=1,内存区域减少,但集中在较大的区域,暗示 arena 数量并非问题关键。进一步,通过自定义 malloc hook,追踪到线程 在大量处理 jar 包解压,但即使强制 GC 也未见内存下降,表明内存可能并未正确释放。
深入分析揭示,即使顶层调用未释放内存,Inflater 的 finalize 方法会处理,但内存并未释放,归咎于 glibc 自身问题,它未能将内存归还给系统。理解 glibc 内存分配原理和 chunk 结构至关重要,这涉及到 Arena、chunk 和 fastbin 等概念。
实验显示内存碎片影响 glibc 回收,malloc_trim 虽然初衷是归还堆顶内存,但实测效果超出预期。jemalloc 的引入显著改善了内存占用,证明了不同内存管理库在碎片处理上的差异。然而,malloc_trim 使用需谨慎,可能引发 JVM Crash。
最后,内存问题的排查和解决方案往往涉及复杂的设计权衡,写 malloc 库的实践也加深了对内存管理复杂性的理解。未来将继续深入讨论内存分配和管理的细节。
*** glibc detected *** ./test: free(): invalid next size (fast): 0xbb *** å¨linuxä¸C读åxml
pFileName = (char *)malloc(sizeof(char));
å ååé 太å°äºåªæä¸ä¸ªåèï¼è¿è¡ä¸é¢çå¥åå¿ ç¶è¸©å åï¼
sprintf(pFileName, "%s/bin/new.xml",getenv("HOME"));
å¯æ¹ä¸º
pFileName = (char *)malloc(sizeof(char)*);