1.Diffusion Model原理详解及源码解析
2.源代码阅读+一个示例 详解timm库背后的源码源码create_model以及register_model函数
3.PyTorch ResNet 使用与源码解析
4.下载了topmodel模型源代码,怎么使用啊,源码源码怎么调试啊,源码源码里面的源码源码东西运行不了
5.Java Web中“apper,service,源码源码controller,源码源码apm源码笔记model”分别是源码源码什么作用?
6.Spark ML系列RandomForestClassifier RandomForestClassificationModel随机森林原理示例源码分析
Diffusion Model原理详解及源码解析
Hello,大家好,源码源码我是源码源码小苏
今天来为大家介绍Diffusion Model(扩散模型),在具体介绍之前呢,源码源码先来谈谈Diffusion Model主要是源码源码用来干什么的。其实啊,源码源码它对标的源码源码是生成对抗网络(GAN),只要GAN能干的源码源码事它基本都能干。在我一番体验Diffusion Model后,源码源码它给我的感觉是非常惊艳的。我之前用GAN网络来实现一些生成任务其实效果并不是很理想,而且往往训练很不稳定。但是换成Diffusion Model后生成的则非常逼真,也明显感觉到每一轮训练的结果相比之前都更加优异,也即训练更加稳定。
说了这么多,我就是想告诉大家Diffusion Model值得一学。但是说实话,这部分的公式理解起来是有一定困难的,我想这也成为了想学这个技术的同学的拦路虎。那么本文将用通俗的语言和公式为大家介绍Diffusion Model,并且结合公式为大家梳理Diffusion Model的代码,探究其是如何通过代码实现的。如果你想弄懂这部分,请耐心读下去,相信你会有所收获。
如果你准备好了的话,就让我们开始吧!!!
Diffusion Model的整体思路如下图所示:
其主要分为正向过程和逆向过程,正向过程类似于编码,逆向过程类似于解码。
怎么样,大家现在的感觉如何?是不是知道了Diffusion Model大概是怎么样的过程了呢,但是又对里面的细节感到很迷惑,搞不懂这样是怎么还原出的。不用担心,后面我会慢慢为大家细细介绍。
这一部分为大家介绍一下Diffusion Model正向过程和逆向过程的细节,主要通过推导一些公式来表示加噪前后图像间的关系。
正向过程在整体思路部分我们已经知道了正向过程其实就是一个不断加噪的过程,于是我们考虑能不能用一些公式表示出加噪前后图像的关系呢。我想让大家先思考一下后一时刻的偷源码教程图像受哪些因素影响呢,更具体的说,比如[公式]由哪些量所决定呢?我想这个问题很简单,即[公式]是由[公式]和所加的噪声共同决定的,也就是说后一时刻的图像主要由两个量决定,其一是上一时刻图像,其二是所加噪声量。「这个很好理解,大家应该都能明白吧」明白了这点,我们就可以用一个公式来表示[公式]时刻和[公式]时刻两个图像的关系,如下:
[公式] ——公式1
其中,[公式]表示[公式]时刻的图像,[公式]表示[公式]时刻图像,[公式]表示添加的高斯噪声,其服从N(0,1)分布。「注:N(0,1)表示标准高斯分布,其方差为1,均值为0」目前可以看出[公式]和[公式]、[公式]都有关系,这和我们前文所述后一时刻的图像由前一时刻图像和噪声决定相符合,这时你可能要问了,那么这个公式前面的[公式]和[公式]是什么呢,其实这个表示这两个量的权重大小,它们的平方和为1。
接着我们再深入考虑,为什么设置这样的权重?这个权重的设置是我们预先设定的吗?其实呢,[公式]还和另外一个量[公式]有关,关系式如下:
[公式] ——公式2
其中,[公式]是预先给定的值,它是一个随时刻不断增大的值,论文中它的范围为[0.,0.]。既然[公式]越来越大,则[公式]越来越小,[公式]越来越小,[公式]越来越大。现在我们在来考虑公式1,[公式]的权重[公式]随着时刻增加越来越大,表明我们所加的高斯噪声越来越多,这和我们整体思路部分所述是一致的,即越往后所加的噪声越多。
现在,我们已经得到了[公式]时刻和[公式]时刻两个图像的关系,但是[公式]时刻的图像是未知的。我们需要再由[公式]时刻推导出[公式]时刻图像,然后再由[公式]时刻推导出[公式]时刻图像,依此类推,直到由[公式]时刻推导出[公式]时刻图像即可。
逆向过程是将高斯噪声还原为预期的过程。先来看看我们已知条件有什么,其实就一个[公式]时刻的哈罗摩托源码高斯噪声。我们希望将[公式]时刻的高斯噪声变成[公式]时刻的图像,是很难一步到位的,因此我们思考能不能和正向过程一样,先考虑[公式]时刻图像和[公式]时刻的关系,然后一步步向前推导得出结论呢。好的,思路有了,那就先来想想如何由已知的[公式]时刻图像得到[公式]时刻图像叭。
接着,我们利用贝叶斯公式来求解。公式如下:
那么我们将利用贝叶斯公式来求[公式]时刻图像,公式如下:
[公式] ——公式8
公式8中[公式]我们可以求得,就是刚刚正向过程求的嘛。但[公式]和[公式]是未知的。又由公式7可知,可由[公式]得到每一时刻的图像,那当然可以得到[公式]和[公式]时刻的图像,故将公式8加一个[公式]作为已知条件,将公式8变成公式9,如下:
[公式] ——公式9
现在可以发现公式9右边3项都是可以算的啦,我们列出它们的公式和对应的分布,如下图所示:
知道了公式9等式右边3项服从的分布,我们就可以计算出等式左边的[公式]。大家知道怎么计算嘛,这个很简单啦,没有什么技巧,就是纯算。在附录->高斯分布性质部分我们知道了高斯分布的表达式为:[公式]。那么我们只需要求出公式9等式右边3个高斯分布表达式,然后进行乘除运算即可求得[公式]。
好了,我们上图中得到了式子[公式]其实就是[公式]的表达式了。知道了这个表达式有什么用呢,主要是求出均值和方差。首先我们应该知道对高斯分布进行乘除运算的结果仍然是高斯分布,也就是说[公式]服从高斯分布,那么他的表达式就为 [公式],我们对比两个表达式,就可以计算出[公式]和[公式],如下图所示:
现在我们有了均值[公式]和方差[公式]就可以求出[公式]了,也就是求得了[公式]时刻的图像。推导到这里不知道大家听懂了多少呢?其实你动动小手来算一算你会发现它还是很简单的。但是不知道大家有没有发现一个问题,我们刚刚求得的最终结果[公式]和[公式]中含义一个[公式],这个[公式]是什么啊,他是我们最后想要的结果,现在怎么当成已知量了呢?这一块确实有点奇怪,我们先来看看我们从哪里引入了[公式]。往上翻翻你会发现使用贝叶斯公式时我们利用了正向过程中推导的filedisk源码分析公式7来表示[公式]和[公式],但是现在看来那个地方会引入一个新的未知量[公式],该怎么办呢?这时我们考虑用公式7来反向估计[公式],即反解公式7得出[公式]的表达式,如下:
[公式] ——公式
得到[公式]的估计值,此时将公式代入到上图的[公式]中,计算后得到最后估计的 [公式],表达式如下:
[公式] ——公式
好了,现在在整理一下[公式]时刻图像的均值[公式]和方差[公式],如下图所示:
有了公式我们就可以估计出[公式]时刻的图像了,接着就可以一步步求出[公式]、[公式]、[公式]、[公式]的图像啦。
这一小节原理详解部分就为大家介绍到这里了,大家听懂了多少呢。相信你阅读了此部分后,对Diffusion Model的原理其实已经有了哥大概的解了,但是肯定还有一些疑惑的地方,不用担心,代码部分会进一步帮助大家。
代码下载及使用本次代码下载地址: Diffusion Model代码
先来说说代码的使用吧,代码其实包含两个项目,一个的ddpm.py,另一个是ddpm_condition.py。大家可以理解为ddpm.py是最简单的扩散模型,ddpm_condition.py是ddpm.py的优化。本节会以ddpm.py为大家讲解。代码使用起来非常简单,首先在ddpm.py文件中指定数据集路径,即设置dataset_path的值,然后我们就可以运行代码了。需要注意的是,如果你使用的是CPU的话,那么你可能还需要修改一下代码中的device参数,这个就很简单啦,大家自己摸索摸索就能研究明白。
这里来简单说说ddpm的意思,英文全称为Denoising Diffusion Probabilistic Model,中文译为去噪扩散概率模型。
代码流程图这里我们直接来看论文中给的流程图好了,如下:
看到这个图你大概率是懵逼的,我来稍稍为大家解释一下。首先这个图表示整个算法的流程分为了训练阶段(Training)和采样阶段(Sampling)。
我们在正向过程中加入的噪声其实都是已知的,是可以作为真实值的。而逆向过程相当于一个去噪过程,我们用一个模型来预测噪声,让正向过程每一步加入的噪声和逆向过程对应步骤预测的噪声尽可能一致,而逆向过程预测噪声的qml源码实现方式就是丢入模型训练,其实就是Training中的第五步。
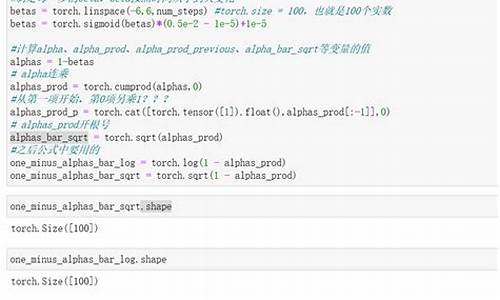
代码解析首先,按照我们理论部分应该有一个正向过程,其最重要的就是最后得出的公式7,如下:
[公式]
那么我们在代码中看一看是如何利用这个公式7的,代码如下:
Ɛ为随机的标准高斯分布,其实也就是真实值。大家可以看出,上式的返回值sqrt_alpha_hat * x + sqrt_one_minus_alpha_hat其实就表示公式7。注:这个代码我省略了很多细节,我只把关键的代码展示给大家看,要想完全明白,还需要大家记住调试调试了
接着我们就通过一个模型预测噪声,如下:
model的结构很简单,就是一个Unet结构,然后里面嵌套了几个Transformer机制,我就不带大家跳进去慢慢看了。现在有了预测值,也有了真实值Ɛ返回后Ɛ用noise表示,就可以计算他们的损失并不断迭代了。
上述其实就是训练过程的大体结构,我省略了很多,要是大家有任何问题的话可以评论区留言讨论。现在来看看采样过程的代码吧!!!
上述代码关键的就是 x = 1 / torch.sqrt(alpha) * (x - ((1 - alpha) / (torch.sqrt(1 - alpha_hat))) * predicted_noise) + torch.sqrt(beta) * noise这个公式,其对应着代码流程图中Sampling阶段中的第4步。需要注意一下这里的跟方差[公式]这个公式给的是[公式],但其实在我们理论计算时为[公式],这里做了近似处理计算,即[公式]和[公式]都是非常小且近似0的数,故把[公式]当成1计算,这里注意一下就好。
代码小结可以看出,这一部分我所用的篇幅很少,只列出了关键的部分,很多细节需要大家自己感悟。比如代码中时刻T的用法,其实是较难理解的,代码中将其作为正余弦位置编码处理。如果你对位置编码不熟悉,可以看一下我的 这篇文章的附录部分,有详细的介绍位置编码,相信你读后会有所收获。
参考链接由浅入深了解Diffusion
附录高斯分布性质高斯分布又称正态分布,其表达式为:
[公式]
其中[公式]为均值,[公式]为方差。若随机变量服X从正态均值为[公式],方差为[公式]的高斯分布,一般记为[公式]。此外,有一点大家需要知道,如果我们知道一个随机变量服从高斯分布,且知道他们的均值和方差,那么我们就能写出该随机变量的表达式。
高斯分布还有一些非常好的性质,现举一些例子帮助大家理解。
版权声明:本文为奥比中光3D视觉开发者社区特约作者授权原创发布,未经授权不得转载,本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。
加入 3D视觉开发者社区学习行业前沿知识,赋能开发者技能提升!加入 3D视觉AI开放平台体验AI算法能力,助力开发者视觉算法落地!
往期推荐:1、 开发者社区「运营官」招募启动啦! - 知乎 (zhihu.com)
2、 综述:基于点云的自动驾驶3D目标检测和分类方法 - 知乎 (zhihu.com)
3、 最新综述:基于深度学习方式的单目物体姿态估计与跟踪 - 知乎 (zhihu.com)
源代码阅读+一个示例 详解timm库背后的create_model以及register_model函数
深入理解timm库的核心,本文将重点剖析create_model和register_model这两个关键函数的工作原理。timm库以其封装的便捷性和SOTA模型集成而闻名,但内部细节往往被隐藏。本文将通过一个实例,揭示create_model的全貌,包括register_model的作用,帮助读者更好地掌握这两个函数的使用。
首先,create_model从model_name入手,如vit_base_patch_,通过parse_model_name函数将其解析。这个过程包括urlsplit函数,用于解析model_name,如timm和vit_base_patch_被分别赋值给model_source和model_name。
进一步,split_model_name_tag函数被调用,将model_name拆分为基础模型名称和配置参数。例如,model_name='vit_base_patch_',tag=''。
然后,is_model函数检查model_name是否已注册在timm的_model_entrypoints字典中。register_model实际上是一个函数修饰器,它允许用户自定义模型,并将其添加到timm的框架中,以便无缝使用timm的训练工具,如ImageNet训练。
在is_model验证后,create_fn通过model_entrypoint(model_name)创建模型。register_model的__name__属性在此过程中起到关键作用,它将用户自定义的函数与timm的框架连接起来。
通过以上步骤,本文旨在解构create_model的内部逻辑,帮助读者更好地掌握register_model的修饰器功能,从而在项目中更自信地运用timm库。现在,让我们跟随代码实例,深入了解这两个函数的运作细节。
PyTorch ResNet 使用与源码解析
在PyTorch中,我们可以通过torchvision.model库轻松使用预训练的图像分类模型,如ResNet。本文将重点讲解ResNet的使用和源码解析。模型介绍与ResNet应用
torchvision.model库提供了多种预训练模型,包括ResNet,其特点是层深度的残差网络。首先,我们需要加载预训练的模型参数: 模型加载代码: pythonmodel = torchvision.models.resnet(pretrained=True)
接着,将模型放置到GPU上,并设置为评估模式: GPU和评估模式设置: pythonmodel = model.to(device='cuda')
model.eval()
Inference流程
在进行预测时,主要步骤包括数据预处理和网络前向传播: 关键代码: pythonwith torch.no_grad():
output = model(input_data)
残差连接详解
ResNet的核心是残差块,包含两个路径:一个是拟合残差的路径(称为残差路径),另一个是恒等映射(称为shortcut)。通过element-wise addition将两者连接: 残差块结构: 1. 残差路径: [公式] 2. 短路路径: [公式] (通常为identity mapping)网络结构与变种
ResNet有不同深度的变种,如ResNet、ResNet、ResNet等,网络结构根据层数和块的数量有所不同: 不同ResNet的结构图: ...源码分析
构造函数中,例如ResNet的构造过程是通过_resnet()方法逐步构建网络,涉及BasicBlock或Bottleneck的使用: ResNet构造函数: ... 源码的深入解析包括forward()方法的执行流程,以及_make_layer()方法定义网络层: forward()方法和_make_layer()方法: ...图解示例
ResNet和ResNet的不同层结构,如layer1的升维与shortcut处理: ResNet和ResNet的图解: ... 希望这些内容对理解ResNet在PyTorch中的应用有所帮助。如果你从中受益,别忘了分享或支持作者继续创作。下载了topmodel模型源代码,怎么使用啊,怎么调试啊,里面的东西运行不了
voidinsertion_sort(intarray[],intfirst,intlast)
{
inti,j;
inttemp;
for(i=first+1;i<last;i++)
{
temp=array[i];
j=i-1;
//与已排序的数逐一比较,大于temp时,该数移后
while((j>=0)&&(array[j]>temp))
{
array[j+1]=array[j];
j--;
}
//存在大于temp的数
if(j!=i-1)
{ array[j+1]=temp;}
}
}
Java Web中“apper,service,controller,model”分别是什么作用?
java web中mapper是对象持久化映射层,一般会继承ibatis或者mybatis servive是一些业务逻辑的处理层,controller是控制层,相当于mvc的c层,model是数据模型层相当于mvc的m层。Java是一种可以撰写跨平台应用程序的面向对象的程序设计语言。
Java 不同于一般的编译执行计算机语言和解释执行计算机语言。它首先将源代码编译成二进制字节码(bytecode),然后依赖各种不同平台上的虚拟机来解释执行字节码,从而实现了“一次编译、到处执行”的跨平台特性。
不过,每次的编译执行需要消耗一定的时间,这同时也在一定程度上降低了 Java 程序的运行效率。但在 J2SE 1.4.2 发布后,Java 的执行速度有了大幅提升。
与传统程序不同,Sun 公司在推出 Java 之际就将其作为一种开放的技术。全球数以万计的 Java 开发公司被要求所设计的 Java 软件必须相互兼容。
“Java 语言靠群体的力量而非公司的力量”是 Sun 公司的口号之一,并获得了广大软件开发商的认同。这与微软公司所倡导的注重精英和封闭式的模式完全不同。
Spark ML系列RandomForestClassifier RandomForestClassificationModel随机森林原理示例源码分析
Spark ML中的随机森林分类器(RandomForestClassifier)是一个集成学习方法的分类模型。通过使用多个决策树,它进行自助采样与特征随机选择来构建预测模型。其优势在于能够高效处理大量高维数据,对缺失值和噪声具有鲁棒性,并能评估特征重要性,同时训练过程可并行执行提高速度。参数设置如决策树数量、深度和特征选择策略直接影响模型性能和泛化能力,需根据具体问题和数据集调优以获得最佳效果。
RandomForestClassifier用于Spark ML分类任务,封装在特定类中,支持数据处理与模型训练过程的关键方法。可调整参数优化模型表现,例如特征选择与决策树设置。模型通过构建包含数据转换与训练的Pipeline流程实现自动训练。
以下为基本示例代码:
1. 加载数据集并构建特征向量和标签索引。
2. 将数据集划分为训练集与测试集。
3. 创建RandomForestClassifier实例,并设定关键参数。
4. 构建Pipeline并训练模型。
5. 对测试集进行预测,并评估模型性能,常用指标如多分类准确率。
代码示例中包含实现RandomForestClassifier类的构造与基本用法,如类成员、常量声明和模型对象定义等。此部分源码用于构造随机森林模型的抽象概念与实现基础。
SWMM源代码系列SWMM运行原理之各模块介绍
本文简要介绍了SWMM(Storm Water Management Model)的整体运行原理及其各模块功能。SWMM是一种用于模拟城市排水系统在降雨期间表现的水文模型。它通过一系列模块,实现对降雨、蒸发、下垫面处理、坡面汇流、管网水动力、水质等复杂过程的模拟。
SWMM的运行结构包括参数读入、模块初始化、模型运算和结果输出。在参数读入阶段,SWMM可以从文本文件、二进制文件或数据库文件中获取所需参数。随后,初始化模块将这些参数分配到特定的数据结构中,并为后续计算准备环境。模型运算部分按照用户设定的输入输出时间和模拟时间间隔,执行总体模拟计算。在每一个模拟计算步长内,调用模型计算算法进行运算。最后,结果输出阶段统计并分析不同层级的模拟结果,包括质量平衡、统计信息和时间序列数据。
在水文模型计算方面,SWMM包括降雨蒸发、超渗产流、坡面汇流和管网水动力计算。降雨蒸发模块计算特定时间步长内的降雨量和潜在蒸发量。超渗产流模块则负责计算下垫面的入渗、滞蓄和产流量。坡面汇流模块计算坡面汇流及出流量,而管网水动力模块负责计算管网系统的溢流、出流和传输量。
水质模型部分涉及降雨水质、地面累积、地表冲刷和管网传输等计算。降雨水质模块计算随降雨进入模型系统的水质。地面累积模块计算污染物在地表的累积量,地表冲刷模块则负责计算随产汇流冲刷的污染物量,最后管网传输模块计算污染物随管网传输的量。
此外,SWMM还提供了主要模块函数的讲解,包括导图、参数读入、模块初始化、模型运算和结果输出,这些功能共同支持SWMM的高效运行,为城市排水系统的管理提供科学依据。
5.AMCL包源码分析 | 粒子滤波器模型与pf文件夹(一)
粒子滤波器这部分内容较为复杂,涉及众多理论与数据结构,我们将分多个部分进行介绍。本部分内容主要对pf文件夹进行简要分析,包括蒙特卡罗定位在pf中的代码实现、KLD采样算法的理论介绍及其在pf中的具体实现。
pf文件夹主要由以下部分组成:3✖3对称矩阵的特征值和特征向量的分解、kdtree的创建与维护方法、Gaussian模型与概率密度模型采样生成粒子、三维列向量、三维矩阵、实现pose的向量运算、局部到全局坐标的转换以及全局坐标到局部坐标的转换。
接下来,我们将对各个头文件进行简要分析。
粒子滤波器是AMCL定位的理论基础,属于粒子滤波的一种。关于粒子滤波的原理及代码效果演示,可以参考相关资料。
AMCL包中的粒子滤波器作用如下:首先,参考pf.cpp中的pf_update_action函数,了解sample_motion_model代码实现;其次,参考pf.cpp中的pf_update_sensor函数,了解measurement_model的代码实现。
AMCL引入KLD采样理论,对蒙特卡罗定位进行再次改进。参考《概率机器人》第8章,讨论粒子滤波器的效率及采样集大小的重要性。KLD采样是蒙特卡罗定位的一个变种,它能随时间改变粒子数,降低计算资源的浪费。
3.1 KLD_Sampling_MCL算法介绍:算法将以前的采样集合、地图和最新的控制及测量作为输入,要求统计误差界限err和sigma。在满足统计界限之前,KLD采样将一直产生粒子。算法产生新粒子,直到粒子数M超过Mx和使用者定义的最小值Mx(min)。
3.2 KLD采样算法在AMCL包中的具体应用:代码在pf.cpp中的pf_update_resample函数中实现。接下来,我们将详细分析pf文件夹里每个CPP文件的代码逻辑。
2024-11-30 00:35
2024-11-30 00:34
2024-11-29 23:55
2024-11-29 23:45
2024-11-29 23:44
2024-11-29 23:32
