

第二十四章 解读Pytorch中多GPU并行计算教程
在Pytorch中进行多GPU并行计算,可显著加速训练过程。教程代码在github.com/WZMIAOMIAO/d...,位于pytorch_classification模块下的train_multi_GPU文件夹内。两种常见多GPU使用方法:使用多块GPU加速训练。
下图展示了多GPU并行加速的在本地搭建源码训练时间对比。测试环境:Pytorch1.7,CUDA.1,使用ResNet模型与flower_photos数据集,BatchSize为,GPU为Tesla V。通过左侧柱状图,可以看出多GPU加速效果并非线性倍增,涉及多GPU间的通信。
多GPU并行训练需注意,尽管Pytorch框架处理了部分工作,但需了解其背后机制。下图展示了使用单GPU与多GPU(不使用SyncBatchNorm)训练的曲线对比。不使用SyncBatchNorm时,多GPU训练结果与单GPU相近但速度快,使用SyncBatchNorm则能取得稍高的mAP。
Pytorch提供两种多GPU训练方法:DataParallel与DistributedDataParallel。DistributedDataParallel推荐使用,适用于多机多卡场景。下图展示了两者对比,DistributedDataParallel在单机多卡与多机多卡环境中表现更佳。
Pytorch中多GPU训练常用启动方式包括torch.distributed.launch与torch.multiprocessing。torch.distributed.launch更方便,官方多GPU训练FasterRCNN源码采用此方式。torch.multiprocessing提供更灵活的控制。使用torch.distributed.launch时,建议使用nvidia-smi指令确认GPU显存是否释放,避免资源占用导致训练问题。
train_multi_gpu_using_launch.py脚本基于已有知识扩展,涉及模型搭建与自定义数据集,更多细节请查看之前视频。使用该脚本需通过torch.distributed.launch启动,js 源码树设置nproc_per_node参数确定使用GPU数量。使用指令启动训练,指定GPU时需使用指定指令,如使用第1块和第4块GPU。
在使用torch.distributed.launch启动时,系统自动在os.environ中添加RANK、WORLD_SIZE、LOCAL_RANK参数,用于初始化进程组,分配GPU设备。All-Reduce操作在多GPU并行计算中至关重要。脚本代码已做注释,便于理解。要运行脚本,需先克隆项目,引入其他函数如模型与数据集部分。
BatchNorm理解(含Pytorch部分源码)
深度学习中,数据归一化是关键。神经网络学习数据分布以在测试集上达到泛化效果。然而,若每个batch输入数据分布不同,即Covariate Shift,这会带来训练挑战。数据经过多层网络后,分布发生改变,形成Internal Covariate Shift,这进一步增加了下层网络学习的难度。为解决中间层Internal Covariate Shift问题,引入了Batch Normalization(BN)操作。
BN算法流程如下:
(1)计算输入批量数据的均值。
(2)计算输入批量数据的方差。
(3)对每个数据进行归一化。
(4)引入缩放变量和平移变量,通过训练更新,计算归一化后的值。
BN中均值方差计算基于张量数据,vb modbustcp源码通常维度为[N, H, W, C]。其中N为batch_size,H和W为特征图尺寸,C为通道数。均值计算是每个通道内数字总和除以[N, H, W]。例如,对于[2,2,2,3]输入,代表2个batch,每个batch有3个特征图(通道数为3),每个特征图大小为2*2。以通道1为例,计算步骤如下:
均值计算公式为:均值=(所有数字总和)/ [N, H, W]。
最终获得三个通道的均值和方差,网络更新参数,为每一个channel对应一个缩放变量和平移变量。
在Pytorch中,BN通过_NormBase类和_BatchNorm类实现。_NormBase类定义BN相关的属性,_BatchNorm类继承自_NormBase,是BatchNorm2d实际调用的类。具体源码包括定义属性、计算均值和方差、归一化以及参数更新等关键步骤。
Pytorch源码剖析:nn.Module功能介绍及实现原理
nn.Module作为Pytorch的核心类,是构建模型的基础。它提供了一系列功能,包括记录模型的参数,实现网络的前向传播,加载和保存模型数据,以及进行设备和数据类型转换等。这些功能在模型的训练和应用中起到关键作用。
在训练与评估模式间切换,模块的行为会有所不同,如rrelu、dropout、batchnorm等操作在两种模式下表现不同。指令指标源码可学习的参数,如权重和偏置,需要通过梯度下降进行更新。非学习参数,比如batchnorm的running_mean,是训练过程中的统计结果。_buffers包含的Tensor不作为模型的一部分保存。
模块内部包含一系列钩子(hook)函数,用于在特定的前向传播或反向传播阶段执行自定义操作。子模块列表用于存储模型中的所有子模块。
魔术函数__init__在声明对象时自动调用,优化性能的关键在于使用super().__setattr__而非直接赋值。super调用父类的方法,避免不必要的检查,提高效率。使用register_buffer为模块注册可变的中间结果,例如BatchNorm的running_mean。register_parameter用于注册需要梯度下降更新的参数。
递归应用函数用于对模型进行操作,如参数初始化。可以将模型移动到指定设备,转换数据类型,以及注册钩子函数以实现对网络的扩展和修改。
调用魔术方法__call__执行前向传播。nn.Module未实现forward函数,子类需要提供此方法的具体实现。对于线性层等,forward函数定义了特定的运算流程。从检查点加载参数时,模块自动处理兼容性问题,确保模型结构与参数值的兼容。
模块的__setattr__方法被重写,以区别对待Parameter、Module和Buffer。当尝试设置这些特定类型的属性时,执行注册或更新操作。谷米gps源码其他属性的设置遵循标准的Python行为。
模块的save方法用于保存模型参数和状态,确保模型结构和参数值在不同设备间转移时的一致性。改变训练状态(如将模型切换到训练或评估模式)是模块管理过程的重要组成部分。
nn.Module中register_buffer用法
register_buffer是一个关键方法,用于在Module类中记录那些无需计算梯度但需与模型参数一同保存、加载或移动的变量。
例如,BatchNorm组件中的均值与方差无需计算梯度,但需要在模型中保存,故此方法得以应用。
下文展示Module类的部分源码截图,子类模型在继承自Module后,可借助self.register_buffer方法调用该缓冲区。
以BatchNorm2d为例,该类继承自Module,用于保存均值running_mean与方差running_var。
接下来,我们通过一个示例来展示如何初始化可学习参数和不可学习参数。
通过对比可学习参数b与缓冲区变量a,可以发现a始终没有梯度,仅是一个tensor数据,而model.b为:
Mo 人工智能技术博客图像翻译——pix2pix模型
在图像处理的探索中,一项革命性的技术——Pix2pix,正在将输入图像翻译成所需的输出,如同语言间的流畅转换。Pix2pix的目标是构建一个通用架构,以解决这种跨领域的转换问题,避免为每种功能单独设计复杂的损失函数,从而实现高效的一体化处理。 其核心理念在于结构化损失的引入。传统方法往往将输出空间视为无序的,Pix2pix则凭借条件生成对抗网络(cGAN)的力量,学习如何捕捉输出与目标的整体结构,使之更具可预测性和一致性。 借鉴了cGAN的精髓,Pix2pix并不局限于特定的应用场景,而是采用了U-Net生成器和卷积 PatchGAN 辨别器,确保了生成图像的高质量和精准度。生成器的设计特别考虑了高分辨率输入与输出之间的结构对应,使得输出图像与实际内容更为贴近。 损失函数是Pix2pix的灵魂所在,它结合了对抗损失和L1 Loss,旨在确保输入与输出的相似度,同时保持细节清晰。最终的优化目标是这两者之间的平衡,以达到最佳的生成效果。 网络架构中,convolution-BatchNorm-ReLu模块被广泛应用,生成器和判别器的协同工作确保了图像的转换质量。U-Net的Encoder-Decoder结构,通过跳过连接连接对应层,弥补了L1和L2损失可能带来的边缘模糊。Pix2pix引入的patchGAN结构,增强了局部真实性的判断,提高了训练的效率和精度。 在实际操作中,Pix2pix的实现源码可以在pytorch-CycleGAN-and-pix2pix项目中找到。train.py和test.py脚本根据用户选择的选项动态创建模型,如pix2pix_model.py(基础GAN结构)和colorization_model.py(黑白转彩色)。models文件夹则包含了各种基础模型、网络结构以及训练和测试设置的选项。 重点在于Pix2Pix模型的广泛应用,它是一对一的映射,特别适合图像重建任务,但对数据集的多样性要求较高。论文要点包括cGAN的条件设定、U-Net的高效结构、skip-connection的连接策略以及D网络输入的对齐方式等,这些都是提升生成效果的关键。 在Mo平台上,你可以体验到如建筑草图转照片的Pix2PixGAN实验,实时感受图像翻译的魅力。同时,如果在使用过程中遇到问题或发现有价值的信息,欢迎随时与我们联系。 总的来说,Pix2pix以其强大的架构和创新的损失函数,引领着图像翻译技术的发展。无论是学术研究还是实际应用,都有丰富的资源可供参考,包括论文1、官方文档2,以及开源代码3等。 Mo人工智能俱乐部,作为支持Python的在线建模平台,致力于降低AI开发门槛,提供丰富的学习资源和实践环境,欢迎加入我们,共同探索人工智能的无限可能。BERT源码逐行解析
解析BERT源码,关键在于理解Tensor的形状,这些我在注释中都做了标注,以来自huggingface的PyTorch版本为例。首先,BertConfig中的参数,如bert-base-uncased,包含了word_embedding、position_embedding和token_type_embedding三部分,它们合成为BertEmbedding,形状为[batch_size, seq_len, hidden_size],如( x x )。
Bert的基石是Multi-head-self-attention,这部分是理解BERT的核心。代码中对相对距离编码有详细注释,通过计算左右端点位置,形成一个[seq_len, seq_len]的相对位置矩阵。接着是BertSelfOutput,执行add和norm操作。
BertAttention则将Self-Attention和Self-Output结合起来。BertIntermediate部分,对应BERT模型中的一个FFN(前馈神经网络)部分,而BertOutput则相当直接。最后,BertLayer就是将这些组件组装成一个完整的层,BERT模型就是由多个这样的层叠加而成的。
深入理解Pytorch的BatchNorm操作(含部分源码)
Pytorch中的BatchNorm操作在训练和测试模式下有所不同,特别是在涉及dropout时。Batch Normalization(BN)是深度学习中的重要技术,通过在神经网络中间层对输入数据进行标准化处理,解决协方差偏移问题。其核心公式包含对每个通道数据的均值和方差计算,规范化操作后进行仿射变换以保持模型性能。
在BN中,需要关注的参数主要包括学习参数gamma和beta,以及动态统计的running_mean和running_var。在Pytorch的实现中,如nn.BatchNorm2d API,关键参数包括trainning(模型是否在训练模式)、affine(是否启用仿射变换)、track_running_stats(是否跟踪动态统计)和momentum(动态统计更新的权重)。
训练状态会影响BN层的计算,当模型处于训练状态(trainning=True)时,running_mean和running_var会在每次前向传播(forward())中更新,而转为测试模式(mode.eval())则会冻结这些统计值。源码中的_NormBase类和_BatchNorm类定义了这些操作的细节,包括动态统计的管理。
对于自定义BN,可以重载前向传播函数,改变规范化操作的细节。总的来说,理解Pytorch的BatchNorm操作,需关注其在训练和测试模式中的行为,以及与模型训练状态相关的关键参数。
Pytorch深入剖析 | 1-torch.nn.Module方法及源码
torch.nn.Module是神经网络模型的基础类,大部分自定义子模型(如卷积、池化或整个网络)均是其子类。torch.nn.Parameter是继承自torch.tensor的子类,用以表示可训练参数。定义Module时,可以使用个内置方法,例如add_module用于添加子模块,children和named_children用于获取子模块,modules和named_modules用于获取所有模块,register_parameter用于注册参数,parameters和named_parameters用于获取参数,get_parameter用于获取指定参数等。Module还支持数据格式转换,如float、double、half和bfloat,以及模型的设备移动,如cpu、cuda和xpu。训练模式调整可以通过train和eval方法实现。模型参数的梯度可以使用zero_grad方法清零。
模型的前向传播由forward方法定义,而apply方法允许应用特定函数到模型的所有操作符上。模型状态可以通过state_dict和load_state_dict方法进行保存和加载,常用于保存模型参数。此外,模型可以设置为训练模式或评估模式,影响特定模块如Dropout和BatchNorm的行为。
在PyTorch中,hook方法用于在前向和反向传播过程中捕获中间变量。注册hook时,可以使用torch.Tensor.register_hook针对张量注册后向传播函数,torch.nn.Module.register_forward_hook针对前向传播函数,torch.nn.Module.register_forward_pre_hook用于在前向传播之前修改输入张量,以及torch.nn.Module.register_backward_hook用于捕获中间层的梯度输入和输出。
通过这些方法,开发者可以灵活地调整、监控和优化神经网络模型的行为,从而实现更高效、更精确的模型训练和应用。利用hook方法,用户可以访问中间变量、修改输入或输出,以及提取特征图的梯度,为模型的定制化和深入分析提供了强大的工具。
PyTorch 源码分析(三):torch.nn.Norm类算子
PyTorch源码详解(三):torch.nn.Norm类算子深入解析
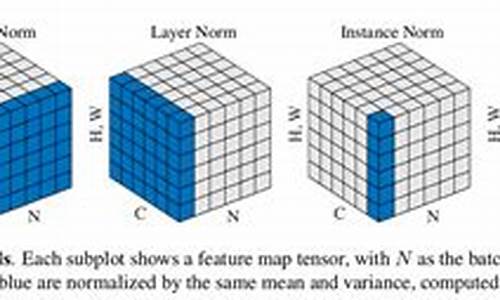
Norm类算子在PyTorch中扮演着关键角色,它们包括BN(BatchNorm)、LayerNorm和InstanceNorm。1. BN/LayerNorm/InstanceNorm详解
BatchNorm(BN)的核心功能是对每个通道(C通道)的数据进行标准化,确保数据在每个批次后保持一致的尺度。它通过学习得到的gamma和beta参数进行缩放和平移,保持输入和输出形状一致,同时让数据分布更加稳定。 gamma和beta作为动态调整权重的参数,它们在BN的学习过程中起到至关重要的作用。2. Norm算子源码分析
继承关系:Norm类在PyTorch中具有清晰的继承结构,子类如BatchNorm和InstanceNorm分别继承了其特有的功能。
BN与InstanceNorm实现:在Python代码中,BatchNorm和InstanceNorm的实例化和计算逻辑都包含对输入数据的2D转换,即将其分割为M*N的矩阵。
计算过程:在计算过程中,首先计算每个通道的均值和方差,这是这些标准化方法的基础步骤。
C++侧的源码洞察
C++实现中,对于BatchNorm和LayerNorm,代码着重于处理数据的标准化操作,同时确保线程安全,通过高效的数据视图和线程视图处理来提高性能。

2024-12-01 00:13
2024-11-30 23:53
2024-11-30 22:17
2024-11-30 22:14
2024-11-30 21:50
