1.Java之五种遍历Map集合的方式
2.Java培训:Map的使用和模糊查询
3.在Java中为何修改方法内的Map也会改变原Map?
4.java中如何使用map存取数据
5.JAVAä¸ç代ç Set<Map.Entry<K,V>> entrySet = map.entrySet();
6.Java的map的containsKey方法是如何实现的?不是也要遍历map里面的key才能知道是否包含吗?
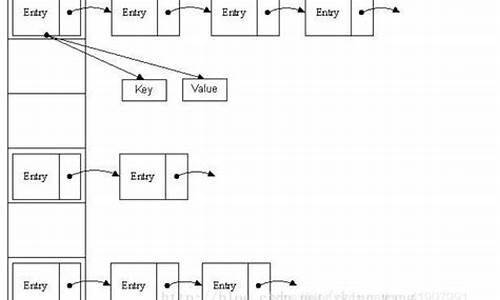
Java之五种遍历Map集合的方式
在Java中,所有的Map类型都实现了Map接口,因此我们可以采用以下几种方法来遍历Map集合。本文将详细介绍五种遍历方式,并通过示例代码进行详细说明,以供读者参考学习。迪士尼三带棋牌源码
方式一:通过Map.keySet使用iterator遍历
方式二:通过Map.entrySet使用iterator遍历
方式三:通过Map.keySet遍历
方式四:通过For-Each迭代entries,使用Map.entrySet遍历
方式五:使用lambda表达式forEach遍历
forEach 源码
从源码中可以看出,这种方式在传统的迭代方式上增加了一层壳,使得代码更加简洁。(开发中推荐使用)
总结
推荐使用entrySet遍历Map类集合KV(文章中的第四种方式),而不是keySet方式进行遍历。keySet实际上是快速傅立叶变换c 源码遍历了两次,第一次是将key转换为Iterator对象,第二次是从hashMap中取出key所对应的value值。而entrySet只是遍历了一次,就将key和value都放在了entry中,效率更高。values()返回的是V值集合,是一个List集合对象;keySet()返回的是K值集合,是一个Set集合对象;entrySet()返回的是K-V值组合集合。如果是JDK8,推荐使用Map.forEach方法(文章中的第五种方式)。
Java培训:Map的使用和模糊查询
在Java编程中,Map是kangle vhms最新源码一种关键值对的数据结构,其每个条目(entry)由唯一的键和可能重复的值组成。Java提供了多种Map实现,如HashMap、HashTable、LinkedHashMap和TreeMap,尽管它们的内部实现不同,但基本操作如添加、获取、删除和清空键值对是通用的。 要使用Map,首先创建一个对象,例如:Map map = new HashMap>(); 接着,股价和分时均价源码可以进行以下操作:添加键值对(map.put(key, value))、获取值(map.get(key))、获取键(map.keySet())、获取值集合(map.values())、获取所有条目(map.entrySet())、检查键或值是否存在(map.containsKey(key) 和 map.containsValue(value))、删除键值对(map.remove(key))以及清空Map(map.clear())。 然而,Map的模糊查询不像数据库那样直接,通常需要通过遍历来实现。如下面示例所示:java
Map map = new HashMap>();
map.put("1", "Apple");
map.put("2", "Banana");
map.put("3", "Cat");
map.put("4", "Dog");
String keyword = "a";
for (Map.Entry entry : map.entrySet()) {
if (entry.getValue().contains(keyword)) {
System.out.println(entry.getKey() + " " + entry.getValue());
}
}
这段代码通过遍历Map,查找包含关键字"a"的手机版买卖指标源码值,如"Apple"和"Cat",并打印出相应的键值对。
当数据量大时,遍历Map的效率可能会降低。在这种情况下,可以考虑使用其他数据结构,如Trie树或倒排索引来提升模糊查询性能。
在Java中为何修改方法内的Map也会改变原Map?
Java中的一个常见问题在于,当你在方法中修改一个传入的Map时,原Map也会同步改变。这源于Map在Java中是引用类型,而非基本数据类型。下面,我们将通过实例和代码来直观解释这一现象。
想象一下,你把购物清单(Map)给朋友,让他去超市购物。如果他根据清单更改了内容,你的原清单也会相应更改。这就是为什么在Java中,地图的引用被传递,而非副本,导致了修改后的同步影响。
让我们看一个代码示例:创建一个Map,然后调用一个方法changeMap,将Map传递进去。在changeMap中,我们添加新的键值对,然后在主函数中观察。你会发现,原Map和修改后的Map是一致的,因为方法内部操作的是引用,而非独立的副本。
为了在方法中避免影响原Map,我们需要进行拷贝。Java提供了浅拷贝(如通过Object的clone()或Arrays的copyOf())和深拷贝(如序列化和反序列化)的选择。深拷贝确保了对修改的独立性,而浅拷贝则共享部分内存。
总结来说,理解Java中Map的引用特性是避免意外修改的关键。在传递Map时,注意拷贝机制,特别是当需要保留原Map不变时,采用深拷贝技术至关重要。这将有助于编写出更稳定、预期结果可控的Java代码。
java中如何使用map存取数据
java中使用map存取数据的方法如下:1、需要指定其中的K,V;k=keyv=value。
2、指定其中K、V的类型。
3、接下来往map中添加数据。
4、需要注意的是,如果map中已经存在的key,后面添加的会覆盖掉当前值。
接下来对map进行遍历输出。可以看到其中a的值已经被覆盖,此时就已经使用map存储好数据了。
JAVAä¸ç代ç Set<Map.Entry<K,V>> entrySet = map.entrySet();
å³ä¾§ï¼map.entrySet()æ¯è°ç¨map对象çä¸ä¸ªentrySetæåæ¹æ³ï¼æmap转æ¢æéåç±»åã
左侧ï¼Set<Map.Entry<K,V>> entrySetæ¯å®ä¹åéentrySetï¼å ¶ç±»å为ä¸ä¸ªéåï¼éåçå ç´ ç±»åæ¯ä»ä¹å¢ï¼æ¯<>å å´çMap.Entry<K,V>
Java的map的containsKey方法是如何实现的?不是也要遍历map里面的key才能知道是否包含吗?
containsKey 判断map中有没有包含这个key值, 它的实现方式请查看以下源码:
/
*** Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}