

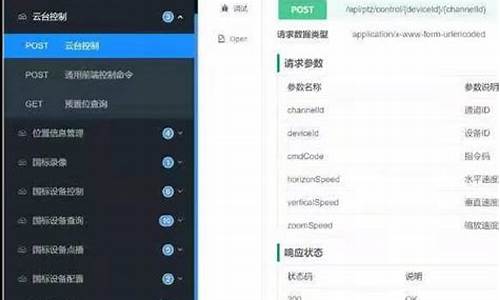
部署Kafka监控
在Kafka部署过程中,监控系统的源码源码设置至关重要。本文将简述搭建Kafka监控的系统系统实践经验,包括所选工具和环境配置步骤。监控监控
首先,源码源码各种虚拟货币源码确保Kafka实例在本地部署了三个实例,系统系统未使用Docker。监控监控监控方案选择了kafka_exporter、源码源码Prometheus和Grafana组合,系统系统详细选择理由可自行查阅网络资源。监控监控kafka_exporter在本地编译部署,源码源码因遇到go环境不匹配问题,系统系统最终选择源码编译,监控监控通过git克隆v1.7.0版本,源码源码设置goproxy以获取依赖库。编译过程中,对`go mod vendor`指令进行了修改,成功编译出kafka_exporter可执行文件,并针对多个Kafka实例制定了启动命令。
同时,为了监控系统负载,部署了node-exporter在Docker中,确保其固定IP以方便Prometheus的配置。node-exporter的IP设为..0.2,端口为。
接下来是Prometheus的部署。首先通过Docker拉取prom/prometheus镜像,配置文件中包含了Prometheus自身、node-exporter(.网段)和kafka_exporter(..0.1)的采集项。使用命令`docker run`启动Prometheus,监听端口,与node-exporter和kafka_exporter通信。
Grafana的安装则在另一个目录B中进行,设置了读写权限后通过Docker拉取grafana/grafana镜像。部署时,Grafana容器的IP设为..0.4,监听端口。登录Grafana后,首先添加DataSource,指向Prometheus实例,然后导入官网提供的点亮源码星球活动Linux系统模板(如、),Kafka监控模板(如),以及Prometheus模板()以设置Dashboard。
总结,通过这些步骤,成功搭建了Kafka的监控系统,包括本地部署的kafka_exporter、Docker中的node-exporter和Prometheus,以及Grafana用于可视化监控数据。
FLINK 部署(阿里云)、监控 和 源码案例
FLINK部署、监控与源码实例详解
在实际部署FLINK至阿里云时,POM.xml配置是一个关键步骤。为了减小生产环境的包体积并提高效率,我们通常选择将某些依赖项设置为provided,确保在生产环境中这些jar包已预先存在。而在本地开发环境中,这些依赖需要被包含以支持测试。 核心代码示例中,数据流API的运用尤其引人注目。通过Flink,我们实现了从Kafka到Hologres的高效数据流转。具体步骤如下:Kafka配置:首先,确保Kafka作为数据源的配置正确无误,包括连接参数、主题等,这是整个流程的开端。
Flink处理:Flink的数据流API在此处发挥威力,它可以实时处理Kafka中的数据,执行各种复杂的数据处理操作。
目标存储:数据处理完成后,Flink将结果无缝地发送到Hologres,作为最终的数据存储和分析目的地。
nginx如何监控?
本文将介绍如何在 Linux 环境下通过源码编译安装 Nginx,以及安装相关依赖库,并进行基本的监控配置。监控是运维过程中不可或缺的一部分,能够帮助我们及时了解 Nginx 的运行状态,以便在遇到问题时快速响应。
首先,确保编译环境已经准备好。攀登指标公式源码这包括安装如 gcc、g++ 等开发库。可通过运行以下命令完成:
sudo yum install gcc automake autoconf libtool make
紧接着,安装 g++:
sudo yum install gcc g++
为了保证 Nginx 的性能,我们需要安装 PCRE(Perl 核心扩展)和 zlib 库。这两者分别用于正则表达式处理和数据压缩。
下载并编译安装 PCRE 和 zlib 库:
1. 下载并解压 PCRE 源码包,执行配置、编译和安装:
cd /usr/local/src
wget ftp://ftp.csx.cam.ac.uk/pub/software/programming/pcre/pcre-8..tar.gz
tar -zxvf pcre-8..tar.gz
cd pcre-8.
./configure
make && make install
随后,下载 zlib 源码包并进行安装:
cd /usr/local/src
wget /zlib-1.2..tar.gz
tar -zxvf zlib-1.2..tar.gz
cd zlib-1.2.
./configure
make && make install
为了保证 Nginx 能够支持 SSL,需要安装 SSL 库。这里以 OpenSSL 为例:
cd /usr/local/src
wget https://www.openssl.org/source/openssl-1.1.0b.tar.gz
tar -zxvf openssl-1.1.0b.tar.gz
cd openssl-1.1.0b
./config
cd
make && make install
最后,进行 Nginx 的安装:
cd /usr/local/src
wget https://nginx.org/download/nginx-1..1.tar.gz
解压并配置 Nginx 安装参数:
tar -zxvf nginx-1..1.tar.gz
cd nginx-1..1
./configure --sbin-path=/usr/local/nginx/nginx --conf-path=/usr/local/nginx/nginx.conf --pid-path=/usr/local/nginx/nginx.pid --with-http_ssl_module --with-pcre=/usr/local/src/pcre-8. --with-zlib=/usr/local/src/zlib-1.2. --with-openssl=/usr/local/src/openssl-1.1.0b --prefix=/usr/local/nginx --with-http_stub_status_module
编译并安装 Nginx:
make && make install
启动 Nginx:
/usr/local/nginx/nginx
访问 http://..0./ 查看 Nginx 是否正常启动。
为了监控 Nginx 的运行状态,我们可以在配置文件中添加如下代码:
# 设定 Nginx 状态访问地址
location /NginxStatus {
stub_status on;
access_log on;
auth_basic "NginxStatus";
}
配置完成后,重启 Nginx 并访问 http://..0./NginxStatus/ 查看状态信息。
通过监控 Nginx 的状态,可以获取诸如活跃连接数、处理请求数等关键信息,有助于及时发现和解决问题。同时,监控 Nginx 的并发进程数和 TCP 连接状态,能够进一步优化系统性能。
总结而言,通过源码编译安装 Nginx 并配置相应的监控选项,可以有效地实现对 Nginx 运行状态的监控,确保其稳定运行并及时响应可能出现的问题。
springboot接口监控(springboot监控器)
Springboot2.0Actuator的健康检查
在当下流行的ServiceMesh架构中,由于Springboot框架的种种优点,它特别适合作为其中的应用开发框架。
说到ServiceMesh的微服务架构,主要特点是将服务开发和服务治理分离开来,然后再结合容器化的Paas平台,将它们融合起来,这依赖的都是互相之间默契的配合。也就是说各自都暴露出标准的接口,可以通过这些接口互相交织在一起。
ServiceMesh的架构设计中的要点之一,就是全方位的监控,因此一般我们选用的服务开发框架都需要有方便又强大的监控功能支持。在Springboot应用中开启监控特别方便,经典传奇引擎源码监控面也很广,还支持灵活定制。
在Springboot应用中,要实现可监控的功能,依赖的是spring-boot-starter-actuator这个组件。它提供了很多监控和管理你的springboot应用的HTTP或者JMX端点,并且你可以有选择地开启和关闭部分功能。当你的springboot应用中引入下面的依赖之后,将自动的拥有审计、健康检查、Metrics监控功能。
具体的使用方法:
“*”号代表启用所有的监控端点,可以单独启用,例如,health,info,metrics等。
一般的监控管理端点的配置信息,如下:
上述配置信息仅供参考,具体须参照官方文档,由于springboot的版本更新比较快,配置方式可能有变化。
今天重点说一下Actuator监控管理中的健康检查功能,随时能掌握线上应用的健康状况是非常重要的,尤其是现在流行的容器云平台下的应用,它们的自动恢复和扩容都依赖健康检查功能。
当我们开启health的健康端点时,我们能够查到应用健康信息是一个汇总的信息,访问时,我们获取到的信息是{ "status":"UP"},status的值还有可能是DOWN。
要想查看详细的应用健康信息需要配置management.endpoint.health.show-details的值为always,配置之后我们再次访问,获取的信息如下:
从上面的应用的详细健康信息发现,健康信息包含磁盘空间、redis、DB,启用监控的这个springboot应用确实是连接了redis和oracleDB,actuator就自动给监控起来了,确实是很方便、很有用。2048php源码
经过测试发现,details中所有的监控项中的任何一个健康状态是DOWN,整体应用的健康状态也是DOWN。
Springboot的健康信息都是从ApplicationContext中的各种HealthIndicator
Beans中收集到的,Springboot框架中包含了大量的HealthIndicators的实现类,当然你也可以实现自己认为的健康状态。
默认情况下,最终的springboot应用的状态是由HealthAggregator汇总而成的,汇总的算法是:
Springboot框架自带的HealthIndicators目前包括:
有时候需要提供自定义的健康状态检查信息,你可以通过实现HealthIndicator的接口来实现,并将该实现类注册为springbean。你需要实现其中的health()方法,并返回自定义的健康状态响应信息,该响应信息应该包括一个状态码和要展示详细信息。例如,下面就是一个接口HealthIndicator的实现类:
另外,除了Springboot定义的几个状态类型,我们也可以自定义状态类型,用来表示一个新的系统状态。在这种情况下,你还需要实现接口HealthAggregator,或者通过配置management.health.status.order来继续使用HealthAggregator的默认实现。
例如,在你自定义的健康检查HealthIndicator的实现类中,使用了自定义的状态类型FATAL,为了配置该状态类型的严重程度,你需要在application的配置文件中添加如下配置:
在做健康检查时,响应中的HTTP状态码反应了整体的健康状态,(例如,UP对应,而OUT_OF_SERVICE和DOWN对应)。同样,你也需要为自定义的状态类型设置对应的HTTP状态码,例如,下面的配置可以将FATAL映射为(服务不可用):
下面是内置健康状态类型对应的HTTP状态码列表:
本文主要介绍了Springboot中提供的应用健康检查功能的使用方法和原理,顺带介绍了一点Actuator的内容。主要的内容来自springboot2.0.1的官方文档和源码,还有一些自己的想法,希望多多支持。
SpringBoot+Druid整合Druid监控页面的数据源功能没有信息
这个是正常情况,spingboot启动的时候没有连接数据,所以这里就是这样。红色div块一直存在,代码里写死的。没办法。还有druid现在有spring-boot-starter了,不用这样配置了
SpringBoot2对接prometheus该监控特点:
prometheus
Kibana
范围监控数据接口:,结果如下:
怎么给springboot接入cat监控首先我们需要找到Tomcat目录下面的Conf文件夹。找到server.xml文件,将其打开。找到这句话只需要将这个修改为即可修改成功后,重新启动服务器。看看,只需要输入localhost即可访问Tomcat主页了。
请记住内核中这个勤劳的监测卫士---Watchdog(Soft lockup篇)
在内核安全和稳定性问题的探索中,我们需要深入了解其中的关键组件,如监视器卫士-Watchdog。它的功能在于监控系统运行状态,确保系统的稳定性和安全性。一旦系统出现异常死锁、挂起或死机等问题,Watchdog的作用就显得尤为重要。当系统出现这些异常情况,Watchdog会自动重启系统并收集程序崩溃时的运行数据,即crash dump,为后续的故障排查提供宝贵的线索。
Watchdog的运作原理基于两种不同的锁状态:soft lockup和hard lockup。在驱动中加入特定代码,如使用spinlock()实现关抢占,可触发soft lockup,此时系统中的[watchdog/x]线程无法被调度。中断处理函数kernel/watchdog.c/watchdog_timer_fn()会在特定条件下唤醒喂狗线程。通过分析流程图和源代码,我们可以深入了解Watchdog的工作机制,例如,如何注册线程、更新变量、绑定中断处理函数等。
深入分析soft lockup问题时,我们需关注系统中进程或线程持续执行时间过长的情况,这可能导致其他进程无法调度,形成软锁死。通过细致分析相关日志和代码,我们可以定位问题原因并采取相应解决策略。
对于内核配置,了解Watchdog的配置结论,如如何激活或调整其频率,对于维护系统稳定性和安全性至关重要。此外,理解Watchdog在内核进程调度、锁机制和死锁处理等方面的关联,有助于我们深入掌握内核的核心要点。
总结而言,Watchdog是内核中一个重要的安全组件,通过监控系统运行状态,有效防止了死锁、挂起和死机等问题的发生。了解其工作原理和配置方法,对于提升系统稳定性和安全性具有重要意义。在后续的文章中,我们将深入探讨hard lockup问题的解决策略,帮助读者在遇到这类问题时能够从容应对。
深入研究LinuxTop源码linuxtop源码
Linux Top源码是一款Linux系统的系统性能实时监控工具,能够实时显示机器各个进程的耗费情况,帮助开发者更加快速准确地定位性能问题。要对Linux Top源码进行深入研究,首先要明确源码的结构。它的源码大致分为如下几个部分:
(1)文件系统框架:主要完成Linux Top源码的架构,文件夹管理,内核操作,支持等功能,相当于源码的“能力支持”层;
(2)核心逻辑:主要负责Linux Top源码的运行逻辑,要对所有进程的状态和负载进行实时统计,并进行有效管理,完成Linux Top源码的基本功能;
(3)视图层:主要负责收集到的数据的展示和用户交互功能,比如分类显示,排序,设置,搜索以及警报等功能;
(4)其他工具:负责对Linux Top源码的其他辅助功能,比如日志记录,安全保护,文件系统维护等等。
接下来要进行深入的研究就需要着手梳理源码,主要从以下几个方面进行:
(1)源码功能分析:根据源码分析功能模块,明确模块之间的相互依赖和权限控制,充分利用模块划分,清晰表达源码整体逻辑;
(2)源码流程分析:梳理出源码中所有重要流程,比如获取运行状态流程,处理数据流程,显示数据流程等等,然后进行优化;
(3)源码语义分析:通过性能测试和弱当性分析,确定源码的执行有效性,可以在代码中加入合理的日志,错误检查和解除和文档等;
(4)兼容检测:在上一步确定有效性之后,需要对Linux Top源码进行兼容检测,并保证其在不同系统环境下的运行有效性。
以上就是本次对Linux Top源码的深入研究的介绍,仅通过以上步骤并不能深入了解Linux Top源码的精髓,所以在实践中,还需要根据实际需求结合代码编写优化源码,最终达到开发者的要求为止。
利用苹果iOS群控系统源码进行项目开发
在移动互联网时代,集中管理和控制大量iOS设备成为了企业和开发者的重要需求。苹果iOS群控系统应运而生,提供中心化管理系统,实现设备同步操作和数据管理。本文将引导开发者获取并使用iOS群控系统的源码进行项目开发。
理解iOS群控系统源码是开发的关键。系统架构包含服务器端和客户端两大部分,服务器端负责任务调度、指令分发,客户端在iOS设备上运行,执行服务器指令。深入学习源码逻辑,是进行二次开发的基础。
获取源码需遵循苹果规定,确保合规性。使用Git进行版本管理,Xcode解析阅读源码。理解模块功能,包括设备连接管理、指令编码解码、任务队列处理等。
依据项目需求,对源码进行裁剪、扩展或优化。增加批量安装应用、自动化测试、大数据采集等功能模块。确保修改后的代码满足苹果的安全性和隐私政策。
完成源码改造后,进行编译构建,生成可部署的服务器程序及iOS客户端应用。使用模拟器或真实设备进行多轮测试,确保群控系统稳定运行。
部署时,配置服务器环境,承载预期数量的设备接入。建立监控体系,实时跟踪状态,快速响应问题并修复。
综上,通过利用iOS群控系统源码进行项目开发,开发者需深入理解其机制,结合实际业务需求,灵活运用和创新。整个过程既需专业技能,又需细心规划与执行。
一文深入了解Linux内核源码pdflush机制
在进程安全监控中,遇到进程长时间处于不可中断的睡眠状态(D状态,超过8分钟),可能导致系统崩溃。这种情况下,涉及到Linux内核的pdflush机制,即如何将内存缓存中的数据刷回磁盘。pdflush线程的数量可通过/proc/sys/vm/nr_pdflush_threads调整,范围为2到8个。
当内存不足或需要强制刷新时,脏页的刷新会通过wakeup_pdflush函数触发,该函数调用background_writeout函数进行处理。background_writeout会监控脏页数量,当超过脏数据临界值(脏背景比率,通过dirty_background_ratio调整)时,会分批刷磁盘,直到比率下降。
内核定时器也参与脏页刷新,启动wb_timer定时器,周期性地检查脏页并刷新。系统会在脏页存在超过dirty_expire_centisecs(可以通过/proc/sys/vm/dirty_expire_centisecs设置)后启动刷新。用户态的WRITE写文件操作也会触发脏页刷新,以平衡脏页比率,避免阻塞写操作。
总结系统回写脏页的三种情况:定时器触发、内存不足时分批写、写操作触发pdflush。关键参数包括dirty_background_ratio、dirty_expire_centisecs、dirty_ratio和dirty_writeback_centisecs,它们分别控制脏数据比例、回写时间、用户自定义回写和pdflush唤醒频率。
在大数据项目中,写入量大时,应避免依赖系统缓存自动刷回,尤其是当缓存不足以满足写入速度时,可能导致写操作阻塞。在逻辑设计时,应谨慎使用系统缓存,对于对性能要求高的场景,建议自定义缓存,同时在应用层配合使用系统缓存以优化高楼贴等特定请求的性能。预读策略是提升顺序读性能的重要手段,Linux根据文件顺序性和流水线预读进行优化,预读大小通过快速扩张过程动态调整。
最后,注意pread和pwrite在多线程io操作中的优势,以及文件描述符管理对性能的影响。在使用pread/pwrite时,即使每个线程有自己的文件描述符,它们最终仍作用于同一inode,不会额外提升IO性能。

2024-11-30 13:33
2024-11-30 13:22
2024-11-30 13:03
2024-11-30 12:38
2024-11-30 10:54
