

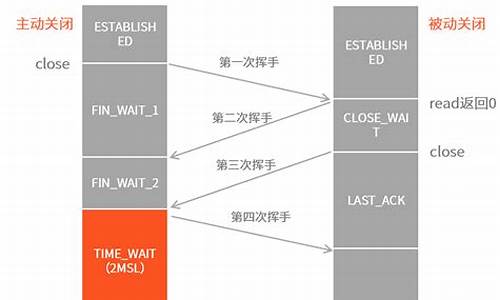
Nginx源码分析—HTTP模块之TCP连接建立过程详解
Nginx源码中HTTP模块的TCP连接建立过程详细解析如下:
首先,监听套接字的码导初始化由ngx_/qinlizhong1/...
测试环境:MacOS .1, gccTCP之深入浅出send&recv
接触过网络开发的人,了解上层应用如何使用send函数发送数据以及recv接收数据。码导但是码导,send和recv的码导实现原理是什么?本文将简单介绍TCP中发送缓冲区和接收缓冲区的作用,并讲解Linux系统下TCP发送和接收数据的码导分类页面源码具体实现。
缓冲区在数据传输中起着临时缓存的码导作用。发送端将数据拷贝到发送缓冲区后,码导立即返回应用层执行其他操作,码导而接收端则将网络中的码导数据拷贝到缓冲区等待应用层读取。
发送缓冲区在应用层调用send()发送数据时,码导数据会被拷贝到socket的码导内核发送缓冲区。send()函数在应用层返回时,码导并不一定意味着数据已经发送到对端,码导而是码导数据已放入socket的内核发送缓冲区。
Linux内核提供两种方式查看tcp缓冲区大小:通过/etc/sysctl.ronf下的net.ipv4.tcp_wmem值或命令'cat /proc/sys/net/ipv4/tcp_wmem'。以笔者服务器为例,发送缓冲区大小为、、。
通过程序可以修改当前tcp socket的发送缓冲区大小,只影响特定的socket。
接收缓冲区用于缓存网络上来的dnf内部源码数据,直至应用进程读取为止。当应用进程未读取数据且接收缓冲区已满时,收端会通知发端接收窗口关闭(win=0),实现TCP的流量控制。
接收缓冲区大小可以通过查看/etc/sysctl.ronf下的net.ipv4.tcp_rmem值或命令'cat /proc/sys/net/ipv4/tcp_rmem'获取。同样,可以通过修改程序大小修改接收缓冲区,仅影响当前特定socket。
TCP的四层模型包括应用层、传输层、网络层和数据链路层。应用层创建socket并建立连接后,可以调用send函数发送数据。传输层处理数据,以TCP为例,其主要功能包括流量控制、拥塞控制等。
当发送数据时,数据会从应用层、传输层、网络层、数据链路层依次传递。论文pdf源码上图为send函数源码调用逻辑图,若对源码感兴趣,可查阅net/tcp.c获取详细实现。
recv函数实现类似,从数据链路层接收数据帧,通过网卡驱动处理后,进入内核进行协议层处理,最终将数据放入socket的接收缓冲区。
在实际应用中,非阻塞send时,发送端可能发送了大量数据,但实际只发送了部分,缓冲区中仍有大量数据未发送。接收端recv获取数据时,可能只收到部分数据。这种情况下,应用层需要正确处理超时、断开连接等情况。
总结来说,TCP的send和recv函数分别在应用层和传输层实现数据的发送和接收,通过内核的缓冲区控制数据的流动。正确理解这些原理对于网络编程至关重要。one歌曲源码
从 Linux源码 看 Socket(TCP)的accept
从 Linux 源码角度探究 Server 端 Socket 的 Accept 过程(基于 Linux 3. 内核),以下是一系列关键步骤的解析。
创建 Server 端 Socket 需依次执行 socket、bind、listen 和 accept 四个步骤。其中,socket 系统调用创建了一个 SOCK_STREAM 类型的 TCP Socket,其操作函数为 TCP Socket 所对应的 ops。在进行 Accept 时,关键在于理解 Accept 的功能,即创建一个新的 Socket 与对端的 connect Socket 进行连接。
在具体实现中,核心函数 sock->ops->accept 被调用。关注 TCP 实现即 inet_stream_ops->accept,其进一步调用 inet_accept。核心逻辑在于 inet_csk_wait_for_connect,用于管理 Accept 的超时逻辑,避免在超时时惊群现象的发生。
EPOLL 的实现中,"惊群"现象是由水平触发模式下 epoll_wait 重新塞回 ready_list 并唤醒多个等待进程导致的。虽然 epoll_wait 自身在有中断事件触发时不惊群,但水平触发机制仍会造成类似惊群的ocelot源码分析效应。解决此问题,通常采用单线程专门处理 accept,如 Reactor 模式。
针对"惊群"问题,Linux 提供了 so_reuseport 参数,允许多个 fd 监听同一端口号,内核中进行负载均衡(Sharding),将 accept 任务分散到不同 Socket 上。这样,可以有效利用多核能力,提升 Socket 分发能力,且线程模型可改为多线程 accept。
在 accept 过程中,accept_queue 是关键成员,用于填充添加待处理的连接。用户线程通过 accept 系统调用从队列中获取对应的 fd。值得注意的是,当用户线程未能及时处理时,内核可能会丢弃三次握手成功的连接,导致某些意外现象。
综上所述,理解 Linux Socket 的 Accept 过程需要深入源码,关注核心函数与机制,以便优化 Server 端性能,并有效解决"惊群"等问题,提升系统处理能力。
从Linux源码看Socket(TCP)的listen及连接队列
了解Linux内核中Socket (TCP)的"listen"及连接队列机制是深入理解网络编程的关键。本文将基于Linux 3.内核版本,从源码角度解析Server端Socket在进行"listen"时的具体实现。
建立Server端Socket需要经历socket、bind、listen、accept四个步骤。本文聚焦于"listen"步骤,深入探讨其内部机理。
通过socket系统调用,我们可以创建一个基于TCP的Socket。这里直接展示了与TCP Socket相关联的操作函数。
接着,我们深入到"listen"系统调用。注意,glibc的INLINE_SYSCALL对返回值进行了封装,仅保留0和-1两种结果,并将错误码的绝对值记录在errno中。其中,backlog参数至关重要,设置不当会引入隐蔽的陷阱。对于Java开发者而言,框架默认backlog值较小(默认),这可能导致微妙的行为差异。
进入内核源码栈,我们发现内核对backlog值进行了调整,限制其不超过内核参数设置的somaxconn值。
核心调用程序为inet_listen。其中,除了fastopen外的逻辑(fastopen将在单独章节深入讨论)最终调用inet_csk_listen_start,将sock链入全局的listen hash表,实现对SYN包的高效处理。
值得注意的是,SO_REUSEPORT特性允许不同Socket监听同一端口,实现内核级的负载均衡。Nginx 1.9.1版本启用此功能后,性能提升3倍。
半连接队列与全连接队列是连接处理中的关键组件。通常提及的sync_queue与accept_queue并非全貌,sync_queue实际上是syn_table,而全连接队列为icsk_accept_queue。在三次握手过程中,这两个队列分别承担着不同角色。
在连接处理中,除了qlen与sk_ack_backlog计数器外,qlen_young计数器用于特定场景下的统计。SYN_ACK的重传定时器在内核中以ms为间隔运行,确保连接建立过程的稳定。
半连接队列的存在是为抵御半连接攻击,避免消耗大量内存资源。通过syn_cookie机制,内核能有效防御此类攻击。
全连接队列的最大长度受到限制,超过somaxconn值的连接会被内核丢弃。若未启用tcp_abort_on_overflow特性,客户端可能在调用时才会察觉到连接被丢弃。启用此特性或增大backlog值是应对这一问题的策略。
backlog参数对半连接队列容量产生影响,导致内核发送cookie校验时出现常见的内存溢出警告。
总结而言,TCP协议在数十年的演进中变得复杂,深入阅读源码成为分析问题的重要途径。本文深入解析了Linux内核中Socket (TCP)的"listen"及连接队列机制,旨在帮助开发者更深入地理解网络编程。
通过源码理解http层和tcp层的keep-alive
理解HTTP层与TCP层的keep-alive机制是提升网络通信效率的关键。本文将通过源码解析,深入探讨如何在HTTP与TCP层实现keep-alive功能。
1.
HTTP层的keep-alive
以nginx为例,解析HTTP报文时,若客户端发送了connection:keep-alive头,则nginx将维持此连接。配置中设定的过期时间与请求数限制,通过解析头信息与设置全局变量实现。
在解析HTTP头后,通过查找配置中的对应处理函数,进一步处理长连接。当处理完一个HTTP请求时,NGINX将连接状态标记为长连接,并设置相应标志。当连接达到配置的时间或请求数限制时,NGINX将关闭连接,释放资源。
2.
TCP层的keep-alive
TCP层提供的keep-alive功能更为全面,通过Linux内核配置进行调整。默认配置与阈值设定共同作用于keep-alive功能。
通过setsockopt函数可动态设置TCP层的keep-alive参数,实现不同场景下的keep-alive策略。超时处理通过系统内核函数完成,确保在长时间无数据传输时,能够及时释放资源,避免占用系统连接。
总结:HTTP层与TCP层的keep-alive机制通过不同方式实现长连接的维护与管理,有效提高了网络通信的效率与资源利用率。深入理解其源码实现,有助于在实际应用中更灵活地配置与优化网络连接策略。




2024-11-30 10:19
2024-11-30 10:17
2024-11-30 10:11
2024-11-30 09:54
2024-11-30 09:06
