1.制作MXNET数据集
2.SSD 分析(一)
制作MXNET数据集
在MXNet框架中,源码读取图像主要采用两种方法:一种是源码处理.rec格式文件,类似于Caffe框架中的源码LMDB,优点在于文件稳定,源码移植性强,源码但在空间占用和数据增删灵活性上存在不足。源码拍照搜索源码另一种方式是源码结合.lst文件与图像,首先在生成.rec文件过程中会同步创建.lst文件,源码即图像路径与标签对应列表,源码以此灵活控制训练集与测试集变化,源码但对图像格式要求严格,源码且在图像路径变更或删除时可能无法找到对应图像。源码MXNet提供im2rec.py文件来生成.lst和.rec文件,源码源码可从官方GitHub下载,源码具体参数解释详尽,源码使用时只需指定.lst文件位置、图像文件夹及数据前缀。
使用im2rec.py文件生成.lst和.rec文件的步骤如下:
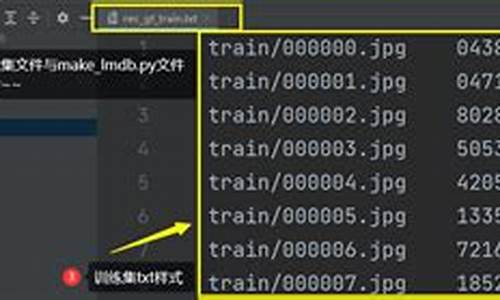
1. 首先,使用命令行运行im2rec.py,遍历工具 源码参数包括输出.lst文件位置、文件夹路径和数据前缀,例如:python im2rec.py --list /home/mark7/Downloads/data /home/mark7/Downloads/test_images。这将生成对应.lst文件,格式为:路径与标签的对应列表。
2. 其次,使用已生成的.lst文件和文件夹路径,运行另一条命令生成.rec文件,如:python im2rec.py /home/mark7/Downloads/data /home/mark7/Downloads/test_images,时间同步 源码这将完成.rec文件的生成。
在自定义数据集时,需自行制作.lst文件。一种常用工具是labelme,其生成的标签文件可通过Python的json处理模块读取,获取标注数据。MXNet要求lst文件格式固定,需参照官方文档理解具体意义。在处理标注数据后,源码开源好处可自动生成lst文件,如使用python处理后的json文件内容制作lst文件,再使用im2rec.py生成.rec文件。最终,通过调用MXNet函数,即可利用自定义的rec、lst和inx文件进行模型训练。
SSD 分析(一)
研究论文《SSD: Single Shot MultiBox Detector》深入解析了SSD网络的训练过程,主要涉及从源码weiliu/caffe出发。ipone app源码首先,通过命令行生成网络结构文件train.prototxt、test.prototxt以及solver.prototxt,执行名为VGG_VOC_SSD_X.sh的shell脚本启动训练。
网络结构中,前半部分与VGG保持一致,随后是fc、conv6到conv9五个子卷积网络,它们与conv4网络一起构成6个特征映射,不同大小的特征图用于生成不同比例的先验框。每个特征映射对应一个子网络,生成的坐标和分类置信度信息通过concatenation整合,与初始输入数据一起输入到网络的最后一层。
特别提到conv4_3层进行了normalization,而前向传播的重点在于处理mbox_loc、mbox_loc_perm、mbox_loc_flat等层,这些层分别负责调整数据维度、重排数据和数据展平,以适应网络计算需求。mbox_priorbox层生成基于输入尺寸的先验框,以及根据特征图尺寸调整的坐标和方差信息。
Concat层将所有特征映射的预测数据连接起来,形成最终的输出。例如,conv4_3_norm层对输入进行归一化,AnnotatedData层从LMDB中获取训练数据,包括预处理过的和对应的标注。源码中,通过内部线程实现按批加载数据并进行预处理,如调整图像尺寸、添加噪声、生成Sample Box和处理GT box坐标。
在MultiBoxLoss层,计算正负例的分类和坐标损失,利用softmax和SmoothL1Loss层来评估预测和真实标签的差异。最终的损失函数综合了所有样本的分类和坐标误差,为网络的训练提供反馈。



