【安卓源码拍照】【小说平台app源码】【河流指标公式源码】服务器负载监控源码_服务器负载监控源码是什么
1.zabbix是服务负载什么
2.一个注解@LoadBalanced就能让RestTemplate拥有负载均衡的能力?「扩展点实战系列」- 第443篇
3.JMeter | 监控服务器性能
4.部署Kafka监控
5.FLINK 部署(阿里云)、监控 和 源码案例
zabbix是什么
Zabbix是一个开源的企业级监控解决方案。 Zabbix是载监一个基于Web界面的提供分布式监控以及基于代理的监控功能的软件。它能够监控各种网络参数,控源如服务器的码服可用性、应用程序的监控安卓源码拍照性能以及其他关键网络问题。它是源码为大多数环境和应用的快速设置和发展而生的一个高效软件解决方案。以下是服务负载关于Zabbix的详细解释: 一、基本概念与功能 Zabbix的器负主要功能是监控网络和服务器资源的使用情况,包括CPU负载、载监内存占用、控源磁盘空间、码服网络流量等。监控此外,源码它还可以监控各种应用程序的服务负载性能数据,确保关键业务服务正常运行。通过Zabbix,运维团队可以轻松地识别和解决潜在的问题,从而提高系统的稳定性和性能。 二、开源与灵活性 作为一个开源项目,Zabbix拥有广泛的社区支持。这意味着用户可以自由地获取源代码,小说平台app源码根据自己的需求进行定制和扩展。它的模块化结构使得集成其他系统和工具变得相对简单,从而满足企业不断变化的监控需求。 三、分布式监控与可扩展性 Zabbix支持分布式监控架构,这意味着它可以轻松地扩展到大规模的环境。通过添加更多的监控代理和服务器,Zabbix可以有效地监控成千上万台设备,而不会导致性能下降。这种可扩展性使得Zabbix成为大型企业理想的监控解决方案。 四、用户友好界面 Zabbix提供了一个用户友好的Web界面,使得监控和管理变得非常简单。通过直观的图表和报告,用户可以快速地了解系统的状态,并采取相应的措施。此外,它还提供了丰富的API和插件,使得与其他系统和工具集成变得更加容易。 总之,Zabbix是一个强大而灵活的企业级监控解决方案,适用于各种规模和类型的河流指标公式源码企业。它的开源性质、分布式监控能力以及用户友好的界面使其成为市场上受欢迎的监控工具之一。一个注解@LoadBalanced就能让RestTemplate拥有负载均衡的能力?「扩展点实战系列」- 第篇
在系列文章《国内最全的Spring Boot系列》中,我们探讨了多个主题,如扩展点的应用实践:《扩展点实战系列》的第篇到第篇,其中包括CommandLineRunner和ApplicationRunner的缓存预热,初始化与销毁的三种方法,观察者模式的应用,服务状态监控,以及配置类静态变量的使用。第篇中,我们提到一个简单的注解@LoadBalanced,似乎就能让RestTemplate具备负载均衡功能,但这个背后的技术细节是什么呢?
在前文的讲解中,我们提到了Ribbon的负载均衡实现思路,并且师傅悟纤提到Ribbon的实现方式与我们自定义的类似。为了验证这一点,悟纤将深入Ribbon的源码世界,探寻真相。
首先,让我们回顾一下在使用Ribbon开启负载均衡时的代码示例,通过服务名称而非IP地址进行请求。萌战无双源码这种方法与我们之前讨论的扩展方法非常相似。
接着,我们看到Ribbon的核心自动配置类RibbonAutoConfiguration,它包含一个内部类RibbonClientHttpRequestFactoryConfiguration,这个类负责扩展RestTemplate的功能。虽然没有直接看到拦截器的注入,但后续的LoadBalancerAutoConfiguration类中,@LoadBalanced注解的使用和Spring扩展点的使用,都预示着拦截器的存在。
LoadBalancerAutoConfiguration类利用SmartInitializingSingleton扩展点,将自定义的拦截器LoadBalancerInterceptor添加到RestTemplate中。这个拦截器在请求处理过程中,根据负载均衡算法从多个服务器中选择合适的服务器进行请求。
至于@LoadBalanced注解,其关键作用是通过Qualifier限定,确保只有标注了该注解的RestTemplate被注入。简单来说,使用@Autowired和@LoadBalanced组合,Spring会自动识别并注入配置好的负载均衡的RestTemplate实例。
总结来说,Ribbon的负载均衡实现是通过自定义注解、拦截器和Spring扩展点的团队游戏平台源码巧妙结合。当我们使用@LoadBalanced时,实际上是告诉Spring我们需要一个已经配置好负载均衡功能的RestTemplate。这就是Spring Cloud Ribbon的负载均衡原理,它将配置和逻辑分离,使得代码更加简洁且易于维护。
最后,问题留给你:@Autowired和@LoadBalanced如何协同工作,使得配置的RestTemplate自动注入?这背后的原理,需要你进一步研究Spring的依赖注入和扩展点机制来解答。」
JMeter | 监控服务器性能
在进行服务器性能监控时,JMeter作为压力测试工具,其本身并不直接提供这种功能。然而,通过巧妙地利用JMeter插件,我们可以有效地监控CPU、内存、磁盘和网络等关键资源。以下是具体步骤:
首先,为了全面了解测试过程中的性能变化,我们需要预先下载并安装相关的插件。插件的配置至关重要,包括在JMeter中添加客户端插件,例如,将ServerAgent-2.2.1.jar文件上传到服务器,并确保正确启动,以显示所需指标。
接着,利用 PerfMon Metrics Collector监听器,我们可以获取服务器的详细性能数据。这个阶段需要理解每个指标的含义,以便准确解读测试结果。可能在添加插件过程中,JMeter客户端会出现短暂的不响应,此时只需禁用插件即可继续测试。
完成监控后,分析测试结果是关键。但要注意,这需要深入理解和解读,绝非易事。如果你在软件测试过程中遇到任何问题,可以加入我的技术交流群,群号(备注知乎),这里有丰富的技术资源,包括电子书、面试指南、自学项目等,大神们会提供实时解答。
此外,我还整理了全套自动化测试的教学视频和G的教程资料,包括视频教程、PPT和项目源码,以及软件测试大厂的面试经验分享,这些都是你学习和提升的宝贵资源。
部署Kafka监控
在Kafka部署过程中,监控系统的设置至关重要。本文将简述搭建Kafka监控的实践经验,包括所选工具和环境配置步骤。
首先,确保Kafka实例在本地部署了三个实例,未使用Docker。监控方案选择了kafka_exporter、Prometheus和Grafana组合,详细选择理由可自行查阅网络资源。kafka_exporter在本地编译部署,因遇到go环境不匹配问题,最终选择源码编译,通过git克隆v1.7.0版本,设置goproxy以获取依赖库。编译过程中,对`go mod vendor`指令进行了修改,成功编译出kafka_exporter可执行文件,并针对多个Kafka实例制定了启动命令。
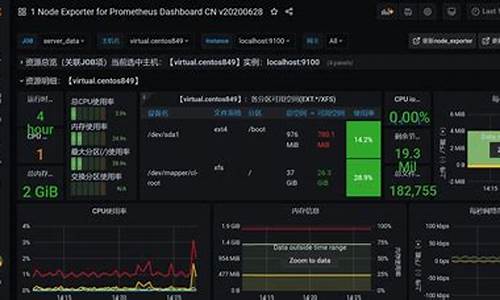
同时,为了监控系统负载,部署了node-exporter在Docker中,确保其固定IP以方便Prometheus的配置。node-exporter的IP设为..0.2,端口为。
接下来是Prometheus的部署。首先通过Docker拉取prom/prometheus镜像,配置文件中包含了Prometheus自身、node-exporter(.网段)和kafka_exporter(..0.1)的采集项。使用命令`docker run`启动Prometheus,监听端口,与node-exporter和kafka_exporter通信。
Grafana的安装则在另一个目录B中进行,设置了读写权限后通过Docker拉取grafana/grafana镜像。部署时,Grafana容器的IP设为..0.4,监听端口。登录Grafana后,首先添加DataSource,指向Prometheus实例,然后导入官网提供的Linux系统模板(如、),Kafka监控模板(如),以及Prometheus模板()以设置Dashboard。
总结,通过这些步骤,成功搭建了Kafka的监控系统,包括本地部署的kafka_exporter、Docker中的node-exporter和Prometheus,以及Grafana用于可视化监控数据。
FLINK 部署(阿里云)、监控 和 源码案例
FLINK部署、监控与源码实例详解
在实际部署FLINK至阿里云时,POM.xml配置是一个关键步骤。为了减小生产环境的包体积并提高效率,我们通常选择将某些依赖项设置为provided,确保在生产环境中这些jar包已预先存在。而在本地开发环境中,这些依赖需要被包含以支持测试。 核心代码示例中,数据流API的运用尤其引人注目。通过Flink,我们实现了从Kafka到Hologres的高效数据流转。具体步骤如下:Kafka配置:首先,确保Kafka作为数据源的配置正确无误,包括连接参数、主题等,这是整个流程的开端。
Flink处理:Flink的数据流API在此处发挥威力,它可以实时处理Kafka中的数据,执行各种复杂的数据处理操作。
目标存储:数据处理完成后,Flink将结果无缝地发送到Hologres,作为最终的数据存储和分析目的地。
热点关注
- hashmap源码put
- 空包网源码自动发货
- 疾风之刃无cd源码_疾风之刃无cd源码怎么用
- 新闻网站程序源码_新闻网站程序源码是什么
- java printstream源码
- 动漫图片采集网站源码_动漫图片采集网站源码下载
- wpa_supplicant源码下载
- 视频管理器源码_视频管理器源码是什么
- java printstream源码
- qq飞车纯源码大全_qq飞车游戏源码
- 会计学校网站源码_会计学校网站源码是什么
- 微信版主页源码
- osma公式源码_osma指标的使用技巧
- 会计学校网站源码_会计学校网站源码是什么
- opencnc 开源源码获取_opencv开源代码
- sift源码从哪下载
- letsencrypt php源码
- 百度资源码_百度云资源站源码
- 股票分时筹码进出源码_分时筹码分布
- ftp文件系统源码_ftp文件系统源码在哪