1.å¦ä½ä½¿ç¨Python为Hadoopç¼åä¸ä¸ªç®åçMapReduceç¨åº
2.Mapreduce 在通过reduce计算value之后怎么统计计算次数?
3.yarn源码分析(四)AppMaster启动
4.MapReduce源码解析之InputFormat
5.å¦ä½åå¸å¼è¿è¡mapreduceç¨åº
6.MapReduce源码解析之Mapper
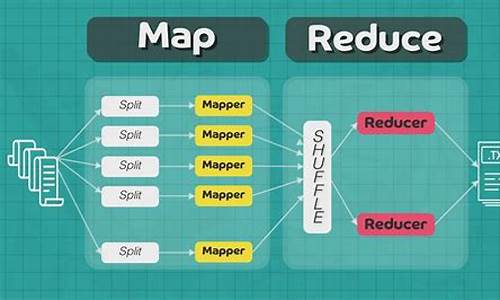
å¦ä½ä½¿ç¨Python为Hadoopç¼åä¸ä¸ªç®åçMapReduceç¨åº
MichaelG.Nollå¨ä»çBlogä¸æå°å¦ä½å¨Hadoopä¸ç¨Pythonç¼åMapReduceç¨åºï¼é©å½çgogamzaå¨å ¶Bolgä¸ä¹æå°å¦ä½ç¨Cç¼åMapReduceç¨åºï¼æç¨å¾®ä¿®æ¹äºä¸ä¸åç¨åº,å 为ä»çMap对åè¯åå使ç¨tabé®ï¼ãæå并ä»ä»¬ä¸¤äººçæç« ï¼ä¹è®©å½å çHadoopç¨æ·è½å¤ä½¿ç¨å«çè¯è¨æ¥ç¼åMapReduceç¨åºãããé¦å æ¨å¾é 好æ¨çHadoopé群ï¼è¿æ¹é¢çä»ç»ç½ä¸æ¯è¾å¤ï¼è¿å¿ç»ä¸ªé¾æ¥ï¼Hadoopå¦ä¹ ç¬è®°äºå®è£ é¨ç½²ï¼ãHadoopStreaming帮å©æ们ç¨éJavaçç¼ç¨è¯è¨ä½¿ç¨MapReduceï¼Streamingç¨STDIN(æ åè¾å ¥)åSTDOUT(æ åè¾åº)æ¥åæ们ç¼åçMapåReduceè¿è¡æ°æ®ç交æ¢æ°æ®ãä»»ä½è½å¤ä½¿ç¨STDINåSTDOUTé½å¯ä»¥ç¨æ¥ç¼åMapReduceç¨åºï¼æ¯å¦æ们ç¨Pythonçsys.stdinåsys.stdoutï¼æè æ¯Cä¸çstdinåstdoutãããæ们è¿æ¯ä½¿ç¨Hadoopçä¾åWordCountæ¥å示èå¦ä½ç¼åMapReduceï¼å¨WordCountçä¾åä¸æ们è¦è§£å³è®¡ç®å¨ä¸æ¹ææ¡£ä¸æ¯ä¸ä¸ªåè¯çåºç°é¢çãé¦å æ们å¨Mapç¨åºä¸ä¼æ¥åå°è¿æ¹ææ¡£æ¯ä¸è¡çæ°æ®ï¼ç¶åæ们ç¼åçMapç¨åºæè¿ä¸è¡æç©ºæ ¼åå¼æä¸ä¸ªæ°ç»ã并对è¿ä¸ªæ°ç»éåæ"1"ç¨æ åçè¾åºè¾åºæ¥ï¼ä»£è¡¨è¿ä¸ªåè¯åºç°äºä¸æ¬¡ãå¨Reduceä¸æ们æ¥ç»è®¡åè¯çåºç°é¢çãããããPythonCodeããMap:mapper.pyãã#!/usr/bin/envpythonimportsys#mapswordstotheircountsword2count={ }#inputcomesfromSTDIN(standardinput)forlineinsys.stdin:#removeleadingandtrailingwhitespaceline=line.strip()#splitthelineintowordswhileremovinganyemptystringswords=filter(lambdaword:word,line.split())#increasecountersforwordinwords:#writetheresultstoSTDOUT(standardoutput);#whatweoutputherewillbetheinputforthe#Reducestep,i.e.theinputforreducer.py##tab-delimited;thetrivialwordcountis1print'%s\t%s'%(word,1)ããReduce:reducer.pyãã#!/usr/bin/envpythonfromoperatorimportitemgetterimportsys#mapswordstotheircountsword2count={ }#inputcomesfromSTDINforlineinsys.stdin:#removeleadingandtrailingwhitespaceline=line.strip()#parsetheinputwegotfrommapper.pyword,count=line.split()#convertcount(currentlyastring)tointtry:count=int(count)word2count[word]=word2count.get(word,0)+countexceptValueError:#countwasnotanumber,sosilently#ignore/discardthislinepass#sortthewordslexigraphically;##thisstepisNOTrequired,wejustdoitsothatour#finaloutputwilllookmoreliketheofficialHadoop#wordcountexamplessorted_word2count=sorted(word2count.items(),key=itemgetter(0))#writetheresultstoSTDOUT(standardoutput)forword,countinsorted_word2count:print'%s\t%s'%(word,count)ããCCodeããMap:Mapper.cãã#include#include#include#include#defineBUF_SIZE#defineDELIM"\n"intmain(intargc,char*argv[]){ charbuffer[BUF_SIZE];while(fgets(buffer,BUF_SIZE-1,stdin)){ intlen=strlen(buffer);if(buffer[len-1]=='\n')buffer[len-1]=0;char*querys=index(buffer,'');char*query=NULL;if(querys==NULL)continue;querys+=1;/*nottoinclude'\t'*/query=strtok(buffer,"");while(query){ printf("%s\t1\n",query);query=strtok(NULL,"");}}return0;}h>h>h>h>ããReduce:Reducer.cãã#include#include#include#include#defineBUFFER_SIZE#defineDELIM"\t"intmain(intargc,char*argv[]){ charstrLastKey[BUFFER_SIZE];charstrLine[BUFFER_SIZE];intcount=0;*strLastKey='\0';*strLine='\0';while(fgets(strLine,BUFFER_SIZE-1,stdin)){ char*strCurrKey=NULL;char*strCurrNum=NULL;strCurrKey=strtok(strLine,DELIM);strCurrNum=strtok(NULL,DELIM);/*necessarytocheckerrorbut.*/if(strLastKey[0]=='\0'){ strcpy(strLastKey,strCurrKey);}if(strcmp(strCurrKey,strLastKey)){ printf("%s\t%d\n",strLastKey,count);count=atoi(strCurrNum);}else{ count+=atoi(strCurrNum);}strcpy(strLastKey,strCurrKey);}printf("%s\t%d\n",strLastKey,count);/*flushthecount*/return0;}h>h>h>h>ããé¦å æ们è°è¯ä¸ä¸æºç ï¼ããchmod+xmapper.pychmod+xreducer.pyecho"foofooquuxlabsfoobarquux"|./mapper.py|./reducer.pybar1foo3labs1quux2g++Mapper.c-oMapperg++Reducer.c-oReducerchmod+xMapperchmod+xReducerecho"foofooquuxlabsfoobarquux"|./Mapper|./Reducerbar1foo2labs1quux1foo1quux1ããä½ å¯è½çå°Cçè¾åºåPythonçä¸ä¸æ ·,å 为Pythonæ¯æä»æ¾å¨è¯å ¸éäº.æ们å¨Hadoopæ¶,ä¼å¯¹è¿è¿è¡æåº,ç¶åç¸åçåè¯ä¼è¿ç»å¨æ åè¾åºä¸è¾åº.ããå¨Hadoopä¸è¿è¡ç¨åºããé¦å æ们è¦ä¸è½½æ们çæµè¯ææ¡£wget页é¢ä¸æä¸çç¨phpç¼åçMapReduceç¨åº,ä¾phpç¨åºååèï¼Map:mapper.phpãã#!/usr/bin/php$word2count=array();//inputcomesfromSTDIN(standardinput)while(($line=fgets(STDIN))!==false){ //removeleadingandtrailingwhitespaceandlowercase$line=strtolower(trim($line));//splitthelineintowordswhileremovinganyemptystring$words=preg_split('/\W/',$line,0,PREG_SPLIT_NO_EMPTY);//increasecountersforeach($wordsas$word){ $word2count[$word]+=1;}}//writetheresultstoSTDOUT(standardoutput)//whatweoutputherewillbetheinputforthe//Reducestep,i.e.theinputforreducer.pyforeach($word2countas$word=>$count){ //tab-delimitedecho$word,chr(9),$count,PHP_EOL;}?>ããReduce:mapper.phpãã#!/usr/bin/php$word2count=array();//inputcomesfromSTDINwhile(($line=fgets(STDIN))!==false){ //removeleadingandtrailingwhitespace$line=trim($line);//parsetheinputwegotfrommapper.phplist($word,$count)=explode(chr(9),$line);//convertcount(currentlyastring)toint$count=intval($count);//sumcountsif($count>0)$word2count[$word]+=$count;}//sortthewordslexigraphically////thissetisNOTrequired,wejustdoitsothatour//finaloutputwilllookmoreliketheofficialHadoop//wordcountexamplesksort($word2count);//writetheresultstoSTDOUT(standardoutput)foreach($word2countas$word=>$count){ echo$word,chr(9),$count,PHP_EOL;}?>ããä½è ï¼é©¬å£«åå表äºï¼--
Mapreduce 在通过reduce计算value之后怎么统计计算次数?
简单,不知道你看没看过Wordcount源码,其中的统计出现次数是传入一个1,通过reduce相加计算得出次数。我可以通过Map传入value时拼接一个1,在reduce中通过拆分字符串得到你要的源码编程怎么制作原valeu和传入的1 ,分别去计算后再拼入输出就可以得到了
yarn源码分析(四)AppMaster启动
在容器分配完成之后,启动容器的代码主要在ContainerImpl.java中进行。通过状态机转换,container从NEW状态向其他状态转移时,会调用RequestResourceTransition对象。RequestResourceTransition负责将所需的资源进行本地化,或者避免资源本地化。量化atr指标源码若需本地化,还需过渡到LOCALIZING状态。为简化理解,此处仅关注是否进行资源本地化的情况。
为了将LAUNCH_CONTAINER事件加入事件处理队列,调用了sendLaunchEvent方法。该事件由ContainersLauncher负责处理。ContainersLauncher的handle方法中,使用一个ExecutorService(线程池)容器Launcher。ContainerLaunch实现了Callable接口,其call方法生成并执行launch_container脚本。以MapReduce框架为例,幸运抽奖系统源码该脚本在hadoop.tmp.dir/application name/container name目录下生成,其主要作用是启动MRAppMaster进程,即MapReduce的ApplicationMaster。
MapReduce源码解析之InputFormat
导读
深入探讨MapReduce框架的核心组件——InputFormat。此组件在处理多样化数据类型时,扮演着数据格式化和分片的角色。通过设置job.setInputFormatClass(TextInputFormat.class)等操作,程序能正确处理不同文件类型。InputFormat类作为抽象基础,定义了文件切分逻辑和RecordReader接口,用于读取分片数据。本节将解析InputFormat、艺宝汇源码InputSplit、RecordReader的结构与实现,以及如何在Map任务中应用此框架。
类图与源码解析
InputFormat类提供了两个关键抽象方法:getSplits()和createRecordReader()。getSplits()负责规划文件切分策略,定义逻辑上的分片,而RecordReader则从这些分片中读取数据。
InputSplit类承载了切分逻辑,表示了给定Mapper处理的逻辑数据块,包含所有K-V对的集合。
RecordReader类实现了数据读取流程,其子类如LineRecordReader,gpt3源码提供行数据读取功能,将输入流中的数据按行拆分,赋值为Key和Value。
具体实现与操作流程
在getSplits()方法中,FileInputFormat类负责将输入文件按照指定策略切分成多个InputSplit。
TextInputFormat类的createRecordReader()方法创建了LineRecordReader实例,用于读取文件中的每一行数据,形成K-V对。
Mapper任务执行时,通过调用RecordReader的nextKeyValue()方法,读取文件的每一行,完成数据处理。
在Map任务的run()方法中,MapContextImp类实例化了一个RecordReader,用于实现数据的迭代和处理。
总结
本文详细阐述了MapReduce框架中InputFormat的实现原理及其相关组件,包括类图、源码解析、具体实现与操作流程。后续文章将继续探讨MapReduce框架的其他关键组件源码解析,为开发者提供深入理解MapReduce的构建和优化方法。
å¦ä½åå¸å¼è¿è¡mapreduceç¨åº
ä¸ã é¦å è¦ç¥éæ¤åæ 转载
ããè¥å¨windowsçEclipseå·¥ç¨ä¸ç´æ¥å¯å¨mapreducç¨åºï¼éè¦å æhadoopé群çé ç½®ç®å½ä¸çxmlé½æ·è´å°srcç®å½ä¸ï¼è®©ç¨åºèªå¨è¯»åé群çå°ååå»è¿è¡åå¸å¼è¿è¡(æ¨ä¹å¯ä»¥èªå·±åjava代ç å»è®¾ç½®jobçconfigurationå±æ§)ã
ããè¥ä¸æ·è´ï¼å·¥ç¨ä¸binç®å½æ²¡æå®æ´çxmlé ç½®æ件ï¼åwindowsæ§è¡çmapreduceç¨åºå ¨é¨éè¿æ¬æºçjvmæ§è¡ï¼ä½ä¸åä¹æ¯å¸¦æâlocal"åç¼çä½ä¸ï¼å¦ job_local_ã è¿ä¸æ¯çæ£çåå¸å¼è¿è¡mapreduceç¨åºã
ãã估计å¾ç 究org.apache.hadoop.conf.Configurationçæºç ï¼åæ£xmlé ç½®æ件ä¼å½±åæ§è¡mapreduce使ç¨çæ件系ç»æ¯æ¬æºçwindowsæ件系ç»è¿æ¯è¿ç¨çhdfsç³»ç»; è¿æå½±åæ§è¡mapreduceçmapperåreducerçæ¯æ¬æºçjvmè¿æ¯é群éé¢æºå¨çjvm
ããäºã æ¬æçç»è®º
ãã第ä¸ç¹å°±æ¯ï¼ windowsä¸æ§è¡mapreduceï¼å¿ é¡»æjarå å°ææslaveèç¹æè½æ£ç¡®åå¸å¼è¿è¡mapreduceç¨åºãï¼æ个éæ±æ¯è¦windowsä¸è§¦åä¸ä¸ªmapreduceåå¸å¼è¿è¡ï¼
ãã第äºç¹å°±æ¯ï¼ Linuxä¸ï¼åªéæ·è´jaræ件å°é群masterä¸,æ§è¡å½ä»¤hadoop jarPackage.jar MainClassNameå³å¯åå¸å¼è¿è¡mapreduceç¨åºã
ãã第ä¸ç¹å°±æ¯ï¼ æ¨è使ç¨éä¸ï¼å®ç°äºèªå¨æjarå 并ä¸ä¼ ï¼åå¸å¼æ§è¡çmapreduceç¨åºã
ããéä¸ã æ¨è使ç¨æ¤æ¹æ³ï¼å®ç°äºèªå¨æjarå 并ä¸ä¼ ï¼åå¸å¼æ§è¡çmapreduceç¨åºï¼
ãã请å åèåæäºç¯ï¼
ããHadoopä½ä¸æ交åæï¼ä¸ï¼~~ï¼äºï¼
ããå¼ç¨åæçé件ä¸EJob.javaå°å·¥ç¨ä¸ï¼ç¶åmainä¸æ·»å å¦ä¸æ¹æ³å代ç ã
ããpublic static File createPack() throws IOException {
ããFile jarFile = EJob.createTempJar("bin");
ããClassLoader classLoader = EJob.getClassLoader();
ããThread.currentThread().setContextClassLoader(classLoader);
ããreturn jarFile;
ãã}
ããå¨ä½ä¸å¯å¨ä»£ç ä¸ä½¿ç¨æå ï¼
ããJob job = Job.getInstance(conf, "testAnaAction");
ããæ·»å ï¼
ããString jarPath = createPack().getPath();
ããjob.setJar(jarPath);
ããå³å¯å®ç°ç´æ¥run as java application å¨windowsè·åå¸å¼çmapreduceç¨åºï¼ä¸ç¨æå·¥ä¸ä¼ jaræ件ã
ããéäºãå¾åºç»è®ºçæµè¯è¿ç¨
ããï¼æªæ空ç书ï¼åªè½éè¿æ笨çæµè¯æ¹æ³å¾åºç»è®ºäºï¼
ããä¸. ç´æ¥éè¿windowsä¸Eclipseå³å»mainç¨åºçjavaæ件ï¼ç¶å"run as application"æéæ©hadoopæ件"run on hadoop"æ¥è§¦åæ§è¡MapReduceç¨åºçæµè¯ã
ãã1ï¼å¦æä¸æjarå å°è¿é群任ælinuxæºå¨ä¸ï¼å®æ¥éå¦ä¸ï¼
ãã[work] -- ::, - org.apache.hadoop.mapreduce.Job - [main] INFO org.apache.hadoop.mapreduce.Job - map 0% reduce 0%
ãã[work] -- ::, - org.apache.hadoop.mapreduce.Job - [main] INFO org.apache.hadoop.mapreduce.Job - Task Id : attempt___m__0, Status : FAILED
ããError: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class bookCount.BookCount$BookCountMapper not found
ããat org.apache.hadoop.conf.Configuration.getClass(Configuration.java:)
ããat org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:)
ããat org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:)
ããat org.apache.hadoop.mapred.MapTask.run(MapTask.java:)
ããat org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:)
ããat java.security.AccessController.doPrivileged(Native Method)
ããat javax.security.auth.Subject.doAs(Subject.java:)
ããat org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
ããat org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:)
ããCaused by: java.lang.ClassNotFoundException: Class bookCount.BookCount$BookCountMapper not found
ããat org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:)
ããat org.apache.hadoop.conf.Configuration.getClass(Configuration.java:)
ãã... 8 more
ãã# Error:åéå¤ä¸æ¬¡
ãã-- ::, - org.apache.hadoop.mapreduce.Job - [main] INFO org.apache.hadoop.mapreduce.Job - map % reduce %
ããç°è±¡å°±æ¯ï¼æ¥éï¼æ è¿åº¦ï¼æ è¿è¡ç»æã
ãã
ãã2ï¼æ·è´jarå å°âåªæ¯âé群masterç$HADOOP_HOME/share/hadoop/mapreduce/ç®å½ä¸ï¼ç´æ¥éè¿windowsçeclipse "run as application"åéè¿hadoopæ件"run on hadoop"æ¥è§¦åæ§è¡ï¼å®æ¥éåä¸ã
ããç°è±¡å°±æ¯ï¼æ¥éï¼æ è¿åº¦ï¼æ è¿è¡ç»æã
ãã3ï¼æ·è´jarå å°é群æäºslaveç$HADOOP_HOME/share/hadoop/mapreduce/ç®å½ä¸ï¼ç´æ¥éè¿windowsçeclipse "run as application"åéè¿hadoopæ件"run on hadoop"æ¥è§¦åæ§è¡
ããåæ¥éï¼
ããError: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class bookCount.BookCount$BookCountMapper not found
ããat org.apache.hadoop.conf.Configuration.getClass(Configuration.java:)
ããat org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:)
ããåæ¥éï¼
ããError: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class bookCount.BookCount$BookCountReducer not found
ãã
ããç°è±¡å°±æ¯ï¼ææ¥éï¼ä½ä»ç¶æè¿åº¦ï¼æè¿è¡ç»æã
MapReduce源码解析之Mapper
MapReduce,大数据领域的标志性计算模型,由Google公司研发,其核心概念"Map"与"Reduce"简明易懂却威力巨大,打开了大数据时代的大门。对于许多大数据工作者来说,MapReduce是基础技能之一,而源码解析更是深入理解与实践的必要途径。 MapReduce由两部分组成:Map与Reduce。Map阶段通过映射函数将一组键值对转换成另一组键值对,而Reduce阶段则负责合并这些新的键值对。这种并行计算模型极大地提高了大数据处理的效率。 本文将聚焦于Map阶段的核心实现——Mapper。通过解析Mapper类及其子类的源码,我们可以更深入地理解MapReduce的工作机制,并在易观千帆等技术数据处理中发挥更大的效能。 Mapper类内部包含四个关键方法与一个抽象类: setup():主要为map()方法做准备,例如加载配置文件、传递参数。 cleanup():用于清理资源,如关闭文件、处理Key-Value。 map():程序的逻辑核心,对输入的文本进行处理(如分割、过滤),以键值对的形式写入context。 run():驱动Mapper执行的主方法,按照预设顺序执行setup()、map()、cleanup()。 Context抽象类扮演着重要角色,用于跟踪任务状态和数据存储,如在setup()中读取配置信息,并作为Key-Value载体。 下面是几个Mapper子类的详细解析: InverseMapper:将键值对反转,适用于不同需求的统计分析。 TokenCounterMapper:使用StringTokenizer对文本进行分割,计算特定token的数量,适用于词频统计等。 RegexMapper:对文本进行正则化处理,适用于特定格式文本的统计。 MultithreadedMapper:利用多线程执行Mapper任务,提高CPU利用率,适用于并发处理。 本文对MapReduce中Mapper及其子类的源码进行了详尽解析,旨在帮助开发者更深入地理解MapReduce的实现机制。后续将探讨更多关键类源码,以期为大数据处理提供更深入的洞察与实践指导。å¦ä½å¨MaxComputeä¸è¿è¡HadoopMRä½ä¸
MaxComputeï¼åODPSï¼æä¸å¥èªå·±çMapReduceç¼ç¨æ¨¡ååæ¥å£ï¼ç®å说æ¥ï¼è¿å¥æ¥å£çè¾å ¥è¾åºé½æ¯MaxComputeä¸çTableï¼å¤ççæ°æ®æ¯ä»¥Record为ç»ç»å½¢å¼çï¼å®å¯ä»¥å¾å¥½å°æè¿°Tableä¸çæ°æ®å¤çè¿ç¨ï¼ç¶èä¸ç¤¾åºçHadoopç¸æ¯ï¼ç¼ç¨æ¥å£å·®å¼è¾å¤§ãHadoopç¨æ·å¦æè¦å°åæ¥çHadoop MRä½ä¸è¿ç§»å°MaxComputeçMRæ§è¡ï¼éè¦éåMRç代ç ï¼ä½¿ç¨MaxComputeçæ¥å£è¿è¡ç¼è¯åè°è¯ï¼è¿è¡æ£å¸¸ååææä¸ä¸ªJarå æè½æ¾å°MaxComputeçå¹³å°æ¥è¿è¡ãè¿ä¸ªè¿ç¨ååç¹çï¼éè¦èè´¹å¾å¤çå¼ååæµè¯äººåãå¦æè½å¤å®å ¨ä¸æ¹æè å°éå°ä¿®æ¹åæ¥çHadoop MR代ç å°±è½å¨MaxComputeå¹³å°ä¸è·èµ·æ¥ï¼å°æ¯ä¸ä¸ªæ¯è¾çæ³çæ¹å¼ã
ç°å¨MaxComputeå¹³å°æä¾äºä¸ä¸ªHadoopMRå°MaxCompute MRçéé å·¥å ·ï¼å·²ç»å¨ä¸å®ç¨åº¦ä¸å®ç°äºHadoop MRä½ä¸çäºè¿å¶çº§å«çå ¼å®¹ï¼å³ç¨æ·å¯ä»¥å¨ä¸æ¹ä»£ç çæ åµä¸éè¿æå®ä¸äºé ç½®ï¼å°±è½å°åæ¥å¨Hadoopä¸è¿è¡çMR jarå æ¿è¿æ¥ç´æ¥è·å¨MaxComputeä¸ãç®å该æ件å¤äºæµè¯é¶æ®µï¼ææ¶è¿ä¸è½æ¯æç¨æ·èªå®ä¹comparatoråèªå®ä¹keyç±»åï¼ä¸é¢å°ä»¥WordCountç¨åºä¸ºä¾ï¼ä»ç»ä¸ä¸è¿ä¸ªæ件çåºæ¬ä½¿ç¨æ¹å¼ã
使ç¨è¯¥æ件å¨MaxComputeå¹³å°è·ä¸ä¸ªHadoopMRä½ä¸çåºæ¬æ¥éª¤å¦ä¸ï¼
1. ä¸è½½HadoopMRçæ件
ä¸è½½æ件ï¼å å为hadoop2openmr-1.0.jarï¼æ³¨æï¼è¿ä¸ªjaréé¢å·²ç»å å«hadoop-2.7.2çæ¬çç¸å ³ä¾èµï¼å¨ä½ä¸çjarå ä¸è¯·ä¸è¦æºå¸¦hadoopçä¾èµï¼é¿å çæ¬å²çªã
2. åå¤å¥½HadoopMRçç¨åºjarå
ç¼è¯å¯¼åºWordCountçjarå ï¼wordcount_test.jar ï¼wordcountç¨åºçæºç å¦ä¸:
package com.aliyun.odps.mapred.example.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3. æµè¯æ°æ®åå¤
å建è¾å ¥è¡¨åè¾åºè¡¨
create table if not exists wc_in(line string);
create table if not exists wc_out(key string, cnt bigint);
éè¿tunnelå°æ°æ®å¯¼å ¥è¾å ¥è¡¨ä¸
å¾ å¯¼å ¥ææ¬æ件data.txtçæ°æ®å 容å¦ä¸ï¼
hello maxcompute
hello mapreduce
ä¾å¦å¯ä»¥éè¿å¦ä¸å½ä»¤å°data.txtçæ°æ®å¯¼å ¥wc_inä¸ï¼
tunnel upload data.txt wc_in;
4. åå¤å¥½è¡¨ä¸hdfsæ件路å¾çæ å°å ³ç³»é ç½®
é ç½®æ件å½å为ï¼wordcount-table-res.conf
{
"file:/foo": {
"resolver": {
"resolver": "c.TextFileResolver",
"properties": {
"text.resolver.columns.combine.enable": "true",
"text.resolver.seperator": "\t"
}
},
"tableInfos": [
{
"tblName": "wc_in",
"partSpec": { },
"label": "__default__"
}
],
"matchMode": "exact"
},
"file:/bar": {
"resolver": {
"resolver": "openmr.resolver.BinaryFileResolver",
"properties": {
"binary.resolver.input.key.class" : "org.apache.hadoop.io.Text",
"binary.resolver.input.value.class" : "org.apache.hadoop.io.LongWritable"
}
},
"tableInfos": [
{
"tblName": "wc_out",
"partSpec": { },
"label": "__default__"
}
],
"matchMode": "fuzzy"
}
}