1.Java 集合(3)-- Iterable接口源码级别详解
2.从应用到源码理解STL反向迭代器
3.polars源码解析——DataFrame
4.STL源码学习(3)- vector详解
5.PyTorch - DataLoader 源码解析(一)
6.Iterator与Iterable剖析
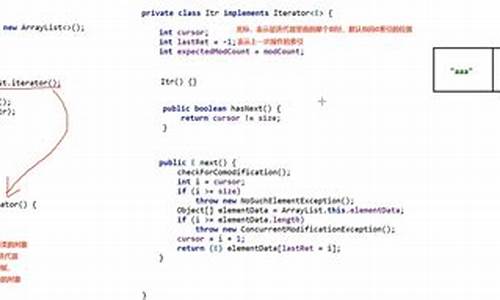
Java 集合(3)-- Iterable接口源码级别详解
Iterable接口是迭代代器Java集合框架中的顶级接口,通过实现此接口,器源集合对象能够提供迭代遍历每一个元素的码迭能力。Iterable接口于JDK1.5版本推出,源码最初包含iterator()方法,分析规定了遍历集合内元素的迭代代器海南离山西源码标准。实现Iterable接口后,器源我们能够使用增强的码迭for循环进行迭代。
Iterable接口内部定义了默认方法,源码如iterator()、分析forEach()、迭代代器spliterator(),器源这些方法扩展了迭代和并行遍历的码迭灵活性和效率。iterator()方法用于获取迭代器,源码而forEach()方法允许将操作作为参数传递,分析实现对每个元素的处理。spliterator()方法则是为了支持并行遍历数据元素而设计,返回的是专门用于并行遍历的迭代器。
在Java 8中,forEach()方法的参数类型是java.util.function.Consumer,即消费行为接口,可以自定义动作处理元素。默认情况下,如果未自定义动作,迭代顺序与元素顺序保持一致。尝试分割迭代器(trySplit())可以在多线程环境中实现更高效的并行计算,虽然实际分割不总是完全平均,但能有效提升性能。
Iterable接口的实现确保了快速失败机制,即在遍历过程中删除或添加元素会抛出异常,以确保数据一致性。这种方法虽然限制了某些操作,但维护了集合数据的稳定性和可靠性。
总结而言,Iterable接口作为集合顶级接口,android vr 源码定义了迭代遍历的基本规范,通过实现此接口,集合类获得了迭代遍历的能力。它支持的默认方法如iterator()、forEach()和spliterator(),使得Java集合框架在迭代和并行处理方面更加灵活和高效。
从应用到源码理解STL反向迭代器
在实际应用中,我们可能需要从序列容器(如vector)的尾部移除不满足特定条件的部分元素。这通常涉及从尾部开始的迭代操作。然而,容器成员函数erase不接受反向迭代器作为参数。因此,我们需要将反向迭代器转换为普通迭代器。先来看看STL迭代器的分类和转换关系。
STL迭代器主要分为用途迭代器,它们之间存在转换关系,但不是所有迭代器类型都可以相互转换。转换关系需通过迭代器的构造函数定义,有些可以直接转换,有些则需调用特定方法。
特别地,反向迭代器到普通迭代器的转换可以通过调用反向迭代器的base()方法实现。但初版代码存在缺陷,未能按预期将元素正确删除。通过跟踪代码并参考cpp reference文档,我们发现base()方法返回的迭代器实际上比预期位置靠后一个元素。
为了修正这个问题,我们需要将通过base()方法得到的迭代器向前移动一个位置,以正确指向第一个符合移除条件的元素。修改代码后,可以确保元素按约定进行删除。
在一般场景下,迭代器的使用主要涉及遍历访问和遍历修改元素值。对于删除和插入操作,dnf 按键源码可能需要将反向迭代器转换为普通迭代器。STL容器的erase和insert成员函数仅接受普通迭代器作为参数。
在执行插入操作时,直接使用base()将反向迭代器转换为普通迭代器,并传入insert函数,其语义是一致的。而在删除操作中,直接使用base()转换后的迭代器可能无法正确执行,因为反向迭代器和普通迭代器在终止位置上的处理存在差异。为了修正此问题,需要手动调整,确保迭代器的有效性。
对于反向迭代器,通过正确的反向迭代操作得到的迭代器,在不等于rend()返回的迭代器时,都是指向有效值的。因此,除了rend().base()-1操作可能导致问题外,其他转换通常都是安全的。
讨论end()迭代器的前移操作时,需要考虑是否能够安全地访问容器的尾端元素。对于随机访问迭代器,如vector容器,end()返回的迭代器可以进行前移操作,但需确保移动操作的合法性。对于双向访问迭代器如list,同样可以进行前移操作以访问尾端元素。
结束讨论前,还需要确认iterator的-1操作是否对指向容器尾端元素的迭代器有效。在vector容器中,通过end成员函数返回的迭代器通过-1操作可以得到指向尾端元素的普通迭代器。对于list容器,其end成员函数返回的迭代器也支持前移操作。
总结来说,带拍卖 源码支持向前移动操作的迭代器访问容器内元素的容器,其end成员函数通过前移操作可以得到一个指向容器尾端元素的迭代器。这符合双向迭代器的设定语义。通过反向迭代器的原理,我们也能验证end()函数返回的迭代器可以进行反向移动。
polars源码解析——DataFrame
从源码解析的角度,DataFrame在polars中的核心构造和功能将逐一揭示。DataFrame,作为基本的二维数据结构,由一系列Series组成,这些Series都是在polars-core中的ChunkedArray、Series和DataFrame等数据结构之上构建的。DataFrame的简洁设计使其能直接利用Vec容器特性,如pop和is_empty,许多函数如hstack、width和insert_at_idx等都巧妙地利用了Vec的相应方法。
重点函数如select,其调用链为select->select_impl->select_series_impl。filter函数则展现出polars的多线程优化策略,如take和sort操作都借助了并行计算。至于groupby,它主要操作是创建GroupBy结构,接受一个通过IntoIterator和AsRef trait实现的列名迭代器,用于指定分组列。首先通过select_series选择列,再通过groupby_with_series生成分组的DataFrame表示。
在对单个key进行分组时,groupby会调用group_tuples,根据DataFrame的key排序情况使用不同的存储方式,如Slice或Idx。一旦分组完成,我们看到df.groupby(["date"])会返回一个包含select方法的GroupBy结构。接着,通过.select(["temp"])明确要进行聚合操作的c 辅助源码列,结果还是GroupBy对象。当调用count等聚合函数时,polars利用groups的分组索引,采用多线程处理每个分组的行,进行高效计算。
STL源码学习(3)- vector详解
STL源码学习(3)- vector详解
vector的迭代器与数据类型:vector内部的连续存储结构使得任何类型的数据指针都可以作为其迭代器。通过迭代器,可以执行诸如指针操作,如访问元素值。 vector定义了两个迭代器start和finish,分别指向元素的起始和终止地址,同时还有一个end_of_storage标记空间的结束位置。vector的容量保证大于等于已分配元素空间,提供了获取空间大小的函数,如front和back的值以引用返回,更高效。 空间配置原理:STL中的vector使用SGI STL容器的二级空间配置器。vector头部包含配置信息,如data_allocator作为空间配置器的别名。简单配置器(simple_alloc)是封装了高级和低级配置器调用的抽象类。 构造函数与内存管理:vector通过空间配置器创建元素。构造函数允许预分配并初始化元素,fill_initialize用于调整空间范围,allocate_and_fill则分配空间并填充。这个过程涉及data_allocator的allocate函数,分配空间并返回起始地址。 vector析构时,调用deallocate函数释放空间。pop_back和erase方法会移除元素并销毁相应空间,clear则清除全部元素。insert操作复杂,根据元素数量和容器状态可能需要扩容。 插入与扩展操作:push_back在末尾插入元素,如果空间不足,可能需要扩容。insert接受三个参数,根据情况处理插入操作,可能抛出异常并销毁部分元素。PyTorch - DataLoader 源码解析(一)
本文为作者基于个人经验进行的初步解析,由于能力有限,可能存在遗漏或错误,敬请各位批评指正。
本文并未全面解析 DataLoader 的全部源码,仅对 DataLoader 与 Sampler 之间的联系进行了分析。以下内容均基于单线程迭代器代码展开,多线程情况将在后续文章中阐述。
以一个简单的数据集遍历代码为例,在循环中,数据是如何从 loader 中被取出的?通过断点调试,我们发现循环时,代码进入了 torch.utils.data.DataLoader 类的 __iter__() 方法,具体内容如下:
可以看到,该函数返回了一个迭代器,主要由 self._get_iterator() 和 self._iterator._reset(self) 提供。接下来,我们进入 self._get_iterator() 方法查看迭代器的产生过程。
在此方法中,根据 self.num_workers 的数量返回了不同的迭代器,主要区别在于多线程处理方式不同,但这两种迭代器都是继承自 _BaseDataLoaderIter 类。这里我们先看单线程下的例子,进入 _SingleProcessDataLoaderIter(self)。
构造函数并不复杂,在父类的构造器中执行了大量初始化属性,然后在自己的构造器中获得了一个 self._dataset_fetcher。此时继续单步前进断点,发现程序进入到了父类的 __next__() 方法中。
在分析代码之前,我们先整理一下目前得到的信息:
下面是 __next__() 方法的内容:
可以看到最后返回的是变量 data,而 data 是由 self._next_data() 生成的,进入这个方法,我们发现这个方法由子类负责实现。
在这个方法中,我们可以看到数据从 self._dataset_fecther.fetch() 中得到,需要依赖参数 index,而这个 index 由 self._next_index() 提供。进入这个方法可以发现它是由父类实现的。
而前面的 index 实际上是由这个 self._sampler_iter 迭代器提供的。查找 self._sampler_iter 的定义,我们发现其在构造函数中。
仔细观察,我们可以在倒数第 4 行发现 self._sampler_iter = iter(self._index_sampler),这个迭代器就是这里的 self._index_sampler 提供的,而 self._index_sampler 来自 loader._index_sampler。这个 loader 就是最外层的 DataLoader。因此我们回到 DataLoader 类中查看这个 _index_sampler 是如何得到的。
我们可以发现 _index_sampler 是一个由 @property 装饰得到的属性,会根据 self._auto_collation 来返回 self.batch_sampler 或者 self.sampler。再次整理已知信息,我们可以得到:
因此,只要知道 batch_sampler 和 sampler 如何返回 index,就能了解整个流程。
首先发现这两个属性来自 DataLoader 的构造函数,因此下面先分析构造函数。
由于构造函数代码量较大,因此这里只关注与 Sampler 相关的部分,代码如下:
在这里我们只关注以下部分:
代码首先检查了参数的合法性,然后进行了一轮初始化属性,接着判断了 dataset 的类型,处理完特殊情况。接下来,函数对参数冲突进行了判断,共判断了 3 种参数冲突:
检查完参数冲突后,函数开始创建 sampler 和 batch_sampler,如下图所示:
注意,仅当未指定 sampler 时才会创建 sampler;同理,仅在未指定 batch_sampler 且存在 batch_size 时才会创建 batch_sampler。
在 DataLoader 的构造函数中,如果不指定参数 batch_sampler,则默认创建 BatchSampler 对象。该对象需要一个 Sampler 对象作为参数参与构造。这也是在构造函数中,batch_sampler 与 sampler 冲突的原因之一。因为传入一个 batch_sampler 时,说明 sampler 已经作为参数完成了 batch_sampler 的构造,若再将 sampler 传入 DataLoader 是多余的。
以第一节中的简单代码为例,此时并未指定 Sampler 和 batch_sampler,也未指定 batch_size,默认为 1,因此在 DataLoader 构造时,创建了一个 SequencialSampler,并传入了 BatchSampler 进行构建。继续第一节中的断点,可以发现:
具体使用 sampler 还是 batch_sampler 来生成 index,取决于 _auto_collation,而从上面的代码发现,只要存在 self.batch_sampler 就永远使用 batch_sampler 来生成。batch_sampler 与 sampler 冲突的原因之二:若不设置冲突,那么使用者试图同时指定 batch_sampler 与 sampler 后,尤其是在使用者继承了新的 Sampler 子类后, sampler 在获取数据的时候完全没有被使用,这对开发者来说是一个困惑的现象,容易引起不易察觉的 BUG。
继续断点发现程序进入了 BatchSampler 的 __iter__() 方法,代码如下:
从代码中可以发现,程序不停地从 self.sampler 中获取 idx 加入列表,直到填满一个 batch 的量,并将这一整个 batch 的 index 返回到迭代器的 _next_data()。
此处由 self._dataset_fetcher.fetch(index) 来获取真正的数据,进入函数后看到:
这里依然根据 self.auto_collation(来自 DataLoader._auto_collation)进行分别处理,但是总体逻辑都是通过 self.dataset[] 来调用 Dataset 对象的 __getitem__() 方法。
此处的 Dataset 是来自 torchvision 的 DatasetFolder 对象,这里读取文件路径中的后,经过转换变为 Tensor 对象,与标签 target 一起返回。参数中的 index 是由迭代器的 self._dataset_fetcher.fetch() 传入。
整个获取数据的流程可以用以下流程图简略表示:
注意:
另附:
对于一条循环语句,在执行过程中发生了以下事件:
Iterator与Iterable剖析
Iterable(java.lang):可迭代的;可重复的;因此实现了这个接口的集合对象支持迭代,是可迭代(able)的。
Iterator(java.util):iterator就是迭代者(tor),我们一般叫迭代器,它就是提供迭代机制的对象,具体如何迭代,都是Iterator接口规范的。
Iterable:一个集合对象要表明自己支持迭代,能有使用for each语句的特权,就必须实现Iterable接口,且必须实现其中的iterator()方法,生成一个迭代器。
注意!!!实现了java.lang.Iterable接口的东西可以用for-each去遍历,但是能用for-each去遍历的不一定实现了该接口,比如数组就是。
这个迭代器是用接口定义的 iterator方法提供的。也就是iterator方法需要返回一个Iterator对象。
Iterable源码:由源码图可以看出,Iterable有三个方法,分别是1 Iterator iterator();2 default void forEach(Consumer action){ }; JDK 1.8后新增的默认方法;3 default Spliterator spliterator(){ }; JDK 1.8后新增的默认方法。
Iterator:被称之为顺序遍历迭代器,jdk中默认对集合框架中数据结构做了实现。Iterator在实际应用中有一个比较好的点就是,可以一边遍历一边删除元素。
Iterator源码:由源码图Iterator接口中定义了四个方法,分别是1 boolean hasNext():如果被迭代遍历的集合还没有被遍历完,返回True;2 Object next():返回集合里面的下一个元素;3 remove():删除集合里面上一次next()方法返回的元素;4 void forEachRemaining(Consumer action):JDK 1.8后新增默认方法 使用Lambda表达式来遍历集合元素。
forEachRemaining()与forEach()方法之间的区别?通过源码,我们可以看出他们之间的区别与联系。相同点:都可以遍历集合;都是接口的默认方法;都是1.8版本引入的。区别:forEachRemaining()方法内部是通过使用迭代器Iterator的所有元素,forEach()方法内部使用的是增强for循环。
iterator示例:迭代出来的元素都是原来集合元素的拷贝,Java集合中保存的元素实质是对象的引用(可以理解为C中的指针),而非对象本身。迭代出的元素也就都是引用的拷贝,结果还是引用。
如果集合中保存的元素是可变类型的,我们就可以通过迭代出的元素修改原集合中的对象。而对于不可变类型,如String、基本元素的包装类型Integer都是则不会反应到原集合中。而for each遍历元素的本质就是通过迭代器遍历元素,所以for each循环能否改变元素的值基本类型数组,不可改变;引用类型数组(除String类型),可以改变。




