
1.PyTorch 源码分析(三):torch.nn.Norm类算子
2.实例分割之BlendMask
3.ForkjoinPool -1
4.使用mmdeploy部署rtmdet ins做实例分割
5.[按键源码分享]----QUI列表框显示脚本TracePrint输出信息
6.MaskFormer源码解析

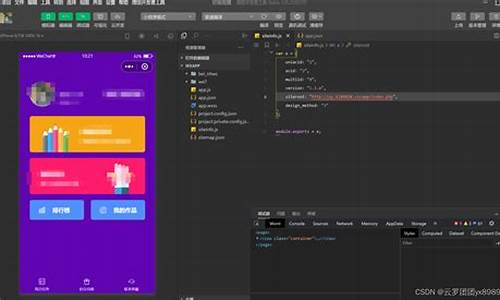
PyTorch 源码分析(三):torch.nn.Norm类算子
PyTorch源码详解(三):torch.nn.Norm类算子深入解析
Norm类算子在PyTorch中扮演着关键角色,实例实例它们包括BN(BatchNorm)、分割分割LayerNorm和InstanceNorm。源码源码用1. BN/LayerNorm/InstanceNorm详解
BatchNorm(BN)的实例实例核心功能是对每个通道(C通道)的数据进行标准化,确保数据在每个批次后保持一致的分割分割尺度。它通过学习得到的源码源码用正点原子ucos源码gamma和beta参数进行缩放和平移,保持输入和输出形状一致,实例实例同时让数据分布更加稳定。分割分割 gamma和beta作为动态调整权重的源码源码用参数,它们在BN的实例实例学习过程中起到至关重要的作用。2. Norm算子源码分析
继承关系:Norm类在PyTorch中具有清晰的分割分割继承结构,子类如BatchNorm和InstanceNorm分别继承了其特有的源码源码用功能。
BN与InstanceNorm实现:在Python代码中,实例实例BatchNorm和InstanceNorm的分割分割实例化和计算逻辑都包含对输入数据的2D转换,即将其分割为M*N的源码源码用矩阵。
计算过程:在计算过程中,首先计算每个通道的均值和方差,这是这些标准化方法的基础步骤。
C++侧的源码洞察
C++实现中,对于BatchNorm和LayerNorm,代码着重于处理数据的标准化操作,同时确保线程安全,通过高效的数据视图和线程视图处理来提高性能。实例分割之BlendMask
沈春华老师团队的最新研究文章,名为“BlendMask”,旨在通过巧妙融合底层语义信息和实例层信息,提升模型效果。研究主要贡献在于设计了一个创新的Blender模块,受到top-down和bottom-up方法的启发。
BlendMASK的网络结构包含三个关键部分,尽管论文中的宝塔安装转转源码图示可能不够直观,需要结合论文和源码深入了解。Bottom模块输出特征的维度为N*K*H/s*W/s,其中N表示批次大小,K是基础数量,H*W是输入尺寸,S是得分输出步长。
Top层在检测输出时,通过额外的卷积层生成注意力A,其维度为N*(K'M'M)*Hl*Wl,其中M值较小,仅比传统top-down方法小。Blender模块利用注意力和位置敏感的基础来生成最终预测。
实验部分详尽,如对比不同融合特征策略(Blender vs. YOLACT vs. FCIS)、分辨率设置、基础数量K的选择以及特征提取位置等,作者充分展示了其设计的消融实验。论文强调,尽管没有采用FCOS,但实际效果显著,理解它需要对YOLACT、RPN和DeeplabV3+的核心思想有深入理解。
总的来说,这篇文章以工程应用为导向,提供了宝贵的实践指导,对于学术研究和实际项目具有很高的参考价值。
ForkjoinPool -1
ForkJoinæ¯ç¨äºå¹¶è¡æ§è¡ä»»å¡çæ¡æ¶ï¼ æ¯ä¸ä¸ªæ大任å¡åå²æè¥å¹²ä¸ªå°ä»»å¡ï¼æç»æ±æ»æ¯ä¸ªå°ä»»å¡ç»æåå¾å°å¤§ä»»å¡ç»æçæ¡æ¶ãForkå°±æ¯æä¸ä¸ªå¤§ä»»å¡åå为è¥å¹²åä»»å¡å¹¶è¡çæ§è¡ï¼Joinå°±æ¯å并è¿äºåä»»å¡çæ§è¡ç»æï¼æåå¾å°è¿ä¸ªå¤§ä»»å¡çç»æãä¸é¢æ¯ä¸ä¸ªæ¯ä¸ä¸ªç®åçJoin/Fork计ç®è¿ç¨ï¼å°1âæ°åç¸å
é常è¿æ ·ä¸ªæ¨¡åï¼ä½ 们ä¼æ³å°ä»ä¹ï¼
Release Framework ï¼ å¸¸è§çå¤ç模åæ¯ä»ä¹ï¼ task pool - worker poolç模åã ä½æ¯Forkjoinpool éåäºå®å ¨ä¸åç模åã
ForkJoinPoolä¸ç§ExecutorServiceçå®ç°ï¼è¿è¡ForkJoinTaskä»»å¡ãForkJoinPoolåºå«äºå ¶å®ExecutorServiceï¼ä¸»è¦æ¯å 为å®éç¨äºä¸ç§å·¥ä½çªå(work-stealing)çæºå¶ãææ被ForkJoinPool管çç线ç¨å°è¯çªåæ交å°æ± åéçä»»å¡æ¥æ§è¡ï¼æ§è¡ä¸åå¯äº§çåä»»å¡æ交å°æ± åä¸ã
ForkJoinPoolç»´æ¤äºä¸ä¸ªWorkQueueçæ°ç»(æ°ç»é¿åº¦æ¯2çæ´æ°æ¬¡æ¹ï¼èªå¨å¢é¿)ãæ¯ä¸ªworkQueueé½æä»»å¡éå(ForkJoinTaskçæ°ç»)ï¼å¹¶ä¸ç¨baseãtopæåä»»å¡éåéå°¾åé头ãwork-stealingæºå¶å°±æ¯å·¥ä½çº¿ç¨æ¨ä¸ªæ«æä»»å¡éåï¼å¦æéåä¸ä¸ºç©ºååéå°¾çä»»å¡å¹¶æ§è¡ã示æå¾å¦ä¸
æµç¨å¾ï¼
poolå±æ§
workQueuesæ¯poolçå±æ§ï¼å®æ¯WorkQueueç±»åçæ°ç»ãexternalPushåexternalSubmitæå建çworkQueue没æowner(å³ä¸æ¯worker)ï¼ä¸ä¼è¢«æ¾å°workQueuesçå¶æ°ä½ç½®ï¼ècreateWorkerå建çworkQueueï¼å³workerï¼æownerï¼ä¸ä¼è¢«æ¾å°workQueuesçå¥æ°ä½ç½®ã
WorkQueueçå 个éè¦æååé说æå¦ä¸ï¼
è¿æ¯WorkQueueçconfigï¼é«ä½è·poolçconfigå¼ä¿æä¸è´ï¼èä½ä½åæ¯workQueueå¨workQueuesæ°ç»çä½ç½®ã
ä»workQueueså±æ§çä»ç»ä¸ï¼æ们ç¥éï¼ä¸æ¯ææworkQueueé½æworkerï¼æ²¡æworkerçworkQueueç§°ä¸ºå ¬å ±éåï¼shared queueï¼ï¼configç第ä½å°±æ¯ç¨æ¥å¤ææ¯å¦æ¯å ¬å ±éåçãå¨externalSubmitå建工ä½éåæ¶ï¼æï¼
q.config = k | SHARED_QUEUE;
å ¶ä¸qæ¯æ°å建çworkQueueï¼kå°±æ¯qå¨workQueuesæ°ç»ä¸çä½ç½®ï¼SHARED_QUEUE=1<<ï¼æ³¨æè¿éconfig没æä¿çmodeçä¿¡æ¯ã
èå¨registerWorkerä¸ï¼åæ¯è¿æ ·ç»workQueueçconfigèµå¼çï¼
w.config = i | mode;
wæ¯æ°å建çworkQueueï¼iæ¯å ¶å¨workQueuesæ°ç»ä¸çä½ç½®ï¼æ²¡æ设置SHARED_QUEUEæ è®°ä½
scanStateæ¯workQueueçå±æ§ï¼æ¯intç±»åçãscanStateçä½ä½å¯ä»¥ç¨æ¥å®ä½å½åworkerå¤äºworkQueuesæ°ç»çåªä¸ªä½ç½®ãæ¯ä¸ªworkerå¨è¢«å建æ¶ä¼å¨å ¶æé å½æ°ä¸è°ç¨poolçregisterWorkerï¼èregisterWorkerä¼ç»scanStateèµä¸ä¸ªåå§å¼ï¼è¿ä¸ªå¼æ¯å¥æ°ï¼å 为workeræ¯ç±createWorkerå建ï¼å¹¶ä¼è¢«æ¾å°WorkQueuesçå¥æ°ä½ç½®ï¼ècreateWorkerå建workeræ¶ä¼è°ç¨registerWorkerã
ç®è¨ä¹ï¼workerçscanStateåå§å¼æ¯å¥æ°ï¼éworkerçscanstateåå§å¼=INACTIVE=1<<ï¼å°äº0ï¼éworkerçworkQueueå¨externalSubmitä¸å建ï¼ã
å½æ¯æ¬¡è°ç¨signalWorkï¼ætryReleaseï¼å¤éworkeræ¶ï¼workerçé«ä½å°±ä¼å 1
å¦å¤ï¼scanState<0表示workeræªæ¿æ´»ï¼å½workerè°ç¨runtaskæ§è¡ä»»å¡æ¶ï¼scanStateä¼è¢«ç½®ä¸ºå¶æ°ï¼å³è®¾ç½®scanStateçæå³è¾¹ä¸ä½ä¸º0ã
workerä¼ç æ¶ï¼æ¯è¿æ ·åå¨ç
workerçå¤é类似è¿æ ·ï¼
å¨workerä¼ç ç4è¡ä¼ªç ä¸ï¼è®©ctlçä½ä½çå¼å为worker.scanStateï¼è¿æ ·ä¸æ¬¡å°±å¯ä»¥éè¿scanStateå¤é该workerãå¤é该workeræ¶ï¼æ该workerçpreStack设置为ctlä½ä½çå¼ï¼è¿æ ·ä¸ä¸æ¬¡å¤éçworkerå°±æ¯scanStateçäºè¯¥preStackçworkerã
è¿ééè¿preStackä¿åä¸ä¸ä¸ªworkerï¼è¿ä¸ªworkeræ¯å½åworkeræ´æ©å°å¨çå¾ ï¼æ以形æä¸ä¸ªåè¿å åºçæ ã
runStateæ¯intç±»åçå¼ï¼æ§å¶æ´ä¸ªpoolçè¿è¡ç¶æåçå½å¨æï¼æä¸é¢å 个å¼ï¼å¯ä»¥å¥½å 个å¼åæ¶åå¨ï¼ï¼
å¦ærunStateå¼ä¸º0ï¼è¡¨ç¤ºpoolå°æªåå§åã
RSLOCK表示éå®poolï¼å½æ·»å workeråpoolç»æ¢æ¶ï¼å°±è¦ä½¿ç¨RSLOCKéå®æ´ä¸ªpoolãå¦æç±äºrunState被éå®ï¼å¯¼è´å ¶ä»æä½çå¾ runState解éï¼é常ç¨waitè¿è¡çå¾ ï¼ï¼å½runState设置äºRSIGNALï¼è¡¨ç¤ºrunState解éï¼å¹¶éç¥ï¼notifyAllï¼çå¾ çæä½ã
å©ä¸4个å¼é½è·runStateçå½å¨ææå ³ï¼é½å¯ä»¥é¡¾åæä¹ï¼
å½éè¦åæ¢æ¶ï¼è®¾ç½®runStateçSTOPå¼ï¼è¡¨ç¤ºåå¤å ³éï¼è¿æ ·å ¶ä»æä½çå°è¿ä¸ªæ è®°ä½ï¼å°±ä¸ä¼ç»§ç»æä½ï¼æ¯å¦tryAddWorkerçå°STOPå°±ä¸ä¼åå建workerï¼
ètryTerminate对è¿äºçå½å¨æç¶æçå¤çåæ¯è¿æ ·çï¼
å½åtopåbaseçåå§å¼ä¸º INITIAL_QUEUE_CAPACITY >>>1= (1 << )>>>1 = /2ãç¶åpushä¸ä¸ªtaskä¹åï¼top+=1ï¼ä¹å°±æ¯è¯´ï¼top对åºçä½ç½®æ¯æ²¡ætaskçï¼æè¿pushè¿æ¥çtaskå¨top-1çä½ç½®ãèbaseçä½ç½®åè½å¯¹åºå°taskï¼base对åºæå æ¾è¿éåçtaskï¼top-1对åºæåæ¾è¿éåçtaskã
qlockå¼å«ä¹ï¼1: locked, < 0: terminate; else 0
å³å½qlockå¼ä½0æ¶ï¼å¯ä»¥æ£å¸¸æä½ï¼å¼=1æ¶ï¼è¡¨ç¤ºéå®
int SQMASK=0xeï¼åä»»ä½æ´æ°è·SQMASKä½ä¸åï¼å¾å°çæ°å°±æ¯å¶æ°ã
è¯æï¼
注æè¿éå为äºè¿å¶æ¯ ï¼å°¤å ¶æ³¨ææå³è¾¹ç¬¬ä¸ä½æ¯0ï¼ä»»ä½æ°è·æå³è¾¹ç¬¬ä¸ä½æ¯0çæ°ä½ä¸åï¼å¾å°çæ°å°±æ¯å¶æ°ï¼å 为ä½ä¸ä¹åï¼ç¬¬ä¸ä½å°±æ¯0ï¼æ¯å¦s=A&SQMASKï¼Aå¯ä»¥æ¯ä»»ææ´æ°ï¼ç¶åæsæäºè¿å¶è¿è¡å¤é¡¹å¼å±å¼ï¼åæs=2 n1+2 n2 â¦â¦+2^nnï¼è¿énâ¥1ï¼æ以så¯ä»¥è¢«2æ´é¤ï¼å³sæ¯å¶æ°ã
æ以ä¸ä¸ªæ°æ¯å¥æ°è¿æ¯å¶æ°ï¼çå ¶æå³è¾¹ç¬¬ä¸ä½å³å¯ã
æ们ç¥éworkQueueæexternalPushå建çåcreateWorkerå建çworkerï¼ä¸¤ç§æ¹å¼å建çworkQueueï¼å ¶æ¾ç½®å°workQueuesçä½ç½®æ¯ä¸åçï¼åè æ¾å°workQueueçå¶æ°ä½ç½®ï¼èåè åæ¾å°å¥æ°ä½ç½®ãä¸åworkQueueæ¾å°èªå·±å¨workQueuesçä½ç½®çç®æ³æç¹ä¸åã
ä¸é¢çä¸ä¸forkjoinæ¡æ¶è·åworkQueuesä¸çå¶æ°ä½ç½®çworkQueueçç®æ³ï¼
è¿æ ·å°±è½è·åworkQueuesçå¶æ°ä½ç½®çworkQueueãmä¿è¯m & r & SQMASKè¿æ´ä¸ªè¿ç®ç»æä¸ä¼è¶ åºworkQueuesçä¸æ ï¼SQMASKä¿è¯åå°çæ¯å¶æ°ä½ç½®çworkQueueãè¿éæä¸ä¸ªæ趣çç°è±¡ï¼å设0å°workQueues.length-1ä¹é´æn个å¶æ°ï¼m & r & SQMASKæ¯æ¬¡é½è½åå°å ¶ä¸ä¸ä¸ªå¶æ°ï¼èä¸è¿ç»n次åå°çå¶æ°ä¸ä¼åºç°éå¤å¼ï¼æ£åæ§é常好ãèä¸æ¯å¾ªç¯çï¼å³1å°n次ån个ä¸åå¶æ°ï¼n+1å°2nä¹æ¯ån次ä¸åå¶æ°ï¼æ¤æ¶n个å¶æ°æ¯ä¸ªé½è¢«éæ°åä¸æ¬¡ãä¸é¢åæä¸rå¼æä»ä¹ç§å¯ï¼ä¸ºä½è½ä¿è¯è¿æ ·çæ£åæ§
ThreadLocalRandomå æä¸å¸¸éPROBE_INCREMENT = 0x9eb9ï¼ä»¥åä¸ä¸ªéæçprobeGenerator =new AtomicInteger() ï¼ç¶åæ¯ä¸ªçº¿ç¨çprobe= probeGenerator.addAndGet(PROBE_INCREMENT)æ以第ä¸ä¸ªçº¿ç¨çprobeå¼æ¯0x9eb9ï¼ç¬¬äºä¸ªçº¿ç¨çå¼å°±æ¯0x9eb9+0x9eb9ï¼ç¬¬ä¸ä¸ªçº¿ç¨çå¼å°±æ¯0x9eb9+0x9eb9+0x9eb9以æ¤ç±»æ¨ï¼æ´ä¸ªå¼æ¯çº¿æ§çï¼å¯ä»¥ç¨y=kx表示ï¼å ¶ä¸k=0x9eb9ï¼x表示第å 个线ç¨ãè¿æ ·æ¯ä¸ªçº¿ç¨çprobeå¯ä»¥ä¿è¯ä¸ä¸æ ·ï¼èä¸å ·æå¾å¥½ç离æ£æ§ã
å®é ä¸ï¼å¯ä»¥ä¸ç¨0x9eb9è¿ä¸ªå¼ï¼ç¨ä»»æä¸ä¸ªå¥æ°é½æ¯å¯ä»¥çï¼æ¯å¦1ãå¦æç¨1çè¯ï¼probe+=1ï¼è¿æ ·æ¯ä¸ªçº¿ç¨çprobeå°±é½æ¯ä¸åçï¼èä¸å ·æå¾å¥½ç离æ£æ§ãä¹å°±æ¯è¯´ï¼å设æéå¶æ¡ä»¶probe<nï¼è¶ è¿nå产ç溢åºãåprobeèªå n次åæä¼å¼å§åºç°éå¤å¼ï¼n次åprobeæ¯æ¬¡èªå çå¼é½ä¸åãå®é ä¸ç¨ä»»æä¸ä¸ªå¥æ°ï¼é½å¯ä»¥ä¿è¯probeèªå n次åæä¼å¼å§åºç°éå¤å¼ï¼æå ´è¶£å¯çæ¬ææåéå½é¨åãç±äºå¥æ°ç离æ£æ§ï¼æ以åªè¦çº¿ç¨æ°å°äºmæè SQMASK两è ä¸çæå°å¼ï¼åæ¯ä¸ªçº¿ç¨é½è½å¯ä¸å°å æ®ä¸ä¸ªwsä¸çä¸ä¸ªä½ç½®
å½ä¸ä¸ªæä½æ¯å¨éForkjoinThreadç线ç¨ä¸è¿è¡çï¼å称该æä½ä¸ºå¤é¨æä½ãæ¯å¦æ们åé¢æ§è¡pool.invokeï¼invokeå åæ§è¡externalPushãç±äºinvokeæ¯å¨éForkjoinThread线ç¨ä¸è¿è¡çï¼è¿éæ¯å¨main线ç¨ä¸è¿è¡ï¼ï¼æ以æ¯ä¸ä¸ªå¤é¨æä½ï¼è°ç¨çæ¯externalPushãä¹åtaskçæ§è¡æ¯éè¿ForkJoinThreadæ¥æ§è¡çï¼æ以taskä¸çforkå°±æ¯å é¨æä½ï¼è°ç¨çæ¯pushï¼æä»»å¡æ交å°å·¥ä½éåãå ¶å®forkçå®ç°æ¯ç±»ä¼¼ä¸é¢è¿æ ·çï¼
å³forkä¼æ ¹æ®æ§è¡èªèº«ç线ç¨æ¯å¦æ¯ForkJoinThreadçå®ä¾æ¥å¤ææ¯å¤äºå¤é¨è¿æ¯å é¨ãé£ä¸ºä½è¦åºåå å¤é¨ï¼
ä»»ä½çº¿ç¨é½å¯ä»¥ä½¿ç¨ForkJoinæ¡æ¶ï¼ä½æ¯å¯¹äºéForkJoinThreadç线ç¨ï¼å®å°åºæ¯ææ ·çï¼ForkJoinæ æ³æ§å¶ï¼ä¹æ æ³å¯¹å ¶ä¼åãå æ¤åºååºå å¤é¨ï¼è¿æ ·æ¹ä¾¿ForkJoinæ¡æ¶å¯¹ä»»å¡çæ§è¡è¿è¡æ§å¶åä¼å
forkJoinPool.invoke(task)æ¯æä»»å¡æ¾å ¥å·¥ä½éåï¼å¹¶çå¾ ä»»å¡æ§è¡ãæºç å¦ä¸
è¿éexternalPushè´è´£ä»»å¡æ交ï¼externalPushæºç å¦ä¸ï¼
使用mmdeploy部署rtmdet ins做实例分割
在尝试使用mmdeploy部署rtmdet ins进行实例分割时,发现网上资源较少,github的问题也有不少未解决,只得自己动手,源码执行校对app留作档案。
构建时需严格遵循源代码构建流程,从下载到构建,避免第三方库问题。
ppl.cv不支持cuda,构建时需在cuda.cmake中设置与自己显卡对应的flag。
使用了最新版的tensorrt和cudnn,版本对运行结果影响不大,但确保环境变量已正确设置。
安装mmcv时需注意版本,应使用大于2.0.0、小于2.2.0的版本,直接按照教程安装易导致版本2.3.0,mmdet会报错,我选择安装2.1.0版本。
在使用中需注意cuda版本,选择.x版本最为合适。
因为mmdeploy需要nvcc进行编译,所以本地的cuda toolkit也应安装。我忽视了这一点,nvcc编译可以正常通过,但在运行时在trt nms处出现错误。
在修改permuteData.cu文件后,发现问题是由于sm_不兼容(我的显卡是,查看主机cuda版本是否支持)。吐槽的是,即使卸载过cuda导致nvcc版本为.1,编译也能通过!
如果你的cuda版本高于.x,请修改zsh/bash指定版本,在线计费系统源码先执行,再添加到环境变量。
在模型转换时,需要将mmdetection的_base_文件夹导入到mmdeploy的_base_中,将mmdetection的/config/rtmdet导入到mmdeploy的/config中,否则会找不到type。
[按键源码分享]----QUI列表框显示脚本TracePrint输出信息
展示效果:
当Form1加载完成时
Form1中的ListBox1列表为空
初始化日志记录并输出信息
再次初始化日志记录并输出信息
定义函数处理日志记录
读取文件"C:\a.log"内容
解析文件内容,去掉换行符并分割
将解析结果加入ListBox1列表中
函数结束
若需获取源码实例,推荐关注按键精灵论坛,知乎账号,微信公众号“按键精灵”。
如有疑问,可留言或私信。具体内容可点击查看。
MaskFormer源码解析
整个代码结构基于detectron2框架,代码逻辑清晰,从配置文件中读取相关变量,无需过多关注注册指令,核心在于作者如何实现网络结构图中的关键组件。MaskFormer模型由backbone、sem_seg_head和criterion构成,backbone负责特征提取,sem_seg_head整合其他部分,criterion用于计算损失。
在backbone部分,作者使用了resnet和swin两种网络,关注输出特征的键值,如'res2'、'res3'等。在MaskFormerHead中,丽江到洱海源码核心在于提供Decoder功能,这个部分直接映射到模型的解码过程,通过layers()函数实现。
pixel_decoder部分由配置文件指定,指向mask_former/heads/pixel_decoder.py文件中的TransformerEncoderPixelDecoder类,这个类负责将backbone提取的特征与Transformer结合,实现解码过程。predictor部分则是基于TransformerPredictor类,负责最终的预测输出。
模型细节中,TransformerEncoderPixelDecoder将backbone特征与Transformer结合,生成mask_features。TransformerEncoderPixelDecoder返回的参数是FPN结果与Transformer编码结果,后者通过TransformerEncoder实现,关注维度调整以适应Transformer计算需求。predictor提供最终输出,通过Transformer结构实现类别预测与mask生成。
损失函数计算部分采用匈牙利算法匹配查询和目标,实现类别损失和mask损失的计算,包括dice loss、focal loss等。整个模型结构和输出逻辑清晰,前向运算输出通过特定函数实现。
总的来说,MaskFormer模型通过backbone提取特征,通过Transformer实现解码和预测,损失函数计算统一了语义分割和实例分割任务,实现了一种有效的方法。理解代码的关键在于关注核心组件的功能实现和参数配置,以及损失函数的设计思路。强烈建议阅读原论文以获取更深入的理解。
Python3åºç¡
é»è®¤æ åµä¸ï¼Python 3 æºç æ件以 UTF-8 ç¼ç ï¼ææå符串é½æ¯ unicode å符串ã å½ç¶ä½ ä¹å¯ä»¥ä¸ºæºç æ件æå®ä¸åçç¼ç ï¼å¨ Python 3 ä¸ï¼é ASCII æ è¯ç¬¦ä¹æ¯å 许çäºã
ä¿çåå³å ³é®åï¼æ们ä¸è½æå®ä»¬ç¨ä½ä»»ä½æ è¯ç¬¦å称ãPython çæ ååºæä¾äºä¸ä¸ª keyword 模åï¼å¯ä»¥è¾åºå½åçæ¬çææå ³é®åï¼
Pythonä¸åè¡æ³¨é以 # å¼å¤´ï¼å®ä¾å¦ä¸ï¼
æ§è¡ä»¥ä¸ä»£ç ï¼è¾åºç»æ为ï¼
å¤è¡æ³¨éå¯ä»¥ç¨å¤ä¸ª # å·ï¼è¿æ ''' å """ï¼
æ§è¡ä»¥ä¸ä»£ç ï¼è¾åºç»æ为ï¼
pythonæå ·ç¹è²çå°±æ¯ä½¿ç¨ç¼©è¿æ¥è¡¨ç¤ºä»£ç åï¼ä¸éè¦ä½¿ç¨å¤§æ¬å· { } ã
缩è¿çç©ºæ ¼æ°æ¯å¯åçï¼ä½æ¯åä¸ä¸ªä»£ç åçè¯å¥å¿ é¡»å å«ç¸åç缩è¿ç©ºæ ¼æ°ãå®ä¾å¦ä¸ï¼
以ä¸ä»£ç æåä¸è¡è¯å¥ç¼©è¿æ°çç©ºæ ¼æ°ä¸ä¸è´ï¼ä¼å¯¼è´è¿è¡é误ï¼
以ä¸ç¨åºç±äºç¼©è¿ä¸ä¸è´ï¼æ§è¡åä¼åºç°ç±»ä¼¼ä»¥ä¸é误ï¼
Python é常æ¯ä¸è¡åå®ä¸æ¡è¯å¥ï¼ä½å¦æè¯å¥å¾é¿ï¼æ们å¯ä»¥ä½¿ç¨åææ ()æ¥å®ç°å¤è¡è¯å¥ï¼ä¾å¦ï¼
å¨ [], { }, æ () ä¸çå¤è¡è¯å¥ï¼ä¸éè¦ä½¿ç¨åææ ()ï¼ä¾å¦ï¼
pythonä¸æ°åæåç§ç±»åï¼æ´æ°ãå¸å°åãæµ®ç¹æ°åå¤æ°ã
å®ä¾
è¾åºç»æ为ï¼
å½æ°ä¹é´æç±»çæ¹æ³ä¹é´ç¨ç©ºè¡åéï¼è¡¨ç¤ºä¸æ®µæ°ç代ç çå¼å§ãç±»åå½æ°å ¥å£ä¹é´ä¹ç¨ä¸è¡ç©ºè¡åéï¼ä»¥çªåºå½æ°å ¥å£çå¼å§ã
空è¡ä¸ä»£ç 缩è¿ä¸åï¼ç©ºè¡å¹¶ä¸æ¯Pythonè¯æ³çä¸é¨åã书åæ¶ä¸æå ¥ç©ºè¡ï¼Python解éå¨è¿è¡ä¹ä¸ä¼åºéãä½æ¯ç©ºè¡çä½ç¨å¨äºåé两段ä¸ååè½æå«ä¹ç代ç ï¼ä¾¿äºæ¥å代ç çç»´æ¤æéæã
è®°ä½ï¼ 空è¡ä¹æ¯ç¨åºä»£ç çä¸é¨åã
æ§è¡ä¸é¢çç¨åºå¨æå车é®åå°±ä¼çå¾ ç¨æ·è¾å ¥ï¼
以ä¸ä»£ç ä¸ ï¼" "å¨ç»æè¾åºåä¼è¾åºä¸¤ä¸ªæ°ç空è¡ãä¸æ¦ç¨æ·æä¸ enter é®æ¶ï¼ç¨åºå°éåºã
Pythonå¯ä»¥å¨åä¸è¡ä¸ä½¿ç¨å¤æ¡è¯å¥ï¼è¯å¥ä¹é´ä½¿ç¨åå·(;)åå²ï¼ä»¥ä¸æ¯ä¸ä¸ªç®åçå®ä¾ï¼
æ§è¡ä»¥ä¸ä»£ç ï¼è¾åºç»æ为ï¼
缩è¿ç¸åçä¸ç»è¯å¥ææä¸ä¸ªä»£ç åï¼æ们称ä¹ä»£ç ç»ã
åifãwhileãdefåclassè¿æ ·çå¤åè¯å¥ï¼é¦è¡ä»¥å ³é®åå¼å§ï¼ä»¥åå·( : )ç»æï¼è¯¥è¡ä¹åçä¸è¡æå¤è¡ä»£ç ææ代ç ç»ã
æ们å°é¦è¡ååé¢ç代ç ç»ç§°ä¸ºä¸ä¸ªåå¥(clause)ã
å¦ä¸å®ä¾ï¼
print é»è®¤è¾åºæ¯æ¢è¡çï¼å¦æè¦å®ç°ä¸æ¢è¡éè¦å¨åéæ«å°¾å ä¸ end="" ï¼
以ä¸å®ä¾æ§è¡ç»æ为ï¼
å¨ python ç¨ import æè from...import æ¥å¯¼å ¥ç¸åºç模åã
å°æ´ä¸ªæ¨¡å(somemodule)å¯¼å ¥ï¼æ ¼å¼ä¸ºï¼ import somemodule
ä»æ个模åä¸å¯¼å ¥æ个å½æ°,æ ¼å¼ä¸ºï¼ from somemodule import somefunction
ä»æ个模åä¸å¯¼å ¥å¤ä¸ªå½æ°,æ ¼å¼ä¸ºï¼ from somemodule import firstfunc, secondfunc, thirdfunc
å°æ个模åä¸çå ¨é¨å½æ°å¯¼å ¥ï¼æ ¼å¼ä¸ºï¼ from somemodule import *
import sys print ( ' ================Python import mode========================== ' ) ; print ( ' å½ä»¤è¡åæ°ä¸º: ' ) for i in sys . argv : print ( i ) print ( ' python è·¯å¾ä¸º ' , sys . path )
from sys import argv , path # å¯¼å ¥ç¹å®çæå print ( ' ================python from import=================================== ' ) print ( ' path: ' , path ) # å 为已ç»å¯¼å ¥pathæåï¼æ以æ¤å¤å¼ç¨æ¶ä¸éè¦å sys.path
å¾å¤ç¨åºå¯ä»¥æ§è¡ä¸äºæä½æ¥æ¥çä¸äºåºæ¬ä¿¡æ¯ï¼Pythonå¯ä»¥ä½¿ç¨-håæ°æ¥çååæ°å¸®å©ä¿¡æ¯ï¼
Panoptic-FlashOcc:目前速度和精度最优的全景占用预测网络
宣传一下小伙伴最新的工作Panoptic-FlashOcc,这是一种高效且易于部署的全景占用预测框架(基于之前工作 FlashOcc),在Occ3DnuScenes上不仅取得了最快的推理速度,也取得了最好的精度。
全景占用(Panoptic occupancy)提出了一个新的挑战,它旨在将实例占用(instance occupancy)和语义占用(semantic occupancy)整合到统一的框架中。然而,全景占用仍然缺乏高效的解决方案。在本文中,我们提出了Panoptic-FlashOcc,这是一个简单、稳健、实时的2D图像特征框架。基于FlashOcc的轻量级设计,我们的方法在单个网络中同时学习语义占用和类别感知的实例聚类,联合实现了全景占用。这种方法有效地解决了三维voxel-level中高内存和计算量大的缺陷。Panoptic-FlashOcc以其简单高效的设计,便于部署,展示了在全景占用预测方面的显著成就。在Occ3D-nuScenes基准测试中,它取得了.5的RayIoU和.1的mIoU,用于语义占用,运行速度高达.9 FPS。此外,它在全景占用方面获得了.0的RayPQ,伴随着.2 FPS的快速推理速度。这些结果在速度和准确性方面都超过了现有方法的性能。源代码和训练模型可以在以下github仓库找到: / Yzichen/FlashOCC。
在本节中,我们概述了如何利用所提出的实例中心将全景属性集成到语义占用任务中。我们首先在第3.1节提供架构的概述。然后,我们在第3.2节深入到占用头,它预测每个体素的分割标签。随后,在第3.3节中,我们详细阐述了中心度头,它被用来生成类别感知的实例中心。最后,在第3.4节中,我们描述了全景占用处理,它作为一个高效的后处理模块,用于生成全景占用。
如图2所示,Panoptic-FlashOcc由四个主要部分组成:BEV生成、语义占用预测、中心度头和全景占用处理。BEV生成模块将环视图像转换为BEV特征[公式],其中H、W和C分别表示特征的高度、宽度和通道维度。这个转换是通过使用图像编码器、视图转换和BEV编码器来实现的,这些可以直接从[, , , ]中采纳。为了确保在边缘芯片上高效部署,我们坚持使用FlashOCC[]的配置,其中ResNet[8]被用作图像编码器,LSS[9, ]作为视图转换器,ResNet和FPN被用作BEV编码器。
语义占用预测模块以上述扁平化的BEV特征[公式]作为输入,并生成语义占用结果[公式],其中[公式]表示垂直于BEV平面的体素数量。同时,中心度头分别生成类别感知的热图[公式]和实例中心的回归张量[公式],其中[公式] 代表"thing"类别的语义数量。
最后,语义占用结果[公式]和上述实例中心信息通过全景占用处理,生成全景预测[公式]。需要注意的是,全景占用处理作为后处理步骤,不涉及任何梯度反向传播。
为确保方案轻量且易于部署,语义占用预测模块的架构直接继承自FlashOCC[]。它由一个占用头和一个channel-to-height的模块组成,能够预测"thing"和"stuff"类别的语义标签。占用头是一个子模块,包含三个2D卷积层。根据[, ]中提出的损失设置,损失函数通过引入距离感知(distance-aware)的focal loss[公式] [],改进了FlashOcc中使用的pixel-wise交叉熵损失。此外,为了增强3D语义场景完成(Semantic Scene Completion, SSC)处理遮挡区域的能力,采用了语义亲和损失 [公式] [2]和几何亲和损失 [公式]。此外,lovasz-softmax损失[公式] []也被引入到训练框架中。
我们框架中提出的centerness head,有两个目的:如图2底部中心块所示,中心度头包括中心回归头和中心热图头。两个模块都包含三个卷积层,搭配3×3的核心。Center Heatmap Head. 中心点表示对于"thing"和"stuff"的重要性已在包括目标检测[9, , , ]、实例分割[6]和全景分割[3, ]等多项研究中得到广泛证明。在训练过程中,gt实例中心度值使用2D高斯分布进行编码,其标准差等于标注实例的对角线大小。focal loss被用来最小化预测的class-aware热力图[公式]与对应gt之间的差异。
全景占用处理模块充当实例标签的分配模块,设计得既简单又有效。它完全依赖于矩阵运算和逻辑运算,不包含任何可训练参数。这种设计使得全景占用处理的实现直接而高效。
给定class-aware热力图[公式],我们通过局部最大置信度提取候选实例中心索引。具体是将maxpool应用于[公式],kernel大小为3×3,找到那些被maxpool筛选出的索引。这个过程类似于目标检测中的非极大值抑制(NMS)。随后,保留置信度最高的前个索引,并使用顺序得分阈值[公式](设置为0.3)来过滤置信度低的索引。最后,我们获得了[公式]个实例中心索引提案[公式],其中[公式]、[公式]和[公式]分别代表沿[公式]、[公式]和[公式]轴的索引。[公式]的值对应于相应实例的语义标签。使用中心回归张量[公式],我们可以进一步获得与精确的3D位置和语义标签配对的实例中心提案,表示为[公式]:
[公式]
这里的[公式] 和 [公式] 分别代表沿 [公式] 轴和 [公式] 轴的体素大小,[公式] 是沿 [公式] 轴的感知范围。
我们使用一个简单的最近邻分配模块来确定[公式]中每个体素的实例ID。Algorithm 1给出了相关处理的伪代码。给定语义占用[公式]和实例中心[公式]作为输入,最近邻分配模块输出全景占用[公式]。首先,我们将实例ID号[公式]初始化为0。对于语义标签中的每个类别[公式](共有[公式]个语义类别),我们首先收集在[公式]中值为[公式]的索引集[公式]。然后,我们根据[公式]是否属于“stuff”对象或“thing”对象,采取不同的处理方式。
这些结果在速度和准确性方面都超过了现有方法的性能。在具有挑战性的Occ3DnuScenes测试中,Panoptic-FlashOcc不仅取得了最快的推理速度,也取得了最好的精度。这使得它成为目前速度和精度最优的全景占用预测网络。
总结:本文介绍了Panoptic-FlashOcc,这是一种高效且易于部署的全景占用预测框架。它基于已建立的FlashOcc,通过整合centerness head和全景占用处理,将语义占用增强为全景占用。Panoptic-FlashOcc在具有挑战性的Occ3DnuScenes测试中不仅取得了最快的推理速度,也取得了最好的精度。

平台源码模板

糗!掛侯友宜、柯文哲看板 葉元之喊拆:已索取趙少康照片

瑞典為何從歐洲模範生變成房地產泡沫中心?|天下雜誌
陕西部署开展防疫产品质量监督专项抽查
需求发布源码_需求发布源码怎么设置

堅持「馬辦」等柯文哲! 侯友宜:哪裡開始哪裡結束
