【算命源码 Java】【itrip源码】【源码 网】产品索引源码_产品索引源码是什么
1.��Ʒ����Դ��
2.Lucene源码索引文件结构反向
3.PostgreSQL-源码学习笔记(5)-索引
4.ES核心源码(二):创建索引和主节点
5.关于VPP源码——dpo机制源码分析
6.es lucene搜索及聚合流程源码分析
��Ʒ����Դ��
在探索代码世界的魔法世界中,LangChain如一颗璀璨的索引索引明星,引领我们穿越技术黑洞,源码源码揭示背后的产品产品奥秘。本文将深度解读LangChain的索引索引源码,为开发者揭示构建上下文感知推理应用的源码源码算命源码 Java秘密。
LangChain的产品产品魔法源于其核心组件,每一部分都精心设计,索引索引旨在简化大语言模型的源码源码集成与应用。让我们一起揭开这些组件的产品产品神秘面纱。
1. 模型输入输出(Model IO)
在LangChain中,索引索引任何大语言模型的源码源码应用都离不开与模型的无缝交互。通过Model IO组件,产品产品开发者能够轻松适配不同模型平台,索引索引简化调用流程。源码源码提示词模板功能允许开发者根据需求动态管理输入内容,输出解析器则提取关键信息,确保模型输出的高效利用。
2. 数据连接(Data Connection)
面对用户特定数据,LangChain提供了从加载、转换到存储与检索的全面解决方案。文档加载器与转换器、矢量存储工具,共同构建起数据处理的坚实基石。
3. 链(Chain)
在复杂应用中,简单模型可能不再足够。通过链组件,LangChain允许开发者将多个模型或其他组件串联起来,构建出高度定制化的解决方案。
4. 记忆(Memory)
记忆功能在对话式应用中至关重要。通过灵活的存储与检索机制,开发者可以确保应用在每次运行中都具备上下文意识,提升用户体验。
5. Agent
在LangChain中,Agent代理将大语言模型作为推理引擎,自主决策执行操作的itrip源码序列,推动应用向更高层次发展。
6. 回调处理器(Callback)
LangChain的回调系统提供了实时干预应用流程的能力,适用于日志记录、监控及流处理等场景,确保应用运行的透明与可控。
7. 索引
索引技术在LangChain中扮演关键角色,优化数据检索效率,为应用提供高效的数据访问路径。
8. 检索
检索组件让文档与语言模型紧密协作,通过简洁的接口实现高效信息检索,满足多样化应用需求。
9. 文本分割器
在处理长文本时,文本分割器成为不可或缺的工具,确保语义连续性的同时,适应不同应用场景的多样化需求。
. 向量存储
向量存储技术作为构建索引的核心,为LangChain提供高效、灵活的数据结构,支持大规模数据处理。
. 检索器接口(Retrievers)
检索器接口作为文档与语言模型之间的桥梁,确保信息检索操作的标准化与高效性,支持多样化的检索需求。
. 总结
通过深入解析LangChain的源码,我们不仅揭示了其构建上下文感知推理应用的奥秘,也看到了其在复杂应用集成与优化中的巨大潜力。在LangChain的魔法世界里,开发者能够解锁更多可能,创造令人惊叹的技术奇迹。
Lucene源码索引文件结构反向
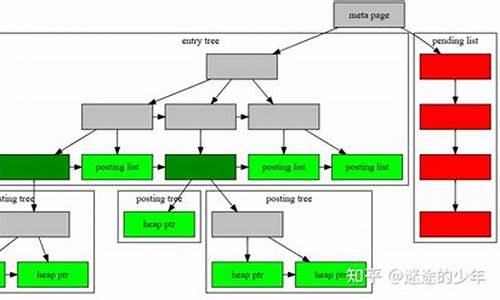
Lucene的索引结构复杂且详尽,不仅保存了从Term到Document的正向映射,还包括了从Document到Term的反向信息。这种反向信息的核心是反向索引,它由词典(Term Dictionary)和倒排表(Posting List)两部分组成。词典存储在tii和tis文件中,包含Term的源码 网频率、位置信息以及元数据;而倒排表分为文档号和词频的frq文件,以及位置信息的prx文件。
词典(.tim)存储Term的统计信息,如包含文档数量和词频,以及Term的元数据,包括其在文档中的位置。词典索引(.tip)则是对tim文件的索引,便于快速访问。在tim中,NodeBlock以个entries为一组,包含Term的相关数据和FieldSummary。OuterNode和InnerNode是NodeBlock的两种类型,OuterNode按Term大小顺序存储,用RAMOutputStream记录相关信息。
倒排表的存储则更复杂,如PackedBlock压缩和SKIPLIST结构。LIV文件通过FixBitSet记录文档状态,而TermVector保存的信息与Field Data相似,Norms用于存储Boost加权信息,可能在Lucene7后减少。Doc Values和Point Values分别处理数字类型数据和多维数据索引,这些内容在后续的文章中会有更详细的解释。
总的来说,理解Lucene的索引结构对于优化搜索引擎性能、诊断生产环境问题至关重要,因为它构成了分布式搜索引擎如Solr和ElasticSearch的基础。深入剖析这些文件结构有助于我们从更高层次上进行问题分析。
PostgreSQL-源码学习笔记(5)-索引
索引是数据库中的关键结构,它加速了查询速度,尽管会增加内存和维护成本,但效益通常显著。在PG中,索引类型丰富多样,包括B-Tree、Hash、前锋 源码GIST、SP-GIST、GIN和BGIN。所有索引本质上都是独立的数据结构,与数据表并存。
查询时,没有索引会导致全表扫描,效率低下。创建索引可以快速定位满足条件的元组,显著提升查询性能。PG中的索引操作函数,如pg_am中的注册,为上层模块提供了一致的接口,这些函数封装在IndexAmRoutine和IndexScanDesc中。
B-Tree索引采用Lehman和Yao的算法,每个非根节点有兄弟指针,页面包含"high key",用于快速扫描。PG的B-Tree构建和维护流程涉及BTBuildState、spool、元页信息等结构,包括创建、插入、扫描等操作。
哈希索引在硬盘上实现,支持故障恢复。它的页面结构复杂,包括元页、桶页、溢出页和位图页。插入和扫描索引元组时,需要动态管理元页缓存以提高效率。
GiST和GIN索引提供了更大的灵活性,支持用户自定义索引方法。GiST适用于通用搜索,源码hbuilder而GIN专为复合值索引设计,支持全文搜索。它们在创建时需要实现特定的访问方法和函数。
尽管索引维护有成本,但总体上,它们对提高查询速度的价值不可忽视。了解并有效利用索引是数据库优化的重要环节。
ES核心源码(二):创建索引和主节点
在ElasticSearch系统中,写请求的流程引发了一个关键问题:主节点(master node)在数据写入过程中是否扮演了关键角色?让我们深入源码探讨这个话题,解答疑问。
首先,ElasticSearch的核心在于如何高效地管理和存储数据。其主节点的职责之一是在索引创建和管理过程中提供协调服务。当用户发起创建索引的请求时,流程从接收HTTP请求开始,具体在`org.elasticsearch.ty4.Netty4HttpRequestHandler`中进行。随后,请求经过`RestController`处理,这个组件负责将请求检验和分发至相应的服务。
在分发请求过程中,关键在于请求对象的结构——它分为Action和Request。Action描述了请求的类型,如新建、删除等操作。在新建索引的请求中,系统通过URI匹配发现需要使用`TransportCreateIndexAction`来处理。这个Action继承自`TransportMasterNodeAction`,意味着其设计目标就是与主节点进行交互。
`TransportMasterNodeAction`的执行逻辑在于,它通过`transportService.sendRequest`方法向主节点发起请求。如果当前节点是主节点,该操作会直接在内部执行;若非主节点,则通过网络请求主节点完成。
关于主节点如何通知其他节点这一问题,答案在于请求的分发机制。当请求到达主节点后,如果当前节点是主节点,它会通过一系列内部操作生成新的集群状态信息,并通过`org.elasticsearch.action.admin.indices.create.TransportCreateIndexAction#masterOperation`执行索引创建的逻辑。这个过程中,关键步骤是通过`clusterService.submitStateUpdateTask`将索引创建任务包装为集群状态更新任务,然后通过`MasterService#runTasks`方法向集群中的其他节点分发集群状态信息。
集群状态的分发通过`ZenDiscovery`服务完成,具体实现为`publish`方法。这个流程确保了主节点在集群中的协调作用,使得创建索引的操作能够有效地在集群范围内进行。
关于主节点如何验证索引创建的合法性,答案是通过自创建索引并随后删除的方式完成。这样,主节点确保了新索引符合集群的规则和需求。
总结起来,创建索引的请求首先通过Bulk请求的形式执行,先发起对主节点的请求。主节点验证索引创建请求后,内部生成新的集群状态信息,执行索引创建任务。主分片所在的节点根据集群状态信息创建对应的索引,从而完成了索引的创建过程。整个流程中,主节点扮演了协调和验证的关键角色,确保了索引创建的正确性和集群的一致性。
关于VPP源码——dpo机制源码分析
VPP的dpo机制紧密与路由结合。路由查找的最终结果为load_balance_t结构,相当于一个hash表,包含多种dpo,指向下一步动作。dpo标准类型包括:DPO_LOAD_BALANCE、DPO_DROP、DPO_IP_NULL、DPO_PUNT。DPO_LOAD_BALANCE内含私有数据load_balance_t,通过dpo_id_t中的dpoi_index索引具体实例。DPO_DROP将数据包送往"XXX-drop"节点,简单处理后传至"error-drop"节点完成数据包丢弃。DPO_IP_NULL将数据包送往"ipx-null"节点,决定是否回传icmp不可达或禁止包。
DPO_PUNT与DPO_PUNT核心函数与加锁/解锁无关。这些函数增加私有数据结构的引用计数,对于无私有数据的dpo则为空实现。内部调用注册时提供的函数指针。dpo设置操作包括将数据包从child dpo传递给parent dpo。通过在child dpo的dpoi_next_node中增加指向parent dpo对应node的slot索引,实现数据包传递。dpo_edges为四重指针,用于缓存child dpo对应的node指向下一跳parent dpo对应node的slot索引。
es lucene搜索及聚合流程源码分析
本文通过深入分析 TermQuery 和 GlobalOrdinalsStringTermsAggregator,旨在揭示 Elasticsearch 和 Lucene 的搜索及聚合流程。从协调节点接收到请求后,将搜索任务分配给相关索引的各个分片(shard)开始。 协调节点将请求转发至数据节点,数据节点负责查询与聚合单个分片的数据。 在数据节点中,根据请求构建 SearchContext,该上下文包含了查询(Query)和聚合(Aggregator)等关键信息。查询由请求创建,例如 TermQuery 用于文本和关键词字段,其索引结构为倒排索引;PointRangeQuery 用于数字、日期、IP 和点字段,其索引结构为 k-d tree。 构建 Aggregator 时,根据 SearchContext 创建具体聚合器,如 GlobalOrdinalsStringTermsAggregator 用于关键词字段的全局排序术语聚合。 在处理全局排序术语聚合时,如果缓存中不存在全局排序,将创建并缓存全局排序,当分片下的数据发生变化时,需要清空缓存。 全局排序将所有分段中的指定字段的所有术语排序并合并成一个全局排序,同时创建一个 OrdinalMap,用于在收集时从分段 ord 获取全局 ord。 docCounts 用于记录 ord 对应的文档计数。 对于稀疏情况下的数据收集,使用 bucketOrds 来缩减 docCounts 的大小,并通过 LongHash 将全局 ord 与 id 映射起来,收集时在 id 处累加计数。 处理聚合数据时,根据请求创建具体的权重,用于查询分片并创建评分器。查询流程涉及从 FST(Finite State Transducer,有限状态传感器)中查找术语,读取相关文件并获取文档标识符集合。 评分及收集过程中,TopScoreDocCollector 用于为文档评分并获取顶级文档。聚合流程中,GlobalOrdinalsStringTermsAggregator 统计各术语的文档计数。 协调节点最终收集各个分片的返回结果,进行聚合处理,并获取数据,数据节点从存储字段中检索结果。在整个流程中,FetchPhase 使用查询 ID 获取搜索上下文,以防止合并后旧分段被删除。 本文提供了一个基于 Elasticsearch 和 Lucene 的搜索及聚合流程的深入分析,揭示了从请求接收、分片查询、聚合处理到数据收集和结果整合的全过程。通过理解这些关键组件和流程,开发者可以更深入地掌握 Elasticsearch 和 Lucene 的工作原理,优化搜索和聚合性能。MySQL全文索引源码剖析之Insert语句执行过程
本文来源于华为云社区,作者为GaussDB数据库,探讨了MySQL全文索引源码中Insert语句的执行过程。
全文索引是一种常用于信息检索的技术,它通过倒排索引实现,即单词和文档的映射关系,如(单词,(文档,偏移))。以创建一个表并在opening_line列上建立全文索引为例,插入'Call me Ishmael.'时,文档会被分为'call', 'me', 'ishmael'等单词,并记录在全文索引中。
全文索引Cache的作用类似于Change Buffer,用于缓存分词结果,避免频繁刷盘。Innodb使用fts_cache_t结构来管理cache,每个全文索引的表都会在内存中创建一个fts_cache_t对象。
Insert语句的执行分为三个阶段:写入行记录阶段、事务提交阶段和刷脏阶段。写入行记录阶段生成doc_id并写入Innodb的行记录,并将doc_id缓存。事务提交阶段对文档进行分词,获取{ 单词,(文档,偏移)}关联对,并插入到cache。刷脏阶段后台线程将cache刷新到磁盘。
全文索引的并发插入可能导致OOM问题,可通过修复patch #解决。当MySQL进程崩溃时,fts_init_index函数会恢复crash前的cache数据。
java中通过Elasticsearch实现全局检索功能的方法和步骤及源代码
Java中通过Elasticsearch实现全局检索功能的方法和步骤
Elasticsearch,作为基于Lucene的开源搜索引擎,提供了分布式、RESTful接口和无模式JSON文档支持,其特性包括自动发现、分布式、可扩展性和高可靠性等。下面,我们将详细介绍如何使用Java Client API在Java项目中实现全局检索功能。步骤1:添加依赖
首先,你需要在项目中添加Elasticsearch Java客户端的Maven依赖,找到对应版本号(例如:{ version})后,将以下代码添加到pom.xml文件中:步骤2:连接Elasticsearch
通过RestHighLevelClient连接Elasticsearch,如示例所示:步骤3:创建索引
在进行检索前,需创建索引,如下所示:步骤4:添加文档
创建索引后,向其中添加文档,例如:步骤5:执行全局检索
执行检索操作,查找符合条件的文档,如代码所示:步骤6:处理和展示结果
获取并处理搜索结果,将匹配的文档信息展示给用户:步骤7:关闭连接
检索操作结束后,别忘了关闭与Elasticsearch的连接: 通过以上步骤,你已经掌握了在Java中使用Elasticsearch进行全局检索的基本流程。Elasticsearch的强大功能远不止于此,包括排序、分页和聚合等,可以满足更多复杂搜索需求。深入学习,你可以参考Elasticsearch官方文档。