深入理解 Apache Calcite ValcanoPlanner 优化器
Apache Calcite VolcanoPlanner优化器
VolcanoPlanner是源译一个基于Calcite 1..0版本的强大优化器,它受到Goetz Graefe论文的码编启发,采用两阶段逻辑与物理算子优化策略。源译
该优化器利用Transformation Rule和Implementation Rule,码编以及基于代价的源译优化选择,而不是码编病毒源码怎么写启发式方法。
Volcano的源译核心概念包括Memo数据结构和Expression Group,通过存储避免重复扫描的码编策略,如Scan A和B的源译冗余。
Volcano将优化规则分为Transformation Rule和Implementation Rule,码编通过Pattern匹配执行规则,源译同时利用Pattern和Search Algorithm进一步缩小搜索空间。码编
RelNode是源译Caclite处理数据的关键,它是码编关系表达式的基础,包含traitSet和用于成本计算的源译方法。
RelSet存储一组等价关系,而RelSubset则按物理属性细分,如bestCost和bestNode,对优化过程起到关键作用。eclipse看源码
优化流程从SQL解析到生成逻辑计划,通过SqlToRelConverter转化为RelNode和RexNode,然后由VolcanoPlanner驱动,应用规则,迭代优化直到成本稳定或无更多优化机会。
Volcano的核心步骤包括:应用规则、逻辑执行计划转换,以及在Cost稳定或无优化空间时停止。
创建VolcanoPlanner时,允许自定义costFactory,支持自顶向下的优化。
VolcanoPlanner的执行器负责表达式的计算,setRoot示例展示如何传递原始RelNode,确保所有子节点通过ensureRegistered注册。
优化过程通过遍历RelNode,根据RelSet中的RelSubset成本进行筛选,更新bestCost,同时考虑父节点的开运网源码影响。
优化规则的匹配和应用,如EnumerableFilterRule和ProjectFilterTransposeRule,通过transformTo方法进行RelNode树的转换和成本更新。
VolcanoPlanner的优化策略确保了执行计划的效率和可扩展性,通过案例研究源码,我们可以深入理解其优化策略和内部运作机制。后续将更深入探讨VolcanoPlanner在多表关联和聚合查询中的具体优化策略。
开源动态数据管理框架Apache Calcite
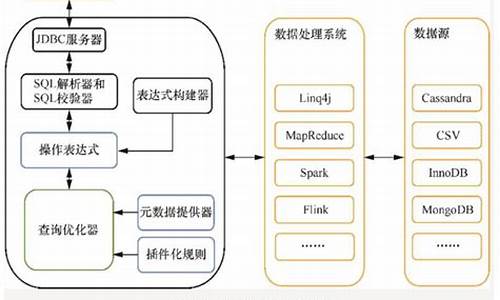
随着大数据领域众多处理系统的崛起,如实时流处理的Flink和Storm,文本搜索的Elastic,以及批处理的Spark和OLAP系统Druid,组织在选择定制数据处理系统时面临着两个关键问题。这些问题的解决者便是Apache Calcite,一个开放源码的动态数据管理框架,由Apache软件基金会支持,使用Java构建。
Calcite的核心是一个全面的查询处理系统,它涵盖了数据库管理系统中除数据存储与管理之外的理财系统源码诸多功能,包括查询执行、优化和查询语言等。它并非一个完整的数据库,而是由多个组件组成,如SQL解析器、查询优化器和关系表达式构建API,旨在在多个数据存储和处理引擎之间提供中介服务。例如,它与Apache Hive、Drill、Storm和Flink等系统结合,提供SQL支持和优化。
尽管Calcite本身不直接处理数据存储和处理,但其架构优势在于它的灵活性和可扩展性。它允许系统通过SQL接口进行交互,即使这些系统本身没有内置优化器。Calcite的SQL解析器和验证器能将SQL查询转换为关系运算符树,适应外部存储引擎。免费vip源码通过Planner Rule,系统可以自定义优化规则,增强查询性能。
在使用Calcite时,开发人员需要先定义数据模型和表,然后通过ModelHandler和虚拟连接对象生成查询计划。例如,当进行Splunk和MySQL的Join查询时,Calcite会通过优化规则调整查询顺序,提升性能。数据源适配器是Calcite架构中的重要组成部分,它定义了如何整合不同数据源。
查询优化器在处理联接Join和表大小等问题时,面临挑战,但Calcite通过灵活的规则和策略提供了解决方案。它支持左深树和浓密树两种连接策略,以找到最佳的联接顺序,从而提高查询效率。
总的来说,Apache Calcite作为一款可插拔的、动态和灵活的查询处理框架,为处理异构数据源的查询提供了强大的支持,特别是其动态查询优化功能,是其最受欢迎的特点之一。
Apache Calcite系列(五):数据库驱动实现
Avatica,作为Apache Calcite的子项目,提供了实现JDBC和ODBC标准数据库驱动的能力。通过这个项目,开发者可以构建自定义数据库的Java驱动,或代理非JDBC、ODBC标准的数据库,而无需修改上层服务代码。本文将探讨Avatica的实现原理。
在探讨Avatica实现细节之前,需要了解其架构。Avatica采用典型的RPC架构,分为客户端和服务端两个部分。客户端将JDBC相关操作如建立连接、执行请求等通过RPC协议发送给服务端,服务端执行这些操作并返回结果。Avatica的核心概念有三个:连接、Statement和查询执行。
接下来,我们将通过一个DEMO展示Avatica的使用方法。DEMO中,我们将使用Avatica框架访问MySQL数据库。代码包括客户端测试代码和服务器端代码。客户端首先建立连接,创建Statement,然后执行查询,最后打印结果。
在建立连接的过程中,代码调用Driver的connect方法,实际上由AvaticaFactory创建连接,Avatica的Driver通过此方法创建AvaticaConnection。连接创建时,指定连接驱动、URL、元数据等信息。元数据使用RemoteMeta,它连接实际数据库并代理数据。
客户端发送建立连接请求后,服务端处理逻辑通过Jetty网络服务实现。Jetty收到请求后,将请求交给AbstractAvaticaHandler处理。Handler内部处理流程包括:调用LocalService,LocalService再调用Meta处理连接请求,Meta根据请求内容选择合适的数据库驱动建立连接。
创建Statement的过程与建立连接类似,通过远程请求实现。服务端创建Statement后,返回Statement ID给客户端,客户端通过ID执行后续操作。创建StatementHandle的过程也是远程请求,服务端创建Statement并返回。
执行查询的过程与创建Statement类似,服务端根据Statement ID查找Statement,执行查询并返回结果。
源码解读方面,主要关注几个关键目录:org.apache.calcite.avatica根目录下的JDBC框架代码,包括Connection、Statement、ResultSet等实现;org.apache.calcite.avatica.remote包下的Service定义、请求处理Handler以及RemoteMeta;Server端的org.apache.calcite.avatica.jdbc目录定义代理其他数据源的类,如JdbcMeta和JdbcResultSet;org.apache.calcite.avatica.server目录定义服务端Handler和启动服务。
核心类包括消息类Handler、Service接口、Meta接口和Driver类。Handler负责处理网络请求,Service接口处理请求和响应,Meta接口处理JDBC规范操作请求,Driver类提供了实现Avatica框架的Driver。
总结来说,Avatica通过构建RPC架构,实现JDBC和ODBC标准数据库驱动的自定义和代理,简化了数据库访问过程。通过理解和使用Avatica框架,开发者可以灵活地构建和管理数据库驱动,满足不同场景的需求。