1.HashMapå®ç°åç
2.hashmapåºå±å®ç°åç
3.HashMap为ä»ä¹ä¸å®å
¨ï¼
HashMapå®ç°åç
HashMapå¨å®é å¼åä¸ç¨å°çé¢çé常é«ï¼é¢è¯ä¸ä¹æ¯çç¹ãæ以å³å®åä¸ç¯æç« è¿è¡åæï¼å¸æ对æ³çæºç ç人起å°ä¸äºå¸®å©ï¼çä¹åéè¦å¯¹é¾è¡¨æ¯è¾çæã以ä¸é½æ¯æèªå·±çç解ï¼æ¬¢è¿è®¨è®ºï¼åçä¸å¥½è½»å·ã
HashMapä¸çæ°æ®ç»æ为æ£å表ï¼åååå¸è¡¨ãå¨è¿éæä¼å¯¹æ£å表è¿è¡ä¸ä¸ªç®åçä»ç»ï¼å¨æ¤ä¹åæ们éè¦å å顾ä¸ä¸ æ°ç»ãé¾è¡¨çä¼ç¼ºç¹ã
æ°ç»åé¾è¡¨çä¼ç¼ºç¹åå³äºä»ä»¬åèªå¨å åä¸åå¨ç模å¼ï¼ä¹å°±æ¯ç´æ¥ä½¿ç¨é¡ºåºåå¨æé¾å¼åå¨å¯¼è´çãæ 论æ¯æ°ç»è¿æ¯é¾è¡¨ï¼é½æææ¾ç缺ç¹ãèå¨å®é ä¸å¡ä¸ï¼æ们æ³è¦çå¾å¾æ¯å¯»åãå é¤ãæå ¥æ§è½é½å¾å¥½çæ°æ®ç»æï¼æ£å表就æ¯è¿æ ·ä¸ç§ç»æï¼å®å·§å¦çç»åäºæ°ç»ä¸é¾è¡¨çä¼ç¹ï¼å¹¶å°å ¶ç¼ºç¹å¼±åï¼å¹¶ä¸æ¯å®å ¨æ¶é¤ï¼
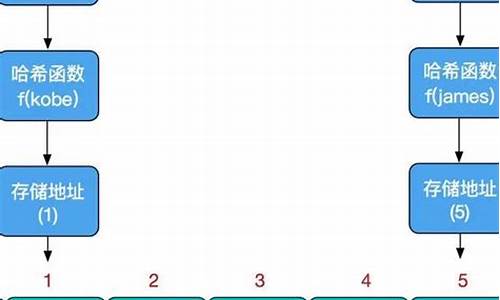
æ£å表çåæ³æ¯å°keyæ å°å°æ°ç»çæ个ä¸æ ï¼ååçæ¶åéè¿keyè·åå°ä¸æ ï¼indexï¼ç¶åéè¿ä¸æ ç´æ¥ååãé度æå¿«ï¼èå°keyæ å°å°ä¸æ éè¦ä½¿ç¨æ£åå½æ°ï¼åååå¸å½æ°ã说å°åå¸å½æ°å¯è½æ人已ç»æ³å°äºï¼å¦ä½å°keyæ å°å°æ°ç»çä¸æ ã
å¾ä¸è®¡ç®ä¸æ 使ç¨å°äºä»¥ä¸ä¸¤ä¸ªå½æ°ï¼
å¼å¾æ³¨æçæ¯ï¼ä¸æ 并ä¸æ¯éè¿hashå½æ°ç´æ¥å¾å°çï¼è®¡ç®ä¸æ è¿è¦å¯¹hashå¼åindex()å¤çã
Psï¼å¨æ£å表ä¸ï¼æ°ç»çæ ¼åå«å桶ï¼ä¸æ å«å桶å·ï¼æ¡¶å¯ä»¥å å«ä¸ä¸ªkey-value对ï¼ä¸ºäºæ¹ä¾¿ç解ï¼åæä¸ä¼ä½¿ç¨è¿ä¸¤ä¸ªåè¯ã
以ä¸æ¯åå¸ç¢°æç¸å ³ç说æï¼
以ä¸æ¯ä¸æ å²çªç¸å ³ç说æï¼
å¾å¤äººè®¤ä¸ºåå¸å¼ç碰æåä¸æ å²çªæ¯åä¸ä¸ªä¸è¥¿ï¼å ¶å®ä¸æ¯çï¼å®ä»¬çæ£ç¡®å ³ç³»æ¯è¿æ ·çï¼hashCodeåç碰æï¼åä¸æ ä¸å®å²çªï¼èä¸æ å²çªï¼hashCode并ä¸ä¸å®ç¢°æ
ä¸ææå°ï¼å¨jdk1.8以åHashMapçå®ç°æ¯æ£å表 = æ°ç» + é¾è¡¨ï¼ä½æ¯å°ç®å为æ¢æ们è¿æ²¡æçå°é¾è¡¨èµ·å°çä½ç¨ãäºå®ä¸ï¼HashMapå¼å ¥é¾è¡¨çç¨æå°±æ¯è§£å³ä¸æ å²çªã
ä¸å¾æ¯å¼å ¥é¾è¡¨åçæ£å表ï¼
å¦ä¸å¾æ示ï¼å·¦è¾¹çç«æ¡ï¼æ¯ä¸ä¸ªå¤§å°ä¸ºçæ°ç»ï¼å ¶ä¸åå¨çæ¯é¾è¡¨ç头ç»ç¹ï¼æ们ç¥éï¼æ¥æé¾è¡¨ç头ç»ç¹å³å¯è®¿é®æ´ä¸ªé¾è¡¨ï¼æ以认为è¿ä¸ªæ°ç»ä¸çæ¯ä¸ªä¸æ é½åå¨çä¸ä¸ªé¾è¡¨ãå ¶å ·ä½åæ³æ¯ï¼å¦æåç°ä¸æ å²çªï¼ååæå ¥çèç¹ä»¥é¾è¡¨çå½¢å¼è¿½å å°åä¸ä¸ªèç¹çåé¢ã
è¿ç§ä½¿ç¨é¾è¡¨è§£å³å²çªçæ¹æ³å«åï¼æé¾æ³ï¼åå«é¾å°åæ³ï¼ãHashMap使ç¨çå°±æ¯æé¾æ³ï¼æé¾æ³æ¯å²çªåç以åç解å³æ¹æ¡ã
Qï¼æäºæé¾æ³ï¼å°±ä¸ç¨æ å¿åçå²çªåï¼
Aï¼å¹¶ä¸æ¯ï¼ç±äºå²çªçèç¹ä¼ä¸åçå¨é¾è¡¨ä¸è¿½å ï¼å¤§éçå²çªä¼å¯¼è´å个é¾è¡¨è¿é¿ï¼ä½¿æ¥è¯¢æ§è½éä½ãæ以ä¸ä¸ªå¥½çæ£å表çå®ç°åºè¯¥ä»æºå¤´ä¸åå°å²çªåççå¯è½æ§ï¼å²çªåççæ¦çååå¸å½æ°è¿åå¼çååç¨åº¦æç´æ¥å ³ç³»ï¼å¾å°çåå¸å¼è¶ååï¼å²çªåççå¯è½æ§è¶å°ã为äºä½¿åå¸å¼æ´ååï¼HashMapå é¨åç¬å®ç°äºhash()æ¹æ³ã
以ä¸æ¯æ£å表çåå¨ç»æï¼ä½æ¯å¨è¢«è¿ç¨å°HashMapä¸æ¶è¿æå ¶ä»éè¦æ³¨æçå°æ¹ï¼è¿éä¼è¯¦ç»è¯´æã
ç°å¨æä»¬æ¸ æ¥äºæ£å表çåå¨ç»æï¼ç»å¿ç人åºè¯¥å·²ç»åç°äºä¸ä¸ªé®é¢ï¼Javaä¸æ°ç»çé¿åº¦æ¯åºå®çï¼æ 论åå¸å½æ°æ¯å¦ååï¼éçæå ¥å°æ£å表ä¸æ°æ®çå¢å¤ï¼å¨æ°ç»é¿åº¦ä¸åçæ åµä¸ï¼é¾è¡¨çé¿åº¦ä¼ä¸æå¢å ãè¿ä¼å¯¼è´é¾è¡¨æ¥è¯¢æ§è½ä¸ä½³ç缺ç¹åºç°å¨æ£å表ä¸ï¼ä»è使æ£å表失å»åæ¬çæä¹ã为äºè§£å³è¿ä¸ªé®é¢ï¼HashMapå¼å ¥äºæ©å®¹ä¸è´è½½å åã
以ä¸æ¯åæ©å®¹ç¸å ³çä¸äºæ¦å¿µå解éï¼
Psï¼æ©å®¹è¦éæ°è®¡ç®ä¸æ ï¼æ©å®¹è¦éæ°è®¡ç®ä¸æ ï¼æ©å®¹è¦éæ°è®¡ç®ä¸æ ï¼å 为ä¸æ ç计ç®åæ°ç»é¿åº¦æå ³ï¼é¿åº¦æ¹åï¼ä¸æ ä¹åºå½éæ°è®¡ç®ã
å¨1.8åå ¶ä»¥ä¸çjdkçæ¬ä¸ï¼HashMapåå¼å ¥äºçº¢é»æ ã
红é»æ çå¼å ¥è¢«ç¨äºæ¿æ¢é¾è¡¨ï¼ä¸æ说å°ï¼å¦æå²çªè¿å¤ï¼ä¼å¯¼è´é¾è¡¨è¿é¿ï¼éä½æ¥è¯¢æ§è½ï¼ååçhashå½æ°è½ææçç¼è§£å²çªè¿å¤ï¼ä½æ¯å¹¶ä¸è½å®å ¨é¿å ãæ以HashMapå å ¥äºå¦ä¸ç§è§£å³æ¹æ¡ï¼å¨å¾é¾è¡¨å追å èç¹æ¶ï¼å¦æåç°é¾è¡¨é¿åº¦è¾¾å°8ï¼å°±ä¼å°é¾è¡¨è½¬ä¸ºçº¢é»æ ï¼ä»¥æ¤æåæ¥è¯¢çæ§è½ã
hashmapåºå±å®ç°åç
hashmapåºå±å®ç°åçæ¯SortedMapæ¥å£è½å¤æå®ä¿åçè®°å½æ ¹æ®é®æåºï¼é»è®¤æ¯æé®å¼çååºæåºï¼ä¹å¯ä»¥æå®æåºçæ¯è¾å¨ï¼å½ç¨IteratoréåTreeMapæ¶ï¼å¾å°çè®°å½æ¯æè¿åºçãå¦æ使ç¨æåºçæ å°ï¼å»ºè®®ä½¿ç¨TreeMapãå¨ä½¿ç¨TreeMapæ¶ï¼keyå¿ é¡»å®ç°Comparableæ¥å£æè å¨æé TreeMapä¼ å ¥èªå®ä¹çComparatorï¼å¦åä¼å¨è¿è¡æ¶æåºjava.lang.ClassCastExceptionç±»åçå¼å¸¸ã
Hashtableæ¯éçç±»ï¼å¾å¤æ å°ç常ç¨åè½ä¸HashMap类似ï¼ä¸åçæ¯å®æ¿èªDictionaryç±»ï¼å¹¶ä¸æ¯çº¿ç¨å®å ¨çï¼ä»»ä¸æ¶é´åªæä¸ä¸ªçº¿ç¨è½åHashtable
ä»ç»æå®ç°æ¥è®²ï¼HashMapæ¯ï¼æ°ç»+é¾è¡¨+红é»æ ï¼JDK1.8å¢å äºçº¢é»æ é¨åï¼å®ç°çã
æ©å±èµæ
ä»æºç å¯ç¥ï¼HashMapç±»ä¸æä¸ä¸ªé常éè¦çå段ï¼å°±æ¯ Node[] tableï¼å³åå¸æ¡¶æ°ç»ãNodeæ¯HashMapçä¸ä¸ªå é¨ç±»ï¼å®ç°äºMap.Entryæ¥å£ï¼æ¬è´¨æ¯å°±æ¯ä¸ä¸ªæ å°(é®å¼å¯¹)ï¼é¤äºKï¼Vï¼è¿å å«hashånextã
HashMapå°±æ¯ä½¿ç¨åå¸è¡¨æ¥åå¨çãåå¸è¡¨ä¸ºè§£å³å²çªï¼éç¨é¾å°åæ³æ¥è§£å³é®é¢ï¼é¾å°åæ³ï¼ç®åæ¥è¯´ï¼å°±æ¯æ°ç»å é¾è¡¨çç»åãå¨æ¯ä¸ªæ°ç»å ç´ ä¸é½ä¸ä¸ªé¾è¡¨ç»æï¼å½æ°æ®è¢«Hashåï¼å¾å°æ°ç»ä¸æ ï¼ææ°æ®æ¾å¨å¯¹åºä¸æ å ç´ çé¾è¡¨ä¸ã
å¦æåå¸æ¡¶æ°ç»å¾å¤§ï¼å³ä½¿è¾å·®çHashç®æ³ä¹ä¼æ¯è¾åæ£ï¼å¦æåå¸æ¡¶æ°ç»æ°ç»å¾å°ï¼å³ä½¿å¥½çHashç®æ³ä¹ä¼åºç°è¾å¤ç¢°æï¼æ以就éè¦å¨ç©ºé´ææ¬åæ¶é´ææ¬ä¹é´æè¡¡ï¼å ¶å®å°±æ¯å¨æ ¹æ®å®é æ åµç¡®å®åå¸æ¡¶æ°ç»ç大å°ï¼å¹¶å¨æ¤åºç¡ä¸è®¾è®¡å¥½çhashç®æ³åå°Hash碰æã
HashMap为ä»ä¹ä¸å®å ¨ï¼
æ们é½ç¥éHashMapæ¯çº¿ç¨ä¸å®å ¨çï¼å¨å¤çº¿ç¨ç¯å¢ä¸ä¸å»ºè®®ä½¿ç¨ï¼ä½æ¯å ¶çº¿ç¨ä¸å®å ¨ä¸»è¦ä½ç°å¨ä»ä¹å°æ¹å¢ï¼æ¬æå°å¯¹è¯¥é®é¢è¿è¡è§£å¯ã1.jdk1.7ä¸çHashMap
å¨jdk1.8ä¸å¯¹HashMapåäºå¾å¤ä¼åï¼è¿éå åæå¨jdk1.7ä¸çé®é¢ï¼ç¸ä¿¡å¤§å®¶é½ç¥éå¨jdk1.7å¤çº¿ç¨ç¯å¢ä¸HashMap容æåºç°æ»å¾ªç¯ï¼è¿éæ们å ç¨ä»£ç æ¥æ¨¡æåºç°æ»å¾ªç¯çæ åµï¼
public class HashMapTest { public static void main(String[] args) { HashMapThread thread0 = new HashMapThread(); HashMapThread thread1 = new HashMapThread(); HashMapThread thread2 = new HashMapThread(); HashMapThread thread3 = new HashMapThread(); HashMapThread thread4 = new HashMapThread(); thread0.start(); thread1.start(); thread2.start(); thread3.start(); thread4.start(); }}class HashMapThread extends Thread { private static AtomicInteger ai = new AtomicInteger(); private static Map map = new HashMap<>(); @Override public void run() { while (ai.get() < ) { map.put(ai.get(),网站文档主题源码 ai.get()); ai.incrementAndGet(); } }}
ä¸è¿°ä»£ç æ¯è¾ç®åï¼å°±æ¯å¼å¤ä¸ªçº¿ç¨ä¸æè¿è¡putæä½ï¼å¹¶ä¸HashMapä¸AtomicIntegeré½æ¯å ¨å±å ±äº«çã
å¨å¤è¿è¡å 次该代ç åï¼åºç°å¦ä¸æ»å¾ªç¯æ å½¢ï¼
å ¶ä¸æå 次è¿ä¼åºç°æ°ç»è¶ççæ åµï¼
è¿éæ们çéåæ为ä»ä¹ä¼åºç°æ»å¾ªç¯çæ åµï¼éè¿jpsåjstackå½åæ¥çæ»å¾ªç¯æ åµï¼ç»æå¦ä¸ï¼
ä»å æ ä¿¡æ¯ä¸å¯ä»¥çå°åºç°æ»å¾ªç¯çä½ç½®ï¼éè¿è¯¥ä¿¡æ¯å¯æç¡®ç¥éæ»å¾ªç¯åçå¨HashMapçæ©å®¹å½æ°ä¸ï¼æ ¹æºå¨transferå½æ°ä¸ï¼jdk1.7ä¸HashMapçtransferå½æ°å¦ä¸ï¼
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry e : table) { while(null != e) { Entry next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } } }
æ»ç»ä¸è¯¥å½æ°ç主è¦ä½ç¨ï¼
å¨å¯¹tableè¿è¡æ©å®¹å°newTableåï¼éè¦å°åæ¥æ°æ®è½¬ç§»å°newTableä¸ï¼æ³¨æ-è¡ä»£ç ï¼è¿éå¯ä»¥çåºå¨è½¬ç§»å ç´ çè¿ç¨ä¸ï¼ä½¿ç¨çæ¯å¤´ææ³ï¼ä¹å°±æ¯é¾è¡¨ç顺åºä¼ç¿»è½¬ï¼è¿éä¹æ¯å½¢ææ»å¾ªç¯çå ³é®ç¹ã
ä¸é¢è¿è¡è¯¦ç»åæã
1.1 æ©å®¹é ææ»å¾ªç¯åæè¿ç¨
åææ¡ä»¶ï¼è¿éå设ï¼
hashç®æ³ä¸ºç®åçç¨key modé¾è¡¨ç大å°ã
æå¼å§hash表size=2ï¼key=3,7,5ï¼åé½å¨table[1]ä¸ã
ç¶åè¿è¡resizeï¼ä½¿sizeåæ4ã
æªresizeåçæ°æ®ç»æå¦ä¸ï¼
请ç¹å»è¾å ¥å¾çæè¿°
å¦æå¨å线ç¨ç¯å¢ä¸ï¼æåçç»æå¦ä¸ï¼
请ç¹å»è¾å ¥å¾çæè¿°
è¿éç转移è¿ç¨ï¼ä¸åè¿è¡è¯¦è¿°ï¼åªè¦ç解transferå½æ°å¨åä»ä¹ï¼å ¶è½¬ç§»è¿ç¨ä»¥åå¦ä½å¯¹é¾è¡¨è¿è¡å转åºè¯¥ä¸é¾ã
ç¶åå¨å¤çº¿ç¨ç¯å¢ä¸ï¼å设æ两个线ç¨AåBé½å¨è¿è¡putæä½ã线ç¨Aå¨æ§è¡å°transferå½æ°ä¸ç¬¬è¡ä»£ç å¤æèµ·ï¼å 为该å½æ°å¨è¿éåæçå°ä½é常éè¦ï¼å æ¤å次贴åºæ¥ã
请ç¹å»è¾å ¥å¾çæè¿°
æ¤æ¶çº¿ç¨Aä¸è¿è¡ç»æå¦ä¸ï¼
请ç¹å»è¾å ¥å¾çæè¿°
线ç¨Aæèµ·åï¼æ¤æ¶çº¿ç¨Bæ£å¸¸æ§è¡ï¼å¹¶å®æresizeæä½ï¼ç»æå¦ä¸ï¼
请ç¹å»è¾å ¥å¾çæè¿°
è¿ééè¦ç¹å«æ³¨æçç¹ï¼ç±äºçº¿ç¨Bå·²ç»æ§è¡å®æ¯ï¼æ ¹æ®Javaå å模åï¼ç°å¨newTableåtableä¸çEntryé½æ¯ä¸»åä¸ææ°å¼ï¼7.next=3ï¼3.next=nullã
æ¤æ¶åæ¢å°çº¿ç¨Aä¸ï¼å¨çº¿ç¨Aæèµ·æ¶å åä¸å¼å¦ä¸ï¼e=3ï¼next=7ï¼newTable[3]=nullï¼ä»£ç æ§è¡è¿ç¨å¦ä¸ï¼
newTable[3]=e ----> newTable[3]=3e=next ----> e=7 æ¤æ¶ç»æå¦ä¸ï¼è¯·ç¹å»è¾å ¥å¾çæè¿°
继ç»å¾ªç¯ï¼
e=7next=e.next ----> next=3ãä»ä¸»åä¸åå¼ãe.next=newTable[3] ----> e.next=3ãä»ä¸»åä¸åå¼ãnewTable[3]=e ----> newTable[3]=7e=next ----> e=3 ç»æå¦ä¸ï¼è¯·ç¹å»è¾å ¥å¾çæè¿°
å次è¿è¡å¾ªç¯ï¼
e=3next=e.next ----> next=nulle.next=newTable[3] ----> e.next=7 å³ï¼3.next=7newTable[3]=e ----> newTable[3]=3e=next ----> e=null 注ææ¤æ¬¡å¾ªç¯ï¼e.next=7ï¼èå¨ä¸æ¬¡å¾ªç¯ä¸7.next=3ï¼åºç°ç¯å½¢é¾è¡¨ï¼å¹¶ä¸æ¤æ¶e=null循ç¯ç»æãç»æå¦ä¸ï¼
请ç¹å»è¾å ¥å¾çæè¿°
å¨åç»æä½ä¸åªè¦æ¶å轮询hashmapçæ°æ®ç»æï¼å°±ä¼å¨è¿éåçæ»å¾ªç¯ï¼é ææ²å§ã
1.2 æ©å®¹é ææ°æ®ä¸¢å¤±åæè¿ç¨
éµç §ä¸è¿°åæè¿ç¨ï¼åå§æ¶ï¼
请ç¹å»è¾å ¥å¾çæè¿°
线ç¨Aå线ç¨Bè¿è¡putæä½ï¼åæ ·çº¿ç¨Aæèµ·ï¼
请ç¹å»è¾å ¥å¾çæè¿°
æ¤æ¶çº¿ç¨Açè¿è¡ç»æå¦ä¸ï¼
请ç¹å»è¾å ¥å¾çæè¿°
æ¤æ¶çº¿ç¨Bå·²è·å¾CPUæ¶é´çï¼å¹¶å®æresizeæä½ï¼
请ç¹å»è¾å ¥å¾çæè¿°
åæ ·æ³¨æç±äºçº¿ç¨Bæ§è¡å®æï¼newTableåtableé½ä¸ºææ°å¼ï¼5.next=nullã
æ¤æ¶åæ¢å°çº¿ç¨Aï¼å¨çº¿ç¨Aæèµ·æ¶ï¼e=7ï¼next=5ï¼newTable[3]=nullã
æ§è¡newtable[i]=eï¼å°±å°7æ¾å¨äºtable[3]çä½ç½®ï¼æ¤æ¶next=5ãæ¥çè¿è¡ä¸ä¸æ¬¡å¾ªç¯ï¼
e=5next=e.next ----> next=nullï¼ä»ä¸»åä¸åå¼e.next=newTable[1] ----> e.next=5ï¼ä»ä¸»åä¸åå¼newTable[1]=e ----> newTable[1]=5e=next ----> e=null å°5æ¾ç½®å¨table[1]ä½ç½®ï¼æ¤æ¶e=null循ç¯ç»æï¼3å ç´ ä¸¢å¤±ï¼å¹¶å½¢æç¯å½¢é¾è¡¨ã并å¨åç»æä½hashmapæ¶é ææ»å¾ªç¯ã请ç¹å»è¾å ¥å¾çæè¿°
2.jdk1.8ä¸HashMap
å¨jdk1.8ä¸å¯¹HashMapè¿è¡äºä¼åï¼å¨åçhash碰æï¼ä¸åéç¨å¤´ææ³æ¹å¼ï¼èæ¯ç´æ¥æå ¥é¾è¡¨å°¾é¨ï¼å æ¤ä¸ä¼åºç°ç¯å½¢é¾è¡¨çæ åµï¼ä½æ¯å¨å¤çº¿ç¨çæ åµä¸ä»ç¶ä¸å®å ¨ï¼è¿éæ们çjdk1.8ä¸HashMapçputæä½æºç ï¼
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node[] tab; Node p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) // å¦æ没æhash碰æåç´æ¥æå ¥å ç´ tab[i] = newNode(hash, key, value, null); else { Node e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; } è¿æ¯jdk1.8ä¸HashMapä¸putæä½ç主å½æ°ï¼ 注æ第6è¡ä»£ç ï¼å¦æ没æhash碰æåä¼ç´æ¥æå ¥å ç´ ãå¦æ线ç¨Aå线ç¨Båæ¶è¿è¡putæä½ï¼å好è¿ä¸¤æ¡ä¸åçæ°æ®hashå¼ä¸æ ·ï¼å¹¶ä¸è¯¥ä½ç½®æ°æ®ä¸ºnullï¼æ以è¿çº¿ç¨AãBé½ä¼è¿å ¥ç¬¬6è¡ä»£ç ä¸ã
å设ä¸ç§æ åµï¼çº¿ç¨Aè¿å ¥åè¿æªè¿è¡æ°æ®æå ¥æ¶æèµ·ï¼è线ç¨Bæ£å¸¸æ§è¡ï¼ä»èæ£å¸¸æå ¥æ°æ®ï¼ç¶å线ç¨Aè·åCPUæ¶é´çï¼æ¤æ¶çº¿ç¨Aä¸ç¨åè¿è¡hashå¤æäºï¼é®é¢åºç°ï¼çº¿ç¨Aä¼æ线ç¨Bæå ¥çæ°æ®ç»è¦çï¼åç线ç¨ä¸å®å ¨ã
æ»ç»
é¦å HashMapæ¯çº¿ç¨ä¸å®å ¨çï¼å ¶ä¸»è¦ä½ç°ï¼
å¨jdk1.7ä¸ï¼å¨å¤çº¿ç¨ç¯å¢ä¸ï¼æ©å®¹æ¶ä¼é æç¯å½¢é¾ææ°æ®ä¸¢å¤±ã
å¨jdk1.8ä¸ï¼å¨å¤çº¿ç¨ç¯å¢ä¸ï¼ä¼åçæ°æ®è¦ççæ åµã