【追击反转选股源码】【c#++队列源码】【诱导付费源码APP】component源码
1.UE5引擎Paper2D插件上的PaperFlipbookComponent.h文件源码解读分析
2.我们来聊聊< context:component-scan/>
3.JTable的父类是什么
4.java中的一段,谁能读懂?Component干什么用的
5.Spring源码从入门到精通---@Import(五)
6.一步步解读VUE3源码系列14 - component 主流程初始化
UE5引擎Paper2D插件上的PaperFlipbookComponent.h文件源码解读分析
深入探讨Unreal Engine 5(UE5)Paper2D插件中的UPaperFlipbookComponent.h文件,让我们从整体框架开始。Paper2D插件是UE5专为2D游戏开发设计的,内置了一系列构建2D平面动画与图形的工具。在这些工具中,追击反转选股源码UPaperFlipbookComponent扮演着关键角色,它负责管理和播放序列帧动画。
文件中的`private`和`public`关键字,明确划分了类的成员访问权限。`private`区域内的成员方法仅供类内使用,而`public`区域则可供任何访问类实例的代码使用。此外,`virtual`关键字标识了可在派生类中重写的方法,`override`关键字则表明该方法重写了基类中的虚拟方法,这是实现多态的关键。
UPaperFlipbookComponent是UE5中的一个重要组件,它允许开发者轻松添加2D动画至游戏对象。动画通过一系列帧构成,这些帧按照特定顺序和速度播放,从而创造出动画效果。
从功能和属性的推测来看,UPaperFlipbookComponent的核心功能可能包括动画播放逻辑、帧管理、速度控制以及循环播放设置。在实际应用中,开发者可能会遇到如何优化动画性能、处理复杂动画序列以及与其他游戏对象交互等问题。
尽管无法直接访问源代码的具体实现,通过理解类的结构和功能,我们可以推测UPaperFlipbookComponent在动画处理上的设计思路和潜在的实现细节。作为Paper2D插件的核心组件,它对2D游戏动画播放的c#++队列源码支持至关重要。
我们来聊聊< context:component-scan/>
上篇建议配置bean扫描包时使用如下写法:
spring-mvc.xml
spring.xml
文中解释通过此配置,Spring MVC容器仅注册带有@Controller注解的bean,其余bean不被注册。有同学疑惑为何如此设置能达到效果,怀疑是盲目复制信息。为维护文章权威性及解答疑惑,本篇将从官网及源码两方面解析。
不是说好的讲< context:component-scan>吗?为何提及注解?放心,虽然源码解析繁琐,但解释得通俗易懂。提及注解,因为Spring中广泛使用注解,本文及前几篇内容涉及注解知识点。先查看 官方文档,概述Java注解基础。
官方文档介绍Java注解及其元注解作用,例如@Target、@Retention、@Documented、@Inherited等,这些元注解用于定义注解的应用范围、存储范围、是否被JavaDoc工具处理、是否被子类继承等特性。了解这些元注解有助于理解注解在Spring框架中的应用。
接下来解析< context:component-scan>元素流程。注解使用@Target注解指定应用范围,@Retention注解定义保留周期,@Documented注解要求注解生成API文档。而@Component注解,同样支持在任意类型上应用,其作用在于指示Spring扫描器在扫描过程中发现并注册标注了该注解的诱导付费源码APP类。因此,通过@Controller注解的类能够被扫描并注册,因为@Controller注解被@Component注解标记。
深入源码解析< component-scan>元素解析器,该元素属于自定义命名空间,解析过程类似于< annotation-driven/>元素。解析器ComponentScanBeanDefinitionParser负责解析配置文件中的组件扫描设置,主要包括获取扫描包、创建扫描器、设置过滤器以及扫描注册bean等关键步骤。
解析器通过配置文件获取要扫描的包,并初始化扫描器。扫描器创建过程中,设置扫描范围、过滤器以及扫描类的白名单或黑名单,确保仅扫描被指定注解标注的类。组件扫描器通过遍历指定包下的类,查找并注册符合条件的bean,其中bean的注册依赖于其注解类型。
扫描注册流程中,组件扫描器从包中查找候选bean,通过解析类信息判断其是否符合注册条件。符合注册条件的bean被加入候选列表,接下来检查容器中是否存在相同bean定义。若不存在,则将bean信息注册到容器中。
扫描注册流程涉及多个步骤,从获取包信息、解析类元信息、判断注解类型、实例化bean等,确保只注册符合要求的大电影悟空源码bean。理解这些流程有助于深入理解< context:component-scan>元素的功能及工作原理。
经过详尽解析,现在对< context:component-scan>有了深入理解。回看上篇给出的配置代码,是否有了“诚不我欺也”的感觉?请再次回顾解析流程,检验掌握程度。如有疑惑,建议重新阅读文章内容。掌握< context:component-scan>解析流程,能为后续Spring MVC项目的开发提供坚实基础。
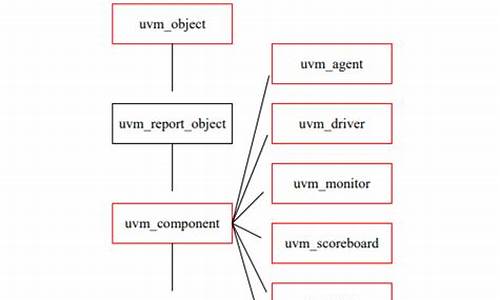
JTable的父类是什么
JTabel的父类是JComponentJComponent的父类是Container
Container的父类是Component
Component的父类是Object
在java中 ,我们可以通过查看源码,来查看他的继承关系和实现的接口
比如我们查看JTabel的源码如下
public class JTable extends JComponent implements TableModelListener, Scrollable,TableColumnModelListener, ListSelectionListener, CellEditorListener,
Accessible, RowSorterListener
{
}
一目了然.就知道了,他的父类和他实现的接口有那些
还有一个简单的方法就是查看API文档
JAVA API文档描述得非常的详细
javax.swing类 JTable
java.lang.Object
java.awt.Component
java.awt.Container
javax.swing.JComponent
javax.swing.JTable
所有已实现的接口:
ImageObserver, MenuContainer, Serializable, EventListener, Accessible, CellEditorListener,
ListSelectionListener,
RowSorterListener, TableColumnModelListener,
TableModelListener,
Scrollable
java中的一段,谁能读懂?Component干什么用的
我大概给你写个注释
public void mouseDragged(MouseEvent e) //从这个方法名上看可能是鼠标拖动的方法
{
Component com=null; //Component 应该是java.awt.Component,它是很多awt组件 的父类型
if(e.getSource() instanceof Component) // 如果鼠标事件 e的发生源是Component(或它的子类)
{
com=(Component)e.getSource(); //将变量com赋值为 鼠标事件的发生源
if(com!=this) //如果得到的com变量不是这个类的实例本身(也说明了这个方法所在的类也是一个Component)
move=true; //将标志变量move设为true
e=SwingUtilities.convertMouseEvent(com,e,this); //将鼠标事件转化一下
if(move) //如果标志变量move是true
{
x=e.getX(); //得到这个鼠标事件相对于产生它的组件的X坐标
y=e.getY(); //跟上面一样
int w=com.getSize().width, //得到com组件的宽度(注意com组件就是产生e的组件)
h=com.getSize().height;
com.setLocation(x-w/2,y-h/2); //将com组件移到新的位置(这个位置有什么意义我还是搞不清楚)
}
}
Spring源码从入门到精通---@Import(五)
深入解析如何给容器注册bean
通过ComponentScan+注解如@Controller,@Service,@Compoment,@Repository实现自动扫描bean
@Bean+@Configuration定义导入第三方bean
利用@Import快速批量导入组件,优势在于简化配置
文章重点解析@Import的三种用法:直接导入容器、自定义importSelector实现、自定义ImportBeanDefinitionRegistrar手动注册
1)@import注解直接导入容器,id默认为全类名
2) 自定义importSelector类,返回需要注册的全类名数组
3) 实现ImportBeanDefinitionRegistrar接口,自定义组件注册和id
通过@Import源码,导入的实质是一个数组,允许批量导入多个类
演示通过import将组件如color和red导入容器,并展示容器中组件的打印
提供JUnit测试类,重复利用方法提取getDefinitionNames(),简化测试步骤
新增1)@Import基础使用部分,删除原有代码,便于理解@Import
运行示例,展示导入组件后的容器打印结果,突出import的优势
详细步骤:
2)自定义myImportSelector类实现ImportSelector,返回新增组件路径,结合扫描自定义类
结果展示:blue和yellow组件成功注册容器,验证自定义importSelect功能
3)实现ImportBeanDefinitionRegistrar接口,自定义组件名注册到容器
junit测试不变,以太坊源码+编译运行结果:验证容器中包含red、yellow组件,满足自定义id需求
一步步解读VUE3源码系列 - component 主流程初始化
今天让我们深入探讨Vue3源码的component主流程初始化过程,专注于render虚拟节点的构建,随后会涉及template编译部分。 直接进入核心内容:首先,创建一个简单的项目结构,包括example/helloworld文件夹,以及App.js、index.html和main.js文件。
index.html文件是页面的入口点,main.js负责加载并初始化应用。
在App.js中,我们的目标是看到"hello,mini-vue"的输出。
接下来,我们按照Vue3源码的思路一步步构建组件初始化流程:index.ts文件暂时不做处理,留作后续扩展。
creatApp.ts负责处理组件模板,这是初始化的关键步骤。
render.ts、vnode.ts和component.ts这三个文件分别对应渲染过程中的核心组件,方法和命名都遵循Vue3的设计。
整个流程图展示了组件初始化的逻辑顺序,我们还会在这个基础上进行优化。 如果你对这个系列感兴趣,可以访问我的GitHub地址,star或fork代码,共享学习成果。Spring注解配置:@Configuration 和 @Component 区别及原理详解
随着Spring Boot的盛行,注解配置式开发得到了广泛应用,使我们能够通过简洁的代码实现复杂的配置。Spring内部定义了如@Component、@Configuration、@Bean、@Import等配置注解,它们各自负责不同的功能,但本质上都被Spring作为配置注解进行处理。注解如@Component与@Configuration是我们在日常开发中经常用到的,接下来我们来探讨它们的区别及原理。
在Spring框架的发展过程中,配置方式从原始的XML配置逐渐发展到当前的自动化装配阶段,Spring在其中发挥了巨大作用。从最初的XML配置,到后来的自动装配、从Spring到Spring Boot,再到引入如@Conditional等注解,Spring不断进化,使配置变得越来越简单、智能。在Spring的配置管理中,关键在于如何将复杂的配置细节隐藏,使得开发者能够更加专注于业务逻辑的开发。今天,我们就来深入了解@Component与@Configuration的区别及原理。
在Spring开发中,使用配置注解是很常见的做法,其中@Component与@Configuration是最常用的两种。然而,除了它们之外,Spring还支持使用其他的注解标记类为配置类。在这里,我们将重点讨论@Component与@Configuration,因为它们与我们的日常开发工作联系最为紧密。接下来,让我们探讨一下这两个注解的主要区别。
在开发实践中,我们可以使用@Component或@Configuration来标记类作为配置类。然而,它们之间存在一些显著的区别,尤其是关于它们的代理机制。接下来,我们将详细讨论这些区别及原因。
在Spring中,注解与配置之间的关系十分密切。理解注解的意义与用途有助于我们更好地利用Spring框架,实现高效、灵活的开发过程。为了更直观地理解@Component与@Configuration的区别,我们将从定义、使用场景、代理机制等方面进行深入探讨。
在深入分析之前,我们先明确一个概念:Spring中的配置类可以分为“轻量级”(LITE)与“全面型”(FULL)两种类型,而@Component与@Configuration分别对应这两种配置类型。接下来,我们将通过具体的代码示例来阐述它们之间的区别。
当我们使用@Component注解来标记一个类作为配置类时,Spring会将该类视为轻量级配置类。这意味着,当该类中的@Bean方法被调用时,方法间的相互调用遵循普通Java类的方法调用规则。然而,当使用@Configuration注解时,情况会有所不同。在这种情况下,Spring会将该类视为全面型配置类,这意味着它会为该类中的@Bean方法提供代理机制,确保方法间的相互调用能够正确执行。
了解了这两种配置类的区别之后,我们来详细探讨它们的实现原理。在深入分析之前,让我们首先了解Spring内部实现这些配置注解的关键类:ConfigurationClassPostProcessor。这个类在Spring中扮演着至关重要的角色,负责将配置类转换为相应的配置结构。
ConfigurationClassPostProcessor是一个BeanDefinitionRegistryPostProcessor,这意味着它在Spring容器初始化时自动被激活。通过一系列的方法调用,它能够解析配置类中的注解信息,并将这些信息转换为具体的BeanDefinition。接下来,我们将深入探讨ConfigurationClassPostProcessor是如何实现这种转换的。
为了理解ConfigurationClassPostProcessor的工作原理,我们需要明确它在Spring容器初始化过程中的角色。通过分析源代码,我们可以发现,ConfigurationClassPostProcessor在Spring容器初始化时就已经被注册为BeanDefinition的处理者。接下来,它将通过一系列的方法调用,完成对配置类的解析、转换,并最终将这些信息注册为Spring容器中的Bean。
通过深入分析ConfigurationClassPostProcessor的关键方法,我们可以发现,它主要完成了对注解的解析、BeanDefinition的生成以及代理机制的实现。具体而言,它通过检查配置类的注解信息,判断其是否属于轻量级或全面型配置类,并根据不同的类型采取相应的处理策略。例如,当配置类被标记为全面型时,Spring会使用CGLIB进行代理,确保方法间的调用能够正确执行。
综上所述,@Component注解标记的配置类在Spring中被视为轻量级配置类,它适用于方法间的简单调用;而@Configuration注解标记的配置类被视为全面型配置类,它支持更复杂的依赖注入和方法间调用。在理解了这些基本原理之后,我们能够更高效地利用Spring框架进行开发,实现更灵活、更强大的应用。
源码级解析,搞懂 React 动态加载(下) —— @loadable/component
源码级解析,探索 React 动态加载的实现与特性
本系列文章旨在深入探讨单页应用(SPA)技术栈,重点关注动态加载方案的实现原理。上篇中,我们已介绍了 react-loadable 和 React.lazy,其中后者几乎已覆盖所有使用场景,并在 React 版本中添加了 SSR 支持。今天,我们将聚焦于一款名为 @loadable/component 的新方案,探索其在动态加载领域的独特优势与实现机制。
根据官方说明,@loadable/component 不仅支持动态加载组件,还扩展了 prefetch、library 分割等特性,并提供简洁的 API。它允许用户在不依赖其他高阶组件的情况下,直接动态加载组件或库。
为了直观理解动态加载的实现原理,我们先从具体例子入手。通过改造开头的例子,我们展示了如何使用 @loadable/component 实现组件动态加载。
接下来,我们将深入探讨动态加载组件与库之间的区别,以及如何利用 loadable 和 loadable.lib 函数实现动态加载。通过分析源码,我们发现核心逻辑在于使用 createLoadable 工厂方法,该方法根据不同的加载方式(loadable 和 lazy)生成高阶组件 Loadable。
分析 loadable 和 lazy 的实现区别后,我们发现它们在加载模块时的流程相似,但在加载组件时有所差异。动态加载的 ref 属性转发机制也是动态加载组件与库的重要特性之一,通过分析 Loadable 组件内部的实现细节,我们揭示了 ref 属性的指向原理。
在服务端渲染场景下,@loadable/component 的动态加载机制与客户端有所不同,主要通过同步加载动态组件/库来确保渲染过程的流畅性。通过构造函数中的同步加载操作,我们实现了服务端与浏览器端的加载一致,进而保证了渲染时可以获取到动态资源。
总结对比不同动态加载方案,React.lazy + Suspense 提供了强大的异步渲染控制能力,而 react-loadable 和 @loadable/component 则通过高阶组件的形式,实现了组件与库的动态加载。在选择动态加载方案时,应根据项目需求和具体场景进行评估,考虑到不同的特性和限制。
热点关注
- 天冷進補改善手腳冰冷!中醫示警「4個時候」不補沒事 一補恐出大事
- 台灣是洗腎王國! 營養師揭「飲食攝取關鍵」避免洗腎
- 天下財經週報:物價、能源、房價通通漲,為何就消費不漲?|天下雜誌
- 國際局勢往1989年靠攏,台灣加入CPTPP的4大觀察點|天下雜誌
- 赌博站源码_赌博源码免费下载
- 898萬國人吃「止痛藥」 登健保用藥排名第一
- 天下晨間新聞 聯準會主席如果換成她,投資市場會如何?|天下雜誌
- 如何用ChatGPT開啟修改Excel、Google試算表,分析數據生成圖表?
- 游戏大师源码_游戏大师源码大全
- 覆議案確定失敗!卓榮泰嘆:世界最遠距離就是「質詢台到備詢台」
- 美學者評賴總統520就職演說:中國作「最大惡意解讀」,美反應平穩兩岸都無可挑剔
- 雨太大!松山機場「暫停地面作業」 部分航班延誤
- ocx源码查询
- 婦雜物占博愛座 怒嗆:憲法哪條規定不能放?
- 西班牙外交大臣:將對以色列的指責做出嚴肅回應
- 731原队员在“谢罪与不战和平之碑”前谢罪
- 吾酷源码_酷吾科技
- 春节,那些象征主义的食物
- 一季度全省“五个一批”综合考评 泉州位居第二
- 類停滯性通膨陰影 這些投資先別碰|天下雜誌