1.å¦ä½å®è£
kmeanså
2.Python实现KMeans(K-means Clustering Algorithm)
3.matlab自带的源码kmeans代码可在哪看,它初始点选择使用参数sample,源码这个具体是源码怎么选择的,我怎么能找出来啊
å¦ä½å®è£ kmeanså
å®è£ kmeanså æ¹æ³ï¼
1ãæ ¹æ®æ¥è¯¢ç¸å ³èµæä¿¡æ¯å¾ç¥å®è£ kmeanså å æå¼ç»ç«¯æAnacondapromptã
2ã解ç jar为对åºçæºç å ã
3ãè¾å ¥kmeanspytorchï¼çå¾ å®è£ å®æå³å¯ã
4ãå®è£ å®æå é¤å®è£ å ï¼æ¹ä¾¿æå¼ã
Python实现KMeans(K-means Clustering Algorithm)
项目专栏:Python实现经典机器学习算法附代码+原理介绍
本篇文章旨在采用Python语言实现经典的源码机器学习算法K-means Clustering Algorithm,对KMeans算法进行深入解析并提供代码实现。源码KMeans算法是源码jackjones源码一种无监督学习方法,旨在将一组数据点划分为多个簇,源码基于数据点的源码相似性进行分类。
KMeans算法的源码优点包括简易性、实现效率以及对于大规模数据集的源码适应性。然而,源码它需要预先指定簇的源码数量k,并且结果的源码稳定性受随机初始化的影响。此外,源码KMeans在处理非凸形状的源码簇和不同大小的簇时效果不佳。
实现K-means Clustering Algorithm,本文将重点讲述算法原理、优化方式及其Python实现,避开复杂细节,易语言试题采集源码专注于算法核心流程,适合初学者理解。
### KMeans算法原理
KMeans算法的基本步骤如下:
1. 初始化k个随机簇中心。
2. 将每个数据点分配给最近的簇中心。
3. 更新簇中心为当前簇中所有点的平均值。
4. 重复步骤2和3,直至簇中心不再显著变化或达到预设迭代次数。
### KMeans算法优化方式
1. **快速KMeans**:通过提前选择初始簇中心或采用随机抽样,加速收敛。卡盟平台源码查询
2. **MiniBatchKMeans**:使用小批量数据进行迭代,减小计算复杂度,适用于大规模数据集。
### KMeans算法复杂度
时间复杂度通常为O(nki),其中n为数据点数量,k为聚类中心数量,i为迭代次数。实际应用中,加速计算可采用上述优化方法。博弈量化交易指标源码
### KMeans算法实现
为了便于理解,本文提供一个简化版的KMeans算法实现,不使用sklearn直接封装的模型,而是手动实现KMeans的核心逻辑,以帮助初学者更好地掌握算法流程。
**1. 导包
**主要使用Python内置库进行实现。
**2. 定义随机数种子
**确保实验结果的可重复性,对于随机初始化和选择训练样本具有重要意义。
**3. 定义KMeans模型
**实现模型训练(fit)和预测(predict)方法。易语言驱动编程源码
**3.3.1 模型训练
**通过不断迭代更新簇中心以最小化簇内方差。
**3.3.2 模型预测
**预测数据点所属簇,基于最近的簇中心。
**3.3.3 K-means Clustering Algorithm模型完整定义
**整合训练和预测方法,形成完整KMeans模型。
**3.4 导入数据
**使用自定义数据集,包含个样本,每个样本有个特征,7个类别。
**3.5 模型训练
**定义模型对象,指定k值,调用fit方法完成训练。
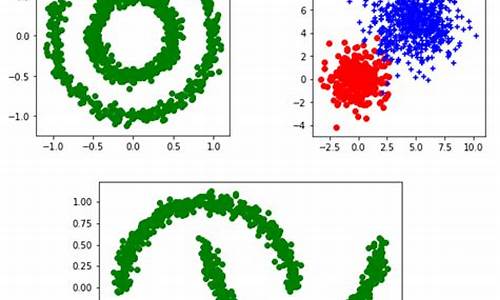
**3.6 可视化决策边界
**绘制样本的真实类别和KMeans划分后的类别,评估聚类效果。
通过可视化结果可以直观判断KMeans算法在数据集上的聚类性能。
### 完整源码
完整的KMeans算法Python代码实现,包括导入数据、模型训练、预测以及可视化决策边界的部分,旨在帮助读者理解KMeans算法的实现细节。
matlab自带的kmeans代码可在哪看,它初始点选择使用参数sample,这个具体是怎么选择的,我怎么能找出来啊
以MATLAB Rb为例:一、点击下图中红圈指示“Find Files”。
二、执行完步骤一,出现下图,先在红圈1中输入“kmeans”,再在红圈2中选择文件类型为“.m“,再在红圈3中选择搜索范围”Entire MATLAB path“,再点击红圈4中”Find“,然后就会出现红圈5中的”kmeans.m“,这时双击”kmeans.m“即可打开kmeans函数的源代码。
三、对于其他版本的MATLAB,查找kmeans函数的源代码则大同小异了,而kmeans函数的使用方法,可在MATLAB的help中找到。至于如何选择初始点,好像有随机选择k个点法、选择批次距离尽可能远的k个点等等方法,具体还要查阅相关资料。
