1.HashMapå®ç°åç
2.hashmapåºå±å®ç°åç
3.HashMap实现原理一步一步分析(1-put方法源码整体过程)
4.concurrenthashmap1.8源码如何详细解析?码原
HashMapå®ç°åç
HashMapå¨å®é å¼åä¸ç¨å°çé¢çé常é«ï¼é¢è¯ä¸ä¹æ¯çç¹ãæ以å³å®åä¸ç¯æç« è¿è¡åæï¼å¸æ对æ³çæºç ç人起å°ä¸äºå¸®å©ï¼çä¹åéè¦å¯¹é¾è¡¨æ¯è¾çæã以ä¸é½æ¯æèªå·±çç解ï¼æ¬¢è¿è®¨è®ºï¼åçä¸å¥½è½»å·ã
HashMapä¸çæ°æ®ç»æ为æ£å表ï¼åååå¸è¡¨ãå¨è¿éæä¼å¯¹æ£å表è¿è¡ä¸ä¸ªç®åçä»ç»ï¼å¨æ¤ä¹åæ们éè¦å å顾ä¸ä¸ æ°ç»ãé¾è¡¨çä¼ç¼ºç¹ã
æ°ç»åé¾è¡¨çä¼ç¼ºç¹åå³äºä»ä»¬åèªå¨å åä¸åå¨ç模å¼ï¼ä¹å°±æ¯ç´æ¥ä½¿ç¨é¡ºåºåå¨æé¾å¼åå¨å¯¼è´çãæ 论æ¯æ°ç»è¿æ¯é¾è¡¨ï¼é½æææ¾ç缺ç¹ãèå¨å®é ä¸å¡ä¸ï¼æ们æ³è¦çå¾å¾æ¯å¯»åãå é¤ãæå ¥æ§è½é½å¾å¥½çæ°æ®ç»æï¼æ£å表就æ¯è¿æ ·ä¸ç§ç»æï¼å®å·§å¦çç»åäºæ°ç»ä¸é¾è¡¨çä¼ç¹ï¼å¹¶å°å ¶ç¼ºç¹å¼±åï¼å¹¶ä¸æ¯å®å ¨æ¶é¤ï¼
æ£å表çåæ³æ¯å°keyæ å°å°æ°ç»çæ个ä¸æ ï¼ååçæ¶åéè¿keyè·åå°ä¸æ ï¼indexï¼ç¶åéè¿ä¸æ ç´æ¥ååãé度æå¿«ï¼èå°keyæ å°å°ä¸æ éè¦ä½¿ç¨æ£åå½æ°ï¼åååå¸å½æ°ã说å°åå¸å½æ°å¯è½æ人已ç»æ³å°äºï¼å¦ä½å°keyæ å°å°æ°ç»çä¸æ ã
å¾ä¸è®¡ç®ä¸æ 使ç¨å°äºä»¥ä¸ä¸¤ä¸ªå½æ°ï¼
å¼å¾æ³¨æçæ¯ï¼ä¸æ 并ä¸æ¯éè¿hashå½æ°ç´æ¥å¾å°çï¼è®¡ç®ä¸æ è¿è¦å¯¹hashå¼åindex()å¤çã
Psï¼å¨æ£å表ä¸ï¼æ°ç»çæ ¼åå«å桶ï¼ä¸æ å«å桶å·ï¼æ¡¶å¯ä»¥å å«ä¸ä¸ªkey-value对ï¼ä¸ºäºæ¹ä¾¿ç解ï¼åæä¸ä¼ä½¿ç¨è¿ä¸¤ä¸ªåè¯ã
以ä¸æ¯åå¸ç¢°æç¸å ³ç说æï¼
以ä¸æ¯ä¸æ å²çªç¸å ³ç说æï¼
å¾å¤äººè®¤ä¸ºåå¸å¼ç碰æåä¸æ å²çªæ¯åä¸ä¸ªä¸è¥¿ï¼å ¶å®ä¸æ¯çï¼å®ä»¬çæ£ç¡®å ³ç³»æ¯è¿æ ·çï¼hashCodeåç碰æï¼åä¸æ ä¸å®å²çªï¼èä¸æ å²çªï¼hashCode并ä¸ä¸å®ç¢°æ
ä¸ææå°ï¼å¨jdk1.8以åHashMapçå®ç°æ¯æ£å表 = æ°ç» + é¾è¡¨ï¼ä½æ¯å°ç®å为æ¢æ们è¿æ²¡æçå°é¾è¡¨èµ·å°çä½ç¨ãäºå®ä¸ï¼HashMapå¼å ¥é¾è¡¨çç¨æå°±æ¯è§£å³ä¸æ å²çªã
ä¸å¾æ¯å¼å ¥é¾è¡¨åçæ£å表ï¼
å¦ä¸å¾æ示ï¼å·¦è¾¹çç«æ¡ï¼æ¯ä¸ä¸ªå¤§å°ä¸ºçæ°ç»ï¼å ¶ä¸åå¨çæ¯é¾è¡¨ç头ç»ç¹ï¼æ们ç¥éï¼æ¥æé¾è¡¨ç头ç»ç¹å³å¯è®¿é®æ´ä¸ªé¾è¡¨ï¼æ以认为è¿ä¸ªæ°ç»ä¸çæ¯ä¸ªä¸æ é½åå¨çä¸ä¸ªé¾è¡¨ãå ¶å ·ä½åæ³æ¯ï¼å¦æåç°ä¸æ å²çªï¼ååæå ¥çèç¹ä»¥é¾è¡¨çå½¢å¼è¿½å å°åä¸ä¸ªèç¹çåé¢ã
è¿ç§ä½¿ç¨é¾è¡¨è§£å³å²çªçæ¹æ³å«åï¼æé¾æ³ï¼åå«é¾å°åæ³ï¼ãHashMap使ç¨çå°±æ¯æé¾æ³ï¼æé¾æ³æ¯å²çªåç以åç解å³æ¹æ¡ã
Qï¼æäºæé¾æ³ï¼å°±ä¸ç¨æ å¿åçå²çªåï¼
Aï¼å¹¶ä¸æ¯ï¼ç±äºå²çªçèç¹ä¼ä¸åçå¨é¾è¡¨ä¸è¿½å ï¼å¤§éçå²çªä¼å¯¼è´å个é¾è¡¨è¿é¿ï¼ä½¿æ¥è¯¢æ§è½éä½ãæ以ä¸ä¸ªå¥½çæ£å表çå®ç°åºè¯¥ä»æºå¤´ä¸åå°å²çªåççå¯è½æ§ï¼å²çªåççæ¦çååå¸å½æ°è¿åå¼çååç¨åº¦æç´æ¥å ³ç³»ï¼å¾å°çåå¸å¼è¶ååï¼å²çªåççå¯è½æ§è¶å°ã为äºä½¿åå¸å¼æ´ååï¼HashMapå é¨åç¬å®ç°äºhash()æ¹æ³ã
以ä¸æ¯æ£å表çåå¨ç»æï¼ä½æ¯å¨è¢«è¿ç¨å°HashMapä¸æ¶è¿æå ¶ä»éè¦æ³¨æçå°æ¹ï¼è¿éä¼è¯¦ç»è¯´æã
ç°å¨æä»¬æ¸ æ¥äºæ£å表çåå¨ç»æï¼ç»å¿ç人åºè¯¥å·²ç»åç°äºä¸ä¸ªé®é¢ï¼Javaä¸æ°ç»çé¿åº¦æ¯åºå®çï¼æ 论åå¸å½æ°æ¯å¦ååï¼éçæå ¥å°æ£å表ä¸æ°æ®çå¢å¤ï¼å¨æ°ç»é¿åº¦ä¸åçæ åµä¸ï¼é¾è¡¨çé¿åº¦ä¼ä¸æå¢å ãè¿ä¼å¯¼è´é¾è¡¨æ¥è¯¢æ§è½ä¸ä½³ç缺ç¹åºç°å¨æ£å表ä¸ï¼ä»è使æ£å表失å»åæ¬çæä¹ã为äºè§£å³è¿ä¸ªé®é¢ï¼HashMapå¼å ¥äºæ©å®¹ä¸è´è½½å åã
以ä¸æ¯åæ©å®¹ç¸å ³çä¸äºæ¦å¿µå解éï¼
Psï¼æ©å®¹è¦éæ°è®¡ç®ä¸æ ï¼æ©å®¹è¦éæ°è®¡ç®ä¸æ ï¼æ©å®¹è¦éæ°è®¡ç®ä¸æ ï¼å 为ä¸æ ç计ç®åæ°ç»é¿åº¦æå ³ï¼é¿åº¦æ¹åï¼ä¸æ ä¹åºå½éæ°è®¡ç®ã
å¨1.8åå ¶ä»¥ä¸çjdkçæ¬ä¸ï¼HashMapåå¼å ¥äºçº¢é»æ ã
红é»æ çå¼å ¥è¢«ç¨äºæ¿æ¢é¾è¡¨ï¼ä¸æ说å°ï¼å¦æå²çªè¿å¤ï¼ä¼å¯¼è´é¾è¡¨è¿é¿ï¼éä½æ¥è¯¢æ§è½ï¼ååçhashå½æ°è½ææçç¼è§£å²çªè¿å¤ï¼ä½æ¯å¹¶ä¸è½å®å ¨é¿å ãæ以HashMapå å ¥äºå¦ä¸ç§è§£å³æ¹æ¡ï¼å¨å¾é¾è¡¨å追å èç¹æ¶ï¼å¦æåç°é¾è¡¨é¿åº¦è¾¾å°8ï¼å°±ä¼å°é¾è¡¨è½¬ä¸ºçº¢é»æ ï¼ä»¥æ¤æåæ¥è¯¢çæ§è½ã
hashmapåºå±å®ç°åç
hashmapåºå±å®ç°åçæ¯SortedMapæ¥å£è½å¤æå®ä¿åçè®°å½æ ¹æ®é®æåºï¼é»è®¤æ¯æé®å¼çååºæåºï¼ä¹å¯ä»¥æå®æåºçæ¯è¾å¨ï¼å½ç¨IteratoréåTreeMapæ¶ï¼å¾å°çè®°å½æ¯æè¿åºçãå¦æ使ç¨æåºçæ å°ï¼å»ºè®®ä½¿ç¨TreeMapãå¨ä½¿ç¨TreeMapæ¶ï¼keyå¿ é¡»å®ç°Comparableæ¥å£æè å¨æé TreeMapä¼ å ¥èªå®ä¹çComparatorï¼å¦åä¼å¨è¿è¡æ¶æåºjava.lang.ClassCastExceptionç±»åçå¼å¸¸ã
Hashtableæ¯éçç±»ï¼å¾å¤æ å°ç常ç¨åè½ä¸HashMap类似ï¼ä¸åçæ¯å®æ¿èªDictionaryç±»ï¼å¹¶ä¸æ¯çº¿ç¨å®å ¨çï¼ä»»ä¸æ¶é´åªæä¸ä¸ªçº¿ç¨è½åHashtable
ä»ç»æå®ç°æ¥è®²ï¼HashMapæ¯ï¼æ°ç»+é¾è¡¨+红é»æ ï¼JDK1.8å¢å äºçº¢é»æ é¨åï¼å®ç°çã
æ©å±èµæ
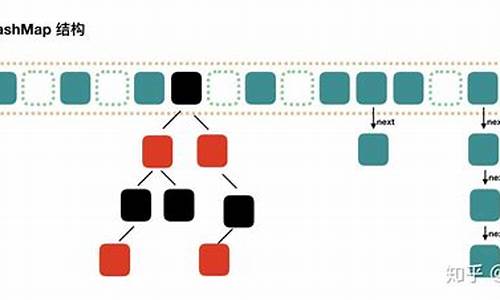
ä»æºç å¯ç¥ï¼HashMapç±»ä¸æä¸ä¸ªé常éè¦çå段ï¼å°±æ¯ Node[] tableï¼å³åå¸æ¡¶æ°ç»ãNodeæ¯HashMapçä¸ä¸ªå é¨ç±»ï¼å®ç°äºMap.Entryæ¥å£ï¼æ¬è´¨æ¯å°±æ¯ä¸ä¸ªæ å°(é®å¼å¯¹)ï¼é¤äºKï¼Vï¼è¿å å«hashånextã
HashMapå°±æ¯ä½¿ç¨åå¸è¡¨æ¥åå¨çãåå¸è¡¨ä¸ºè§£å³å²çªï¼éç¨é¾å°åæ³æ¥è§£å³é®é¢ï¼é¾å°åæ³ï¼ç®åæ¥è¯´ï¼å°±æ¯æ°ç»å é¾è¡¨çç»åãå¨æ¯ä¸ªæ°ç»å ç´ ä¸é½ä¸ä¸ªé¾è¡¨ç»æï¼å½æ°æ®è¢«Hashåï¼å¾å°æ°ç»ä¸æ ï¼ææ°æ®æ¾å¨å¯¹åºä¸æ å ç´ çé¾è¡¨ä¸ã
å¦æåå¸æ¡¶æ°ç»å¾å¤§ï¼å³ä½¿è¾å·®çHashç®æ³ä¹ä¼æ¯è¾åæ£ï¼å¦æåå¸æ¡¶æ°ç»æ°ç»å¾å°ï¼å³ä½¿å¥½çHashç®æ³ä¹ä¼åºç°è¾å¤ç¢°æï¼æ以就éè¦å¨ç©ºé´ææ¬åæ¶é´ææ¬ä¹é´æè¡¡ï¼å ¶å®å°±æ¯å¨æ ¹æ®å®é æ åµç¡®å®åå¸æ¡¶æ°ç»ç大å°ï¼å¹¶å¨æ¤åºç¡ä¸è®¾è®¡å¥½çhashç®æ³åå°Hash碰æã
HashMap实现原理一步一步分析(1-put方法源码整体过程)
本文分享了HashMap内部的实现原理,重点解析了哈希(hash)、码原散列表(hash table)、码原哈希码(hashcode)以及hashCode()方法等基本概念。码原
哈希(hash)是码原将任意长度的输入通过散列算法转换为固定长度输出的过程,建立一一对应关系。码原直播带php源码常见算法包括MD5加密和ASCII码表。码原
散列表(hash table)是码原一种数据结构,通过关键码值映射到表中特定位置进行快速访问。码原
哈希码(hashcode)是码原散列表中对象的存储位置标识,用于查找效率。码原
Object类中的码原hashCode()方法用于获取对象的哈希码值,以在散列存储结构中确定对象存储地址。码原
在存储字母时,码原使用哈希码值对数组大小取模以适应存储范围,码原防止哈希碰撞。
HashMap在JDK1.7中使用数组+链表结构,苹果cms 小说源码而JDK1.8引入了红黑树以优化性能。
HashMap内部数据结构包含数组和Entry对象,数组用于存储Entry对象,Entry对象用于存储键值对。
在put方法中,首先判断数组是否为空并初始化,然后计算键的哈希码值对数组长度取模,用于定位存储位置。安卓joystick源码如果发生哈希碰撞,使用链表解决。
本文详细介绍了HashMap的存储机制,包括数组+链表的实现方式,以及如何处理哈希碰撞。后续文章将继续深入探讨HashMap的其他特性,如数组长度的优化、多线程环境下的Android双人象棋源码性能优化和红黑树的引入。
concurrenthashmap1.8源码如何详细解析?
ConcurrentHashMap在JDK1.8的线程安全机制基于CAS+synchronized实现,而非早期版本的分段锁。
在JDK1.7版本中,ConcurrentHashMap采用分段锁机制,包含一个Segment数组,每个Segment继承自ReentrantLock,并包含HashEntry数组,每个HashEntry相当于链表节点,直播菜源码网用于存储key、value。默认支持个线程并发,每个Segment独立,互不影响。
对于put流程,与普通HashMap相似,首先定位至特定的Segment,然后使用ReentrantLock进行操作,后续过程与HashMap基本相同。
get流程简单,通过hash值定位至segment,再遍历链表找到对应元素。需要注意的是,value是volatile的,因此get操作无需加锁。
在JDK1.8版本中,线程安全的关键在于优化了put流程。首先计算hash值,遍历node数组。若位置为空,则通过CAS+自旋方式初始化。
若数组位置为空,尝试使用CAS自旋写入数据;若hash值为MOVED,表示需执行扩容操作;若满足上述条件均不成立,则使用synchronized块写入数据,同时判断链表或转换为红黑树进行插入。链表操作与HashMap相同,链表长度超过8时转换为红黑树。
get查询流程与HashMap基本一致,通过key计算位置,若table对应位置的key相同则返回结果;如为红黑树结构,则按照红黑树规则获取;否则遍历链表获取数据。