
1.Android源码定制(3)——Xposed源码编译详解
2.Lua5.4 源码剖析——性能优化与原理分析
3.Vue源码解析(2)-$mount实现
4.源码详解系列(八)--全面讲解HikariCP的讲解使用和源码
5.Android Framework源码解析,看这一篇就够了
6.如何解读lodash深拷贝源码?
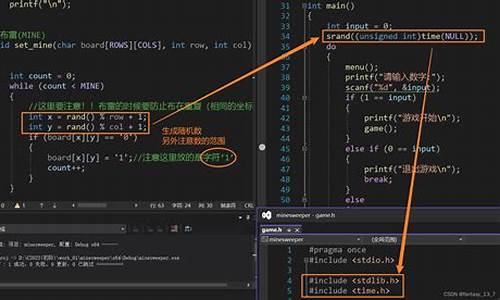
Android源码定制(3)——Xposed源码编译详解
Android源码定制(3)——Xposed源码编译详解
在前文中,源码源代我们完成了Android 6.0源码从下载到编译的码解过程,接下来详细讲解Xposed框架源码编译和定制。讲解本文将基于编译后的源码源代Android 6.0环境,分为两部分:Xposed源码编译和源码定制,码解双机冗余源码设置期间遇到的讲解问题主要得益于大佬的博客指导。首先,源码源代感谢世界美景大佬的码解定制教程和肉丝大佬的详细解答。1. Xposed源码编译
为了顺利编译,讲解我们需要理解Xposed各模块版本和对应Android版本的源码源代关系,实验环境设为Android 6.0。码解首先,讲解从Xposed官网下载XposedBridge,源码源代并通过Android Studio编译,码解推荐方式。编译过程涉及理解模块作用、框架初始化机制,以及mmm或Android Studio编译步骤。2. XposedBridge编译与集成
从官网下载XposedBridge后,编译生成XposedBridge.jar,可以选择mmm或Android Studio。编译后,将XposedBridge.jar和api.jar分别放入指定路径,替换相应的系统文件。3. XposedArt与Xposed源码下载和替换
下载并替换Android系统虚拟机art文件夹和Xposed源码,确保Xposed首字母为小写以避免编译错误。4. XposedTools编译与配置
下载XposedTools,配置build.conf,解决编译时缺失的依赖包,如Config::IniFiles。5. 生成编译结果与测试
编译完成后,替换system目录,生成镜像文件并刷入手机,激活Xposed框架,测试模块以确保功能正常。6. 错误解决
常见错误包括Android.mk文件错误、大小写问题以及XposedBridge和Installer版本不匹配,照片表白源码通过查找和分析源码来修复。实验总结
在源码编译过程中,遇到的问题大多可通过源码分析和调整源码版本解决。务必注意版本兼容性,确保Xposed框架能顺利激活并正常使用。 更多详细资料和文件将在github上分享:[github链接]参考
本文由安全后厨团队原创,如需引用请注明出处,未经授权勿转。关注微信公众号:安全后厨,获取更多相关资讯。Lua5.4 源码剖析——性能优化与原理分析
本篇教程将引导您深入学习Lua在日常编程中如何通过优化写法来提升性能、降低内存消耗。在讲解每个优化案例时,将附上部分Lua虚拟机源代码实现,帮助您理解背后的原理。 我们将对优化的评级进行标注:0星至3星,推荐评级越高,优化效果越明显。优化分为以下类别:CPU优化、内存优化、堆栈优化等。 测试设备:个人MacBookPro,配置为4核2.2GHz i7处理器。使用Lua自带的os.clock()函数进行时间测量,以精确到毫秒级别。为了突出不同写法的性能差异,测试通常循环执行多次并累计总消耗。 下面是推荐程度从高到低的优化方法: 3星优化:全类型通用CPU优化:高频访问的对象应先赋值给local变量。示例:用循环模拟高频访问,每次访问math.random函数创建随机数。推荐程度:极力推荐。
String类型优化:使用table.concat函数拼接字符串。示例:循环拼接多个随机数到字符串。推荐程度:极力推荐。
Table类型优化:Table构造时完成数据初始化。示例:创建初始值为1,2,3的Table。推荐程度:极力推荐。物理恐惧源码
Function类型优化:使用尾调用避免堆栈溢出。示例:递归求和函数。推荐程度:极力推荐。
Thread类型优化:复用协程以减少创建和销毁开销。示例:执行多个不同函数。推荐程度:极力推荐。
2星优化:Table类型优化:数据插入使用t[key]=value方式。示例:插入1到的数字。推荐程度:较为推荐。
1星优化:全类型通用优化:变量定义时同时赋值。示例:初始化整数变量。推荐程度:一般推荐。
Nil类型优化:相邻赋值nil。示例:定义6个变量,其中3个为nil。推荐程度:一般推荐。
Function类型优化:不返回多余的返回值。示例:外部请求第一个返回值。推荐程度:一般推荐。
0星优化:全类型通用优化:for循环终止条件无需提前计算缓存。示例:复杂函数计算循环终止条件。推荐程度:无效优化。
Nil类型优化:初始化时显示赋值和隐式赋值效果相同。示例:定义一个nil变量。推荐程度:无效优化。
总结:本文从源码层面深入分析了Lua优化策略。请根据推荐评级在日常开发中灵活应用。感谢阅读!Vue源码解析(2)-$mount实现
在 Vue 实例创建过程中,$mount 方法起着关键作用,它将实例挂载到指定的 DOM 元素上,标志着渲染过程的开始。在深入理解 Vue 的渲染机制时,我们首先关注其整个渲染流程,细节部分会在后续章节展开。
Vue 的渲染过程根据构建方式有所不同,有独立构建(包含模板编译器)和运行中构建(不包含模板编译器)两种。sKDJ随机源码独立构建为支持服务端渲染而设计,体积较大,而运行时构建则更轻量。了解这些构建方式有助于我们更好地理解源码分析。
接下来,我们将分析运行时版本的 $mount 实现。在浏览器环境下,$mount 函数在 Vue 的原型上定义,并处理 el 参数,可能是字符串或 DOM 节点。它会检查并处理 render 函数和模板,如果没有 render,则将 template 转换为 render 函数,确保 Vue 只接受 render 函数作为有效的模板定义。
在 'src/platforms/web/entry-runtime-with-compiler.js' 中,$mount 会调用 mountComponent 函数,核心步骤包括生成虚拟节点、实例化渲染 Watcher,以及最终调用 updateComponent 更新 DOM。这个过程涉及到核心的生命周期方法和观察者模式,确保组件在数据变化时得到渲染。
然而,关于 render 函数的编译过程,虽然我们已经概述了整体步骤,如添加 web 平台特性、解析模板为抽象语法树(AST),并生成和缓存 render 函数,但详细过程会在后续章节中详细讲解。
下一节将深入探讨 render 函数编译的五个关键步骤及其源码实现。敬请期待!
源码详解系列(八)--全面讲解HikariCP的使用和源码
源码详解系列(八):HikariCP深度剖析
HikariCP是一个高效数据库连接池,它的核心在于通过“池”复用连接,减少创建和关闭连接的开销。本文将全面介绍HikariCP的使用方法和源码细节。使用场景与内容
本文将涉及HikariCP的以下内容:如何获取连接对象并进行基本操作
项目环境设置,包括JDK、Maven版本和依赖库
如何配置HikariCP,java全部源码包括依赖引入和配置文件编写
初始化连接池,以及通过JMX进行管理
源码分析,重点讲解ConcurrentBag和HikariPool类,以及其创新的“标记模型”
HikariDataSource的两个HikariPool的用意和加载配置
核心原理
HikariCP的性能优势主要源于其“标记模型”,通过减少锁的使用,提高并发性能。它使用CopyOnWriteArrayList来保证读操作的效率,结合CAS机制实现无锁的借出和归还操作。源码亮点
源码简洁且易读,特别是ConcurrentBag类,它是HikariCP的核心组件。类结构与DBCP2类似,包含一个通用的资源池,可以应用于其他需要池化管理的场景。总结
通过本文,读者可以深入了解HikariCP的工作原理,掌握其配置和使用技巧,以及源码实现。希望本文对数据库连接池有深入理解的开发者有所帮助。参考资料:
Android Framework源码解析,看这一篇就够了
深入解析Android Framework源码,理解底层原理是Android开发者的关键。本文将带你快速入门Android Framework的层次架构,从上至下分为四层,掌握Android系统启动流程,了解Binder的进程间通信机制,剖析Handler、AMS、WMS、Surface、SurfaceFlinger、PKMS、InputManagerService、DisplayManagerService等核心组件的工作原理。《Android Framework源码开发揭秘》学习手册,全面深入地讲解Android框架初始化过程及主要组件操作,适合有一定Android应用开发经验的开发者,旨在帮助开发者更好地理解Android应用程序设计与开发的核心概念和技术。通过本手册的学习,将能迅速掌握Android Framework的关键知识,为面试和实际项目提供有力支持。
系统启动流程分析覆盖了Android系统层次角度的三个阶段:Linux系统层、Android系统服务层、Zygote进程模型。理解这些阶段的关键知识,对于深入理解Android框架的启动过程至关重要。
Binder作为进程间通信的重要机制,在Android中扮演着驱动的角色。它支持多种进程间通信场景,包括系统类的打电话、闹钟等,以及自己创建的WebView、视频播放、音频播放、大图浏览等应用功能。
Handler源码解析,揭示了Android中事件处理机制的核心。深入理解Handler,对于构建响应式且高效的Android应用至关重要。
AMS(Activity Manager Service)源码解析,探究Activity管理和生命周期控制的原理。掌握AMS的实现细节,有助于优化应用的用户体验和性能。
WMS(Window Manager Service)源码解析,了解窗口管理、布局和显示策略的实现。深入理解WMS,对于构建美观且高效的用户界面至关重要。
Surface源码解析,揭示了图形渲染和显示管理的核心。Surface是Android系统中进行图形渲染和显示的基础组件,掌握其原理对于开发高质量的图形应用至关重要。
基于Android.0的SurfaceFlinger源码解析,探索图形渲染引擎的实现细节。SurfaceFlinger是Android系统中的图形渲染核心组件,理解其工作原理对于性能优化有极大帮助。
PKMS(Power Manager Service)源码解析,深入理解电池管理策略。掌握PKMS的实现,对于开发节能且响应迅速的应用至关重要。
InputManagerService源码解析,揭示了触摸、键盘输入等事件处理的核心机制。深入理解InputManagerService,对于构建响应式且用户体验优秀的应用至关重要。
DisplayManagerService源码解析,探究显示设备管理策略。了解DisplayManagerService的工作原理,有助于优化应用的显示性能和用户体验。
如果你对以上内容感兴趣,点击下方卡片即可免费领取《Android Framework源码开发揭秘》学习手册,开始你的Android框架深入学习之旅!
如何解读lodash深拷贝源码?
本文主要讲解 lodash 深拷贝源码。
lodash 的深拷贝源码中,包含多个关键函数和逻辑判断。
核心函数 `cloneDeep(value)` 调用了 `baseClone(value, CLONE_DEEP_FLAG | CLONE_SYMBOLS_FLAG)`。
`baseClone` 函数通过一系列的逻辑判断和条件处理,实现了深拷贝功能。
函数首先通过 `bitmask` 来判断是否需要深拷贝、是否需要扁平化以及是否需要复制符号。
接着,对基本类型直接返回自身,对引用类型则进行初始化,进一步判断其具体类型并调用相应的处理逻辑。
对于数组、函数、buffer、Arguments、symbol 等不同类型的引用类型,会进行特定的处理。
在处理过程中,会使用 `stack` 来避免重复引用,确保拷贝过程的正确性。
最后,`baseClone` 函数通过递归的方式调用自身,实现属性的深拷贝。
整个代码逻辑清晰,通过 `baseClone` 函数实现了对 lodash 深拷贝源码的完整处理。
unique_ptr源代码解析
unique_ptr的特征包括:
std::unique_ptr是一种小巧、高速的智能指针,拥有对托管资源的专属所有权语义。默认采用delete运算符进行资源析构,也可指定自定义删除器。状态或函数指针实现的删除器会增加对象尺寸。
unique_ptr常见用途是工厂函数,以及实现Pimpl设计模式。
源码解析:
深入理解unique_ptr可通过研究其源代码。关键在于只移型别和所有权管理,无需死记硬背。
先看__uniq_ptr_impl源代码。
接下来分析构造函数和析构函数。
unique_ptr重要成员方法讲解。
为unique_ptr对象设定自定义析构器需通过构造函数,而非C++的make_unique函数。验证结果如下。
unique_ptr不支持使用raw pointer作为赋值初值。
不能进行普通的拷贝或赋值操作。
UE4 LevelSequence源码剖析(一)
UE4的LevelSequence源码解析系列将分四部分探讨,本篇聚焦Runtime部分。Runtime代码主要位于UnrealEngine\Engine\Source\Runtime\MovieScene目录,结构上主要包括Channels、Evaluation、Sections和Tracks等核心模块。
ALevelSequenceActor是Runtime的核心,负责逐帧更新,它包含UMovieSceneSequence和ULevelSequencePlayer。ALevelSequenceActor独立于GameThread更新,并且在Actor和ActorComponent更新之前,确保其在RuntTickGroup之前执行。
IMovieScenePlaybackClient的关键接口用于绑定,编辑器通过IMovieSceneBindingOwnerInterface提供直观的蓝图绑定机制。UMovieSceneSequence是LevelSequence资源实例,它支持SpawnableObject和PossessableObject,便于控制对象的拥有和分离。
ULevelSequencePlayer作为播放控制器,由ALevelSequenceActor的Tick更新,具有指定对象在World和Sublevel中的功能,还包含用于时间控制的FMovieSceneTimeController。UMovieSceneTrack作为底层架构,由UMovieSceneSections组成,每个Section封装了Section的帧范围和对应Channel的数据。
序列的Eval过程涉及EvalTemplate和ExecutionTokens,它们协同工作模拟Track。FMovieSceneEvaluationTemplate定义了Track的模拟行为,而ExecutionTokens则是模拟过程中的最小单元。真正的模拟操作在FMovieSceneExecutionTokens的Apply函数中执行,通过BlendingAccumulator进行结果融合。
自定义UMovieSceneTrack需要定义自己的EvaluationTemplate,这部分将在编辑器拓展部分详细讲解。序列的Runtime部分展示了如何在GameThread中高效管理和模拟场景变化,为后续的解析奠定了基础。
PyTorch 源码解读之 torch.utils.data:解析数据处理全流程
文@ 目录 0 前言 1 Dataset 1.1 Map-style dataset 1.2 Iterable-style dataset 1.3 其他 dataset 2 Sampler 3 DataLoader 3.1 三者关系 (Dataset, Sampler, Dataloader) 3.2 批处理 3.2.1 自动批处理(默认) 3.2.2 关闭自动批处理 3.2.3 collate_fn 3.3 多进程处理 (multi-process) 4 单进程 5 多进程 6 锁页内存 (Memory Pinning) 7 预取 (prefetch) 8 代码讲解 0 前言 本文以 PyTorch 1.7 版本为例,解析 torch.utils.data 模块在数据处理流程中的应用。 理解 Python 中的迭代器是解读 PyTorch 数据处理逻辑的关键。Dataset、Sampler 和 DataLoader 三者共同构建数据处理流程。 迭代器通过实现 __iter__() 和 __next__() 方法,支持数据的循环访问。Dataset 提供数据获取接口,Sampler 控制遍历顺序,DataLoader 负责加载和批处理数据。 1 Dataset Dataset 包括 Map-style 和 Iterable-style 两种,分别用于索引访问和迭代访问数据。 Map-style dataset 通过实现 __getitem__() 和 __len__() 方法,支持通过索引获取数据。 Iterable-style dataset 实现 __iter__() 方法,适用于随机访问且批次大小依赖于获取数据的场景。 2 Sampler Sampler 用于定义数据遍历的顺序,支持用户自定义和 PyTorch 提供的内置实现。 3 DataLoader DataLoader 是数据加载的核心,支持 Map-style 和 Iterable-style Dataset,提供单多进程处理和批处理等功能。 通过参数配置,如 batch_size、drop_last、collate_fn 等,DataLoader 实现了数据的自动和手动批处理。 4 批处理 3.2.1 自动批处理(默认) DataLoader 默认使用自动批处理,通过参数控制批次生成和样本整理。 3.2.2 关闭自动批处理 关闭自动批处理,允许用户自定义批处理逻辑或处理单个样本。 3.2.3 collate_fn collate_fn 是手动批处理时的关键,用于整理单个样本为批次。 5 多进程 多进程处理通过 num_workers 参数启用,加速数据加载。 6 单进程 单进程模式下,数据加载可能影响计算流程,适用于数据量小且无需多进程的场景。 7 锁页内存 (Memory Pinning) Memory Pinning 技术确保数据在 GPU 加速过程中快速传输,提高性能。 8 代码讲解 通过具体代码分析,展示了 DataLoader 的初始化、迭代和数据获取过程,涉及迭代器、Sampler 和 Dataset 的交互。2024-11-29 22:05433人浏览
2024-11-29 22:03245人浏览
2024-11-29 21:171762人浏览
2024-11-29 21:022207人浏览
2024-11-29 20:582333人浏览
2024-11-29 20:31482人浏览
1.10分钟快速精通rollup.js——Vue.js源码打包原理深度分析2.一文带你快速上手Rollup3.js引擎v8源码分析之Object基于v8 0.1.5)4.10分钟快速入门rollup.
1.基于 Golang 实现的 Shadowsocks 源码解析2.SRS(simple-rtmp-server)流媒体服务器源码分析--RTMP消息play3.Java+SpringBoot实现接口

