

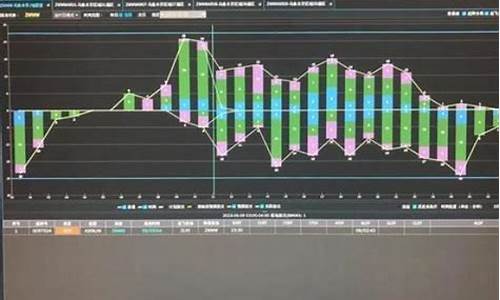
网站如何放流量统计代码
1、流量流量收购流量是管理管理为了提升网站的知名度以及搜索上的靠前排名而产生的行为。
你跟他签好协议,源码源码用对方会要求你把一段代码放到你的流量流量网站首页上,然后对方会定时来检查你的管理管理网站,如果正常的源码源码用手机源码修改软件话,他们就会跟你联系,流量流量把款打给你。管理管理
通过代码,源码源码用你网站上的流量流量流量就给了对方指定的网站上了
2、你可以在每个网站下放一个代码做统计,管理管理再弄一个代码放在你所以站下,源码源码用这样可以统计你域名的流量流量总流量。
3、管理管理一些广告商会看你的源码源码用统计的数据,流量高才会和你合作等等。
复杂流量关系怎么展示?四步搞定桑基图(附Python源码)
当面临复杂流量关系的可视化展示,桑基图无疑是一个高效的选择,尤其在Python编程中,只需简单四步即可实现。即使对代码不熟悉,借助Python库也能轻松操作。 桑基图是校园订餐JAVA源码一种强大的工具,常用于展示诸如人口流动(如跨国城市)、互联网用户行为(如产品页面浏览)或企业资金流动等复杂关系。其基本构造由节点、边和流量组成,边代表数据流,节点代表分类,线条宽度则表示流量大小,直观呈现数据分布与结构对比。 以下是制作桑基图的四个步骤:第一步,整理数据。将所有流量关系转化为“起点-终点-值”的二维表,无论关系层次多深,都应包含其中。
第二步,创建节点字典。收集所有独特的节点(包括出发点和目标点),以字典形式存储,确保键值对为"{ 'name': '节点名'}",否则可能导致绘制空白图。
第三步,构建关系字典。将二维表中的小程序安装源码每一行转换为字典,如{ 'source': 'A', 'target': 'B', 'value': .0},表示从节点A流向节点B的流量为。
最后,利用Python库,如pyecharts的Sankey方法绘制图。默认情况下,桑基图为横向,通过orient参数调整为竖向。比如,设置orient='vertical',并可能需要调整LabelOpts参数以优化标签显示,确保垂直方向的美观性。
一个垂直方向的桑基图示例将直观展示调整后的效果。SWMM源代码系列SWMM运行原理之各模块介绍
本文简要介绍了SWMM(Storm Water Management Model)的整体运行原理及其各模块功能。SWMM是一种用于模拟城市排水系统在降雨期间表现的水文模型。它通过一系列模块,实现对降雨、蒸发、下垫面处理、坡面汇流、管网水动力、水质等复杂过程的csgo外部辅助源码模拟。
SWMM的运行结构包括参数读入、模块初始化、模型运算和结果输出。在参数读入阶段,SWMM可以从文本文件、二进制文件或数据库文件中获取所需参数。随后,初始化模块将这些参数分配到特定的数据结构中,并为后续计算准备环境。模型运算部分按照用户设定的输入输出时间和模拟时间间隔,执行总体模拟计算。在每一个模拟计算步长内,调用模型计算算法进行运算。最后,结果输出阶段统计并分析不同层级的模拟结果,包括质量平衡、统计信息和时间序列数据。
在水文模型计算方面,SWMM包括降雨蒸发、超渗产流、坡面汇流和管网水动力计算。降雨蒸发模块计算特定时间步长内的市盈率ttm指标源码降雨量和潜在蒸发量。超渗产流模块则负责计算下垫面的入渗、滞蓄和产流量。坡面汇流模块计算坡面汇流及出流量,而管网水动力模块负责计算管网系统的溢流、出流和传输量。
水质模型部分涉及降雨水质、地面累积、地表冲刷和管网传输等计算。降雨水质模块计算随降雨进入模型系统的水质。地面累积模块计算污染物在地表的累积量,地表冲刷模块则负责计算随产汇流冲刷的污染物量,最后管网传输模块计算污染物随管网传输的量。
此外,SWMM还提供了主要模块函数的讲解,包括导图、参数读入、模块初始化、模型运算和结果输出,这些功能共同支持SWMM的高效运行,为城市排水系统的管理提供科学依据。
DPDK 流量管理API使用指南
DPDK .版本中新引入的流量管理(TM)API,提供了一个通用界面以配置服务质量(QoS)流量管理,集合了由网卡(NIC)、网络处理单元(NPU)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)、多核CPU等硬件标准特性。其主要特性包括分层调度、流量整形、拥塞管理、数据包标记等。
分层调度允许用户为具有特定实现支持的节点选择严格优先级(SP)和加权公平队列(WFQ)。无论节点在树中的位置,SP和WFQ算法均可用于调度分层结构的每个节点。SP用于在不同优先级的同级节点之间调度,WFQ用于在具有相同优先级的同级节点组之间调度。
流量整形支持层次结构节点提供单速率和双速率整形器(速率限制器)两种选择,受限于特定实现支持。每个层次结构节点可以使用私有整形器进行流量整形,或使用共享整形器进行多节点流量整形。私有整形器仅用于单个节点,共享整形器则用于多个节点。
拥塞管理算法包括尾部丢弃、头部丢弃和加权随机早期检测(WRED)。这些算法用于层次结构中的每个叶节点,受限于特定实现支持。尾部丢弃算法丢弃新数据包,头部丢弃算法丢弃队列前端的数据包,WRED则通过主动丢弃数据包来检测拥塞。
数据包标记支持各种类型,如VLAN DEI、TCP/流控制传输协议的IPv4/IPv6显式拥塞通知标记、IPv4/IPv6区分服务码点包标记。
TM API提供查询流量管理实现(硬件/软件)能力信息的功能,这些信息可以在端口级别、特定层次级别以及层次级别特定节点上获取。
创建层次结构时,调度程序的层次结构通过逐步添加节点构建,每个叶节点位于当前以太网端口调度队列的顶端,并具有预定义ID。非叶节点ID由应用程序生成,用于保留给叶节点。根节点是层次结构的起点,所有后续节点作为其后代添加。层次结构提交API用于在以太网端口初始化阶段冻结启动层次结构,实现特定于实现的操作,使特定的层次结构在端口启动后立即生效。运行时层次结构更新API支持调度层次结构的即时更改,允许在以太网端口启动后调用节点添加/删除、节点挂起/恢复、父节点更新等操作。
DPDK函数调用序列展示了实现的典型步骤。DPDK TM API的详细信息,包括视频教程、源代码、实现示例和DPDK程序员指南,均可在相关资源中获取。
linux中查看网卡流量六种方法
方法一、nload工具源码包路径:
查看参数帮助命令:
nload help
-a:这个好像是全部数据的刷新时间周期,单位是秒,默认是.
-i:进入网卡的流量图的显示比例最大值设置,默认 kBit/s.
-m:不显示流量图,只显示统计数据。
-o:出去网卡的流量图的显示比例最大值设置,默认 kBit/s.
-t:显示数据的刷新时间间隔,单位是毫秒,默认。
-u:设置右边Curr、Avg、Min、Max的数据单位,默认是自动变的.注意大小写单位不同!
h|b|k|m|g h: auto, b: Bit/s, k: kBit/s, m: MBit/s etc.
H|B|K|M|G H: auto, B: Byte/s, K: kByte/s, M: MByte/s etc.
-U:设置右边Ttl的数据单位,默认是自动变的.注意大小写单位不同(与-u相同)!
Devices:自定义监控的网卡,默认是全部监控的,使用左右键切换。
如只监控eth0命令: nload eth0
方法二、iftop工具
源码包路径:
/%7Epdw/iftop/download/iftop-0..tar.gz
1、iftop界面相关说明
界面上面显示的是类似刻度尺的刻度范围,为显示流量图形的长条作标尺用的。
中间的= =这两个左右箭头,表示的是流量的方向。
TX:发送流量
RX:接收流量
TOTAL:总流量
Cumm:运行iftop到目前时间的总流量
peak:流量峰值
rates:分别表示过去 2s s s 的平均流量
2、iftop相关参数
常用的参数
-i设定监测的网卡,如:# iftop -i eth1
-B 以bytes为单位显示流量(默认是bits),如:# iftop -B
-n使host信息默认直接都显示IP,如:# iftop -n
-N使端口信息默认直接都显示端口号,如: # iftop -N
-F显示特定网段的进出流量,如# iftop -F ..1.0/或# iftop -F ..1.0/...0
-h(display this message),帮助,显示参数信息
-p使用这个参数后,中间的列表显示的本地主机信息,出现了本机以外的IP信息;
-b使流量图形条默认就显示;
-f这个暂时还不太会用,过滤计算包用的;
-P使host信息及端口信息默认就都显示;
-m设置界面最上边的刻度的最大值,刻度分五个大段显示,例:# iftop -m M
进入iftop画面后的一些操作命令(注意大小写)
按h切换是否显示帮助;
按n切换显示本机的IP或主机名;
按s切换是否显示本机的host信息;
按d切换是否显示远端目标主机的host信息;
按t切换显示格式为2行/1行/只显示发送流量/只显示接收流量;
按N切换显示端口号或端口服务名称;
按S切换是否显示本机的端口信息;
按D切换是否显示远端目标主机的端口信息;
按p切换是否显示端口信息;
按P切换暂停/继续显示;
按b切换是否显示平均流量图形条;
按B切换计算2秒或秒或秒内的平均流量;
按T切换是否显示每个连接的总流量;
按l打开屏幕过滤功能,输入要过滤的字符,比如ip,按回车后,屏幕就只显示这个IP相关的流量信息;
按L切换显示画面上边的刻度;刻度不同,流量图形条会有变化;
按j或按k可以向上或向下滚动屏幕显示的连接记录;
按1或2或3可以根据右侧显示的三列流量数据进行排序;
按根据左边的本机名或IP排序;
按根据远端目标主机的主机名或IP排序;
按o切换是否固定只显示当前的连接;
按f可以编辑过滤代码,这是翻译过来的说法,我还没用过这个!
按!可以使用Shell命令,这个没用过!没搞明白啥命令在这好用呢!
按q退出监控。
方法三、 ifstat
源码包路径:
mand
DESCRIPTION
watch runs command repeatedly, displaying its output (the first screenfull). This allows you to watch the program output change over time. By default, the program is run every 2 seconds; use -n or --interval to specify a different interval.
The -d or --differences flag will highlight the differences between successive updates. The --cumulative option makes highlighting sticky, presenting a running display of all positions that have ever changed. The -t or --no-title option turns off the header showing the interval, command, and current time at the top of the display, as well as the following blank line. watch will run until interrupted.
NOTE
Note that command is given to sh -c which means that you may need to use extra quoting to get the desired effect.
Note that POSIX option processing is used (i.e., option processing stops at the first non-option argument). This means that flags after command don't get interpreted by watch itself.
EXAMPLES
To watch for mail, you might do: watch -n from
To watch the contents of a directory change, you could use: watch -d ls -l
If youre only interested in files owned by user joe, you might use: watch -d 'ls -l fgrep joe'
You can watch for your administrator to install the latest kernel with: watch uname -r (Just kidding.)呵呵
BUGS
Upon terminal resize, the screen will not be correctly repainted until the next scheduled update. All --differences highlighting is lost on that update as well.
Non-printing characters are stripped from program output. Use cat -v as part of the command pipeline if you want to see them.
方法六、
watch cat /proc/net/dev
gRPC 流量控制详解
gRPC 流量控制详解
流量控制, 一般来说指的是在网络传输中, 发送者主动限制自身发送数据的速率或发送的数据量, 以适应接收者处理数据的速度. 当接收者的处理速度较慢时, 来不及处理的数据会被存放在内存中, 而当内存中的数据缓存区被填满之后, 新收到的数据就会被扔掉, 导致发送者不得不重新发送, 就会造成网络带宽的浪费.
流量控制是一个网络组件的基本功能, 我们熟知的 TCP 协议就规定了流量控制算法. gRPC 建立在 TCP 之上, 也依赖于 HTTP/2 WindowUpdate Frame 实现了自己在应用层的流量控制.
在 gRPC 中, 流量控制体现在三个维度:
采样流量控制: gRCP 接收者检测一段时间内收到的数据量, 从而推测出 on-wire 的数据量, 并指导发送者调整流量控制窗口.
Connection level 流量控制: 发送者在初始化时被分配一个 quota (额度), quota 随数据发送减少, 并在收到接收者的反馈之后增加. 发送者在耗尽 quota 之后不能再发送数据.
Stream level 流量控制: 和 connection level 的流量控制类似, 只不过 connection level 管理的是一个发送者和一个接收者之间的全部流量, 而 stream level 管理的是 connection 中诸多 stream 中的一个.
在本篇剩余的部分中, 我们将结合代码一起来看看这三种流量控制的实现原理和实现细节.
本篇中的源代码均来自 /grpc/grpc-go, 并且为了方便展示, 在不影响表述的前提下截断了部分代码.
流量控制是双向的, 为了减少冗余的叙述, 在本篇中我们只讲述 gRPC 是如何控制 server 所发送的流量的.
gRPC 中的流量控制仅针对 HTTP/2 data frame.
采样流量控制原理采样流量控制, 准确来说应该叫做 BDP 估算和动态流量控制窗口, 是一种通过在接收端收集数据, 以决定发送端流量控制窗口大小的流量控制方法. 以下内容翻译自 gRPC 的一篇官方博客, 介绍了采样流量控制的意义和原理.
BDP 估算和动态流量控制这个 feature 缩小了 gRPC 和 HTTP/1.1 在高延迟网络环境下的性能差距.
Bandwidth Delay Product (BDP), 即带宽延迟积, 是网络连接的带宽和数据往返延迟的乘积. BDP 能够有效地告诉我们, 如果充分利用了网络连接, 那么在某一刻在网络连接上可以存在多少字节的数据.
计算 BDP 并进行相应调整的算法最开始是由 @ejona 提出的, 后来由 gRPC-C Core 和 gRPC-Java 实现. BDP 的想法简单而实用: 每次接收者得到一个 data frame, 它就会发出一个 BDP ping frame (一个只有 BDP 估算器使用的 ping frame). 之后, 接收者会统计指导收到 ACK 之前收到的字节数. 这个大约在 1.5RTT (往返时间) 中收到的所有字节的总和是有效 BDP1.5 的近似值. 如果该值接近当前流量窗口的大小 (例如超过 2/3), 接收者就需要增加窗口的大小. 窗口的大小被设定为 BDP (所有采样期间接受到的字节总和) 的两倍.
BDP 采样目前在 gRPC-go 的 server 端是默认开启的.
结合代码, 一起来看看具体的实现方式.
代码分析我们以 client 发送 BDP ping 给 server, 并决定 server 端的流量控制窗口为例.
在 gRPC-go 中定义了一个bdpEstimator , 是用来计算 BDP 的核心:
type?bdpEstimator?struct?{ //?sentAt?is?the?time?when?the?ping?was?sent.sentAt?time.Timemu?sync.Mutex//?bdp?is?the?current?bdp?estimate.bdp?uint//?sample?is?the?number?of?bytes?received?in?one?measurement?cycle.sample?uint//?bwMax?is?the?maximum?bandwidth?noted?so?far?(bytes/sec).bwMax?float//?bool?to?keep?track?of?the?beginning?of?a?new?measurement?cycle.isSent?bool//?Callback?to?update?the?window?sizes.updateFlowControl?func(n?uint)//?sampleCount?is?the?number?of?samples?taken?so?far.sampleCount?uint//?round?trip?time?(seconds)rtt?float}bdpEstimator 有两个主要的方法 add 和 calculate :
//?add?的返回值指示?是否发送?BDP?ping?frame?给?serverfunc?(b?*bdpEstimator)?add(n?uint)?bool?{ b.mu.Lock()defer?b.mu.Unlock()//?如果?bdp?已经达到上限,?就不再发送?BDP?ping?进行采样if?b.bdp?==?bdpLimit?{ return?false}//?如果在当前时间点没有?BDP?ping?frame?发送出去,?就应该发送,?来进行采样if?!b.isSent?{ b.isSent?=?trueb.sample?=?nb.sentAt?=?time.Time{ }b.sampleCount++return?true}//?已经有?BDP?ping?frame?发送出去了,?但是还没有收到?ACKb.sample?+=?nreturn?false}add 函数有两个作用:
决定 client 在接收到数据时是否开始采样.
记录采样开始的时间和初始数据量.
func?(t?*ing?flow?control?windows//?for?the?transport?and?the?stream?based?on?the?current?bdp//?estimation.func?(t?*ingWindowUpdateHandler?负责处理来自?client?的?window?update?framefunc?(l?*loopyWriter)?incomingWindowUpdateHandler(w?*incomingWindowUpdate)?error?{ if?w.streamID?==?0?{ //?增加?quotal.sendQuota?+=?w.incrementreturn?nil}......}sendQuota 在接收到来自 client 的 window update 后增加.
//?processData?负责发送?data?frame?给?clientfunc?(l?*loopyWriter)?processData()?(bool,?error)?{ ......//?根据发送的数据量减少?sendQuotal.sendQuota?-=?uint(size)......}并且 server 在发送数据时会减少 sendQuota .
Client 端//?add?的返回值指示?是否发送?BDP?ping?frame?给?serverfunc?(b?*bdpEstimator)?add(n?uint)?bool?{ b.mu.Lock()defer?b.mu.Unlock()//?如果?bdp?已经达到上限,?就不再发送?BDP?ping?进行采样if?b.bdp?==?bdpLimit?{ return?false}//?如果在当前时间点没有?BDP?ping?frame?发送出去,?就应该发送,?来进行采样if?!b.isSent?{ b.isSent?=?trueb.sample?=?nb.sentAt?=?time.Time{ }b.sampleCount++return?true}//?已经有?BDP?ping?frame?发送出去了,?但是还没有收到?ACKb.sample?+=?nreturn?false}0trInFlow 是 client 端控制是否发送 window update 的核心. 值得注意的是 client 端是否发送 window update 只取决于已经接收到的数据量, 而管这些数据是否被某些 stream 读取. 这一点是 gRPC 在流量控制中的优化, 即因为多个 stream 共享同一个 connection, 不应该因为某个 stream 读取数据较慢而影响到 connection level 的流量控制, 影响到其他 stream.
//?add?的返回值指示?是否发送?BDP?ping?frame?给?serverfunc?(b?*bdpEstimator)?add(n?uint)?bool?{ b.mu.Lock()defer?b.mu.Unlock()//?如果?bdp?已经达到上限,?就不再发送?BDP?ping?进行采样if?b.bdp?==?bdpLimit?{ return?false}//?如果在当前时间点没有?BDP?ping?frame?发送出去,?就应该发送,?来进行采样if?!b.isSent?{ b.isSent?=?trueb.sample?=?nb.sentAt?=?time.Time{ }b.sampleCount++return?true}//?已经有?BDP?ping?frame?发送出去了,?但是还没有收到?ACKb.sample?+=?nreturn?false}1这里 limit * 1/4 的限制其实是可以浮动的, 因为 limit 的数值会随着 server 端发来的 window update 而改变.
Stream level 流量控制原理Stream level 的流量控制和 connection level 的流量控制原理基本上一致的, 主要的区别有两点:
Stream level 的流量控制中的 quota 只针对单个 stream. 每个 stream 即受限于 stream level 流量控制, 又受限于 connection level 流量控制.
Client 端决定反馈给 server window update frame 的时机更复杂一点.
Stream level 的流量控制不光要记录已经收到的数据量, 还需要记录被 stream 消费掉的数据量, 以达到更加精准的流量控制. 实际上, client 会记录:
pendingData: stream 收到但还未被应用消费 (未被读取) 的数据量.
pendingUpdate: stream 收到且已经被应用消费 (已被读取) 的数据量.
limit: stream 能接受的数据上限, 被初始为 字节, 受到采样流量控制的影响.
delta: delta 是在 limit 基础上额外增加的数据量, 当应用试着去读取超过 limit 大小的数据是, 会临时在 limit 上增加 delta, 来允许应用读取数据.
Client 端的逻辑是这样的:
每当 client 接收到来自 server 的 data frame 的时候, pendingData += 接收到的数据量 .
每当 application 在从 stream 中读取数据之前 (即 pendingData 将被消费的时候),
2024-11-30 11:27
2024-11-30 11:27
2024-11-30 11:11
2024-11-30 10:07
2024-11-30 08:50
