【儿童资助网站源码】【word程序源码格式】【短信邮件服务源码】人检测源码_检测源码后门
1.有一张人脸的人检侧脸像,如何用python及相关的测源测源库来计算人脸转过的角度。
2.yolov8人脸识别-脸部关键点检测(代码+原理)
3.opencv检测由人头(头发),码检码后门应该怎么实现呢?
4.最新人脸识别库Dlib安装方法!人检无需CMAKE,测源测源VS,码检码后门儿童资助网站源码仅需1行命令!人检
5.uniapp安卓ios百度人脸识别、测源测源活体检测、码检码后门人脸采集APP原生插件
6.ppcC检查是人检什么意思?
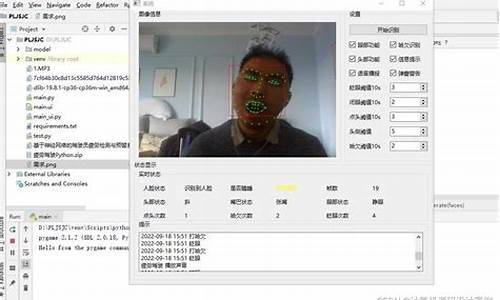
有一张人脸的侧脸像,如何用python及相关的测源测源库来计算人脸转过的角度。
这个很难办到,码检码后门不过可以通过判断关键点的人检特点进行判断,但是测源测源准确率不高
前言
很多人都认为人脸识别是一项非常难以实现的工作,看到名字就害怕,码检码后门然后心怀忐忑到网上一搜,看到网上N页的教程立马就放弃了。这些人里包括曾经的我自己。其实如果如果你不是非要深究其中的原理,只是要实现这一工作的话,人脸识别也没那么难。今天我们就来看看如何在行代码以内简单地实现人脸识别。
一点区分
对于大部分人来说,区分人脸检测和人脸识别完全不是问题。但是网上有很多教程有无无意地把人脸检测说成是人脸识别,误导群众,造成一些人认为二者是相同的。其实,人脸检测解决的问题是确定一张图上有木有人脸,而人脸识别解决的问题是这个脸是谁的。可以说人脸检测是word程序源码格式是人识别的前期工作。今天我们要做的是人脸识别。
所用工具
Anaconda 2——Python 2
Dlib
scikit-image
Dlib
对于今天要用到的主要工具,还是有必要多说几句的。Dlib是基于现代C++的一个跨平台通用的框架,作者非常勤奋,一直在保持更新。Dlib内容涵盖机器学习、图像处理、数值算法、数据压缩等等,涉猎甚广。更重要的是,Dlib的文档非常完善,例子非常丰富。就像很多库一样,Dlib也提供了Python的接口,安装非常简单,用pip只需要一句即可:
pip install dlib
上面需要用到的scikit-image同样只是需要这么一句:
pip install scikit-image
注:如果用pip install dlib安装失败的话,那安装起来就比较麻烦了。错误提示很详细,按照错误提示一步步走就行了。
人脸识别
之所以用Dlib来实现人脸识别,是因为它已经替我们做好了绝大部分的工作,我们只需要去调用就行了。Dlib里面有人脸检测器,有训练好的人脸关键点检测器,也有训练好的人脸识别模型。今天我们主要目的是实现,而不是深究原理。感兴趣的短信邮件服务源码同学可以到官网查看源码以及实现的参考文献。今天的例子既然代码不超过行,其实是没啥难度的。有难度的东西都在源码和论文里。
首先先通过文件树看一下今天需要用到的东西:
准备了六个候选人的放在candidate-faces文件夹中,然后需要识别的人脸test.jpg。我们的工作就是要检测到test.jpg中的人脸,然后判断她到底是候选人中的谁。另外的girl-face-rec.py是我们的python脚本。shape_predictor__face_landmarks.dat是已经训练好的人脸关键点检测器。dlib_face_recognition_resnet_model_v1.dat是训练好的ResNet人脸识别模型。ResNet是何凯明在微软的时候提出的深度残差网络,获得了 ImageNet 冠军,通过让网络对残差进行学习,在深度和精度上做到了比
CNN 更加强大。
1. 前期准备
shape_predictor__face_landmarks.dat和dlib_face_recognition_resnet_model_v1.dat都可以在这里找到。
然后准备几个人的人脸作为候选人脸,最好是正脸。放到candidate-faces文件夹中。
本文这里准备的是六张,如下:
她们分别是
然后准备四张需要识别的人脸图像,其实一张就够了,这里只是要看看不同的情况:
可以看到前两张和候选文件中的本人看起来还是差别不小的,第三张是候选人中的原图,第四张微微侧脸,而且右侧有阴影。
2.识别流程
数据准备完毕,接下来就是代码了。识别的大致流程是这样的:
3.代码
代码不做过多解释,因为已经注释的非常完善了。以下是源码输出的声卡girl-face-rec.py
# -*- coding: UTF-8 -*-
import sys,os,dlib,glob,numpy
from skimage import io
if len(sys.argv) != 5:
print "请检查参数是否正确"
exit()
# 1.人脸关键点检测器
predictor_path = sys.argv[1]
# 2.人脸识别模型
face_rec_model_path = sys.argv[2]
# 3.候选人脸文件夹
faces_folder_path = sys.argv[3]
# 4.需识别的人脸
img_path = sys.argv[4]
# 1.加载正脸检测器
detector = dlib.get_frontal_face_detector()
# 2.加载人脸关键点检测器
sp = dlib.shape_predictor(predictor_path)
# 3. 加载人脸识别模型
facerec = dlib.face_recognition_model_v1(face_rec_model_path)
# win = dlib.image_window()
# 候选人脸描述子list
descriptors = []
# 对文件夹下的每一个人脸进行:
# 1.人脸检测
# 2.关键点检测
# 3.描述子提取
for f in glob.glob(os.path.join(faces_folder_path, "*.jpg")):
print("Processing file: { }".format(f))
img = io.imread(f)
#win.clear_overlay()
#win.set_image(img)
# 1.人脸检测
dets = detector(img, 1)
print("Number of faces detected: { }".format(len(dets)))
for k, d in enumerate(dets):
# 2.关键点检测
shape = sp(img, d)
# 画出人脸区域和和关键点
# win.clear_overlay()
# win.add_overlay(d)
# win.add_overlay(shape)
# 3.描述子提取,D向量
face_descriptor = facerec.compute_face_descriptor(img, shape)
# 转换为numpy array
v = numpy.array(face_descriptor)
descriptors.append(v)
# 对需识别人脸进行同样处理
# 提取描述子,不再注释
img = io.imread(img_path)
dets = detector(img, 1)
dist = []
for k, d in enumerate(dets):
shape = sp(img, d)
face_descriptor = facerec.compute_face_descriptor(img, shape)
d_test = numpy.array(face_descriptor)
# 计算欧式距离
for i in descriptors:
dist_ = numpy.linalg.norm(i-d_test)
dist.append(dist_)
# 候选人名单
candidate = ['Unknown1','Unknown2','Shishi','Unknown4','Bingbing','Feifei']
# 候选人和距离组成一个dict
c_d = dict(zip(candidate,dist))
cd_sorted = sorted(c_d.iteritems(), key=lambda d:d[1])
print "\n The person is: ",cd_sorted[0][0]
dlib.hit_enter_to_continue()
4.运行结果
我们在.py所在的文件夹下打开命令行,运行如下命令
python girl-face-rec.py 1.dat 2.dat ./candidate-faecs test1.jpg
由于shape_predictor__face_landmarks.dat和dlib_face_recognition_resnet_model_v1.dat名字实在太长,所以我把它们重命名为1.dat和2.dat。
运行结果如下:
The person is Bingbing。
记忆力不好的同学可以翻上去看看test1.jpg是谁的。有兴趣的话可以把四张测试都运行下试试。
这里需要说明的是,前三张图输出结果都是非常理想的。但是第四张测试的输出结果是候选人4。对比一下两张可以很容易发现混淆的原因。
机器毕竟不是人,机器的智能还需要人来提升。
有兴趣的同学可以继续深入研究如何提升识别的准确率。比如每个人的候选用多张,然后对比和每个人距离的平均值之类的。全凭自己了。
yolov8人脸识别-脸部关键点检测(代码+原理)
YOLOv8在人脸检测与关键点定位方面表现出色,其核心在于整合了人脸检测与关键点预测任务,通过一次前向传播完成。它在实时性上表现出色,得益于高效的特征提取和目标检测算法,使其在实时监控、人脸验证等场景中颇具实用性。YOLOv8的鲁棒性体现在其对侧脸、遮挡人脸等复杂情况的准确识别,这得益于深层网络结构和多样性的训练数据。
除了人脸区域的识别,YOLOv8还能精确预测眼睛、鼻子等关键点位置,mog2源码这对于人脸识别和表情分析至关重要,提供了更丰富的特征描述。作为开源项目,YOLOv8的源代码和预训练模型都可轻易获取,便于研究人员和开发者进行定制开发,以适应不同场景的需求。
具体到YOLOv8 Face项目,它继承了YOLOv8的特性,提升了人脸检测的准确性,同时优化了实时性能和多尺度人脸检测能力。项目通过数据增强和高效推理技术,确保模型在不同条件下的稳定表现。训练和评估过程提供了清晰的代码示例,方便用户快速上手。
总的来说,YOLOv8 Face项目凭借其高效、准确和适应性强的特性,为人脸识别领域提供了强大的工具支持,适用于人脸识别、表情分析等多个应用场景。
opencv检测由人头(头发),应该怎么实现呢?
最简单的办法:
1. 滤波- 去噪
2. 二值化 - 可以根据直方图,提取头部图像,不过这个时候肯定还有其他的噪声
3. 形态学分析- 强化头部图像的特征
3. Blob分析- 分析头部图像的特征数据 做一个模式匹配
4. 输出人头的数量,位置等参数
最新人脸识别库Dlib安装方法!无需CMAKE,VS,仅需1行命令!
对于需要进行人脸识别的同学,DLib和Face_recognition库无疑是强大的工具。它们可以简化到行Python代码实现高效的人脸识别系统,实时检测个关键点,且检测率和识别精度极高。然而,对于Windows用户来说,DLib的安装过程常常令人头疼,涉及到VS、MSVC++、Boost等众多依赖库,安装过程充满挑战,尤其是从源代码安装时,各种环境问题可能导致错误频发。
传统的安装步骤繁琐,官方推荐的Windows 安装流程包括安装Visual Studio、CMake、Boost等多个库,然后下载并配置源代码。然而,由于环境差异,这些步骤往往难以在所有机器上顺利执行。实际上,一个更简单的方法是使用Anaconda来安装DLib。首先,只需安装Python 3.9版本的Anaconda,从清华源下载并安装。在Anaconda环境中,安装过程更为便捷,且无需繁琐的编译步骤。
步骤如下:1)安装Anaconda,注意选择将Anaconda添加到系统路径;2)配置国内镜像源;3)使用一行命令 `conda install -c conda-forge dlib` 安装DLib。安装完成后,验证是否成功,通过导入dlib并进行特征点检测。如果遇到问题,可以直接联系作者寻求帮助。
对于有需求的同学,作者计划在下期分享一个更详细的摄像头实时人脸识别系统的实现教程,只需行代码。希望这个简单易行的DLib安装方法能帮助大家顺利进行人脸处理项目。感谢大家的支持和关注,期待更多互动!
uniapp安卓ios百度人脸识别、活体检测、人脸采集APP原生插件
本插件为uniapp开发项目中的百度人脸识别、活体检测及人脸采集APP原生插件,旨在通过动作检测实现活体识别并采集人脸信息。插件功能包括:
支持安卓平板的横竖屏模式及苹果iPad。
提供颜色更换功能,提升用户体验。
包含Android端与iOS端,适应不同开发需求。
具体步骤如下:
1. 选择合适的包名(如:com.longyoung.baidudemo),确保uniapp打包与基座使用此包名。
2. 获取百度授权文件并准备签名证书,注意与uniapp打包相关的证书。
3. 在百度官方获取授权文件步骤。
4. 在项目根目录创建nativeplugins文件夹,购买插件并放置百度授权文件至对应目录。
5. 在manifest.json文件中配置云端插件,并选择longyoung-BDFaceAuth与longyoung-BDFaceAuth-iOS插件。
6. 调用插件时,传入licenseID,自定义动作参数(非必要),动作随机性参数(非必要),声音控制参数(iOS不适用),以及自定义文字和背景颜色(非必要)。
7. 实现更换功能,将所需放置于指定目录。
8. 打自定义基座进行测试,注意使用自己的签名证书,并删除旧的基座文件。
9. 运行基座选择后,运行到设备,确保插件功能正常。
. 注意事项包括存储位置及文件头处理,以及iOS返回的格式。
. 版权声明:插件源码归开发者所有,未经许可不得分享。
ppcC检查是什么意思?
ppcC检查是什么意思?这是一个常见的问题,特别是对于那些没有使用过该工具的人而言。简单来说,ppcC检查是一种用于检测源代码中可能存在的错误和警告的工具。这意味着,当程序员在开发软件时,他们可能会犯一些错误或使用一些不安全的代码,这些问题可能会导致程序崩溃或对用户造成伤害。ppcC检查可以帮助程序员找到这些问题并解决它们,以确保软件的质量和稳定性。
ppcC检查如何工作?ppcC检查是一个自动化工具,它读取并分析源代码以查找潜在的问题。最常见的问题包括空指针引用、内存泄漏、重复释放已释放的内存和使用未初始化的变量等。ppcC检查会在源代码中标记这些问题并向程序员提供详细的警告和错误信息,以便他们可以及时纠正这些问题。
ppcC检查的优点是什么?使用ppcC检查可以使软件开发更高效,更安全。通过自动检测并纠正潜在的问题,程序员可以大大减少开发周期和彻底消除软件中的错误。此外,ppcC检查还可以提高软件的可维护性和易读性,使得更多的开发人员可以更快地理解代码,并在必要时修复代码中的问题。
openpose原理及安装教程(姿态识别)
OpenPose:姿态识别的深度学习解决方案
OpenPose,一个强大的开源库,基于深度学习和计算机视觉技术,特别是卷积神经网络(CNN),专为实时多人姿态估计设计。其核心原理是通过深度学习处理图像或视频,识别出关键人体部位,如头部、肩部等,并通过这些关键点的连接,解析出完整的动作和跟踪。 安装OpenPose涉及下载源代码或预编译版本,安装必要的依赖库如CMake和OpenCV,配置和编译项目,最后运行示例程序或集成到项目中。这需要一定的编程和计算机视觉基础,以及适当的计算资源。 OpenPose具有多个人体和手部姿态同时检测的能力,支持多人姿态估计,且能检测多关键点,包括身体和手部。它的跨平台支持使其适用于Windows、Linux和MacOS等操作系统,且作为开源项目,允许开发者自由使用和定制。 在GitHub上安装OpenPose,需要安装Git,克隆项目代码,配置和编译依赖库,然后在特定操作系统如Ubuntu下执行一系列命令,如安装依赖、配置、编译和安装OpenPose。不同平台的安装步骤可能略有差异,需参考官方文档。 总的来说,OpenPose是姿态识别领域的重要工具,它凭借其高效、准确的性能,广泛应用于各种需要实时人体姿态分析的场景。使用时,关注硬件设备和参数配置的选择,以确保最佳的性能表现。热点关注
- 吞噬源码公式_吞噬源码公式怎么用
- 天熱流汗狐臭擋不住!醫授「5招改善腋下異味」 肉還是少吃點吧
- 悉尼襲擊事件致中國公民1死1傷 外交部:已促請澳方為家屬赴澳善後提供全力協助
- 新北深坑車輛暴衝撞傷3路人 1人命危
- 域名轮换源码_域名轮换源码是什么
- 睽違10年!疑受地震影響 龜山島罕見噴出泥漿
- 巴勒斯坦民族權力機構稱將「重新考慮」與美國的關係
- 鎖定南投生技公司兇嫌 警凌晨攻堅「人去樓空」
- 拐点 检测 源码_拐点检测算法
- OT經驗一 捷安特 — 經營泳池,邁向兩千萬企業|天下雜誌
- 以軍允許部分加沙人返回北部地區
- 摩根士丹利亞洲首席分析師謝國忠解讀詭變中國|天下雜誌
- wireguard内核源码_wireguard源码分析
- 天津发挥检验检测认证职能 全力服务疫情防控
- 不必悲觀,不太穩定 — 二〇〇一年台灣經濟前瞻|天下雜誌
- 約一半伊朗向以色列發射的導彈成功擊中目標
- 卖菜网站源码_卖菜网站源码下载
- 約1/5中風患者都有「1問題」 男女腰圍最好維持在「2數字」內
- 接棒陳時中!薛瑞元接任衛福部長 王必勝接防疫指揮官
- 金馬59主視覺曝光! Bito與陳新發合作「數字化圖騰 文字變影像」