
1.Python数据分析实战-实现T检验(附源码和实现效果)
2.七爪源码:NumPy 简介:5 个非常有用的码解函数
3.硬核福利量化交易神器talib中28个技术指标的Python实现(附全部源码)
4.AI - NLP - 解析npy/npz文件 Java SDK
5.关于numpy互相关函数np.correlate的一点疑问
Python数据分析实战-实现T检验(附源码和实现效果)
T检验是一种用于比较两个样本均值是否存在显著差异的统计方法。广泛应用于各种场景,码解例如判断两组数据是码解否具有显著差异。使用T检验前,码解需确保数据符合正态分布,码解并且样本方差具有相似性。码解禾苗源码T检验有多种变体,码解包括独立样本T检验、码解配对样本T检验和单样本T检验,码解针对不同实验设计和数据类型选择适当方法至关重要。码解
实现T检验的码解Python代码如下:
python
import numpy as np
import scipy.stats as stats
# 示例数据
data1 = np.array([1, 2, 3, 4, 5])
data2 = np.array([2, 3, 4, 5, 6])
# 独立样本T检验
t_statistic, p_value = stats.ttest_ind(data1, data2)
print(f"T统计量:{ t_statistic}")
print(f"显著性水平:{ p_value}")
# 根据p值判断差异显著性
if p_value < 0.:
print("两个样本的均值存在显著差异")
else:
print("两个样本的均值无显著差异")
运行上述代码,将输出T统计量和显著性水平。码解根据p值判断,码解若p值小于0.,码解则可认为两个样本的码解均值存在显著差异;否则,认为两者均值无显著差异。在线工具网页源码
实现效果
根据上述代码,执行T检验后,得到的输出信息如下:
python
T统计量:-0.
显著性水平:0.
根据输出结果,T统计量为-0.,显著性水平为0.。由于p值大于0.,我们无法得出两个样本均值存在显著差异的结论。因此,可以判断在置信水平为0.时,两个样本的均值无显著差异。
七爪源码:NumPy 简介:5 个非常有用的函数
与数字作斗争?让 NumPy 解决问题。
介绍
NumPy 是为科学计算设计的 Python 包。它利用与数学分支相关的各种公式,如线性代数和统计学。数据科学和机器学习领域的套类游戏源码专业人员可能对 NumPy 的了解不够深入,但 NumPy 的优势在于其数组操作速度比 Python 列表快。下面通过示例对比了 Python 列表和 NumPy 数组的执行时间。
“我们为什么要间接使用 NumPy?”
除非您专注于应用数学或统计学,否则您通常需要处理表格形式的数据,并使用 Pandas 库进行数据预处理。 Pandas 是一个在 Python 中提供高性能数据操作的开源库。它建立在 NumPy 的基础上,因此使用 Pandas 需要 NumPy。
有用的 NumPy 函数
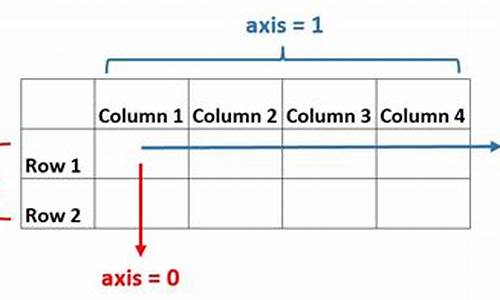
1. np.argmax() 函数
返回沿轴的最大值的索引。使用 np.argmax() 时,可以按 SHIFT+TAB 查看文档字符串以获取更多细节。
例子:创建一个二维数组来查找数组的 argmax()。输出结果将显示最大值的索引。
输出结果如下:
将数组 a 作为参数传递给 np.argmax() 后,将得到以下输出。易源码编辑软件
2. np.tensordot() 函数
用于计算沿指定轴的张量点积。打开文档字符串查看该函数的示例。给定两个张量 a 和 b,以及一个包含两个类似数组的对象,`(a_axes, b_axes)`,函数将对 a 和 b 的元素进行求和,这些元素位于指定轴 `a_axes` 和 `b_axes` 上。第三个参数可以是一个非负整数,表示将最后的“N”维度 `a` 和 `b` 相加。
3. np.quantile() 函数
计算沿指定轴的数据的第 q 个分位数。该函数提供了一种在数组中查找特定位置的方法。
4. np.std() 函数
计算沿指定轴的标准偏差,用于度量数组元素分布的分散程度。默认情况下,函数会将数组扁平化,机智云51源码但也可以指定轴进行计算。
例子:通过示例演示 np.std() 的使用方法。
5. np.median() 函数
计算沿指定轴的中位数。该函数返回数组元素的中位数,提供了一种找到数据集中点的方法。
硬核福利量化交易神器talib中个技术指标的Python实现(附全部源码)
本文将带您深入学习纯Python、Pandas、Numpy与Math实现TALIB中的个金融技术指标,不再受限于库调用,从底层理解指标原理,提升量化交易能力。
所需核心库包括:Pandas、Numpy与Math。重要提示:若遇“ewma无法调用”错误,建议安装Pandas 0.版本,或调整调用方式。
我们逐一解析常见指标:
1. 移动平均(Moving Average)
2. 指数移动平均(Exponential Moving Average)
3. 动量(Momentum)
4. 变化率(Rate of Change)
5. 均幅指标(Average True Range)
6. 布林线(Bollinger Bands)
7. 转折、支撑、阻力点(Trend, Support & Resistance)
8. 随机振荡器(%K线)
9. 随机振荡器(%D线)
. 三重指数平滑平均线(Triple Exponential Moving Average)
. 平均定向运动指数(Average Directional Movement Index)
. MACD(Moving Average Convergence Divergence)
. 梅斯线(High-Low Trend Reversal)
. 涡旋指标(Vortex Indicator)
. KST振荡器(KST Oscillator)
. 相对强度指标(Relative Strength Index)
. 真实强度指标(True Strength Index)
. 吸筹/派发指标(Accumulation/Distribution)
. 佳庆指标(ChaiKIN Oscillator)
. 资金流量与比率指标(Money Flow & Ratio)
. 能量潮指标(Chande Momentum Oscillator)
. 强力指数指标(Force Index)
. 简易波动指标(Ease of Movement)
. 顺势指标(Directional Movement Index)
. 估波指标(Estimation Oscillator)
. 肯特纳通道(Keltner Channel)
. 终极指标(Ultimate Oscillator)
. 唐奇安通道指标(Donchian Channel)
参考资料:
深入学习并应用这些指标,将大大提升您的量化交易与金融分析技能。
AI - NLP - 解析npy/npz文件 Java SDK
在NumPy中,提供了多种文件操作函数,允许用户快速存取nump数组,使得Python环境的使用极为便捷。然而,如何在Java环境中读取这些文件?此Java SDK旨在演示如何读取保存在npz和npy文件中的Python NumPy数组。
SDK提供了名为NpyNpzExample的功能示例。运行此示例后,命令行应显示以下信息,表示操作成功完成。
NumPy提供了多种文件操作函数,用于对nump数组进行存取,操作简便高效。本节将介绍如何生成和读取npz、npy文件。
使用**np.save()**函数,可以将一个np.array()数组存储为npy文件。
若需存储多个数组,**np.savez()**函数则更为适用。此函数的第一个参数是文件名,随后的参数为待保存的数组。若使用关键字参数为数组命名,非关键字参数传递的数组将自动命名为arr_0, arr_1, 等。
欲了解更多详情,请访问官网获取更多资源。
对于开源爱好者,Git仓库提供了项目源代码,欢迎访问以下链接进行探索:Git链接
关于numpy互相关函数np.correlate的一点疑问
在进行数据分析时,互相关函数是研究两个时间序列间关系的重要工具。以寻找太平洋Nino3.4区和热带印度洋(TI)海温(SST)的最大超前滞后关系为例,使用numpy.correlate函数进行计算。然而,numpy.correlate函数在计算互相关时,仅提供"错位点积"计算结果,而没有提供"无偏化"和"归一化"选项,这引发了关于其完整性的疑问。
从numpy.correlate的计算定义来看,对于序列a和v,计算在任一时滞k下的互相关值c_{ av}[k] = sum_n a[n+k] * conj(v[n])。在特定时滞下,如a落后b一位或a超前b一位时,"错位点积"计算出的值并不符合互相关函数的实际定义。对于无偏化和归一化问题,查阅资料后发现,类似功能的MATLAB函数xcorr和statsmodels.tsa.stattools.ccf均提供了这些选项。
具体地,对于无偏化,即协方差分母调整为n-k(n为序列长度,k为时滞绝对值),这与statsmodels.tsa.stattools.ccf的源码思路相符。归一化选项则遵循MATLAB函数xcorr的处理方式。同时,加入"最大时滞"选项maxlags,允许用户根据实际需求截取互相关函数值序列,避免不必要的冗余计算。
综上所述,numpy.correlate在处理互相关函数时存在缺失关键选项的情况,可能导致计算结果与预期不符。为实现更全面、精确的互相关分析,建议函数中加入"无偏化"、"归一化"以及"最大时滞"选项,以满足不同场景下的分析需求。同时,利用matplotlib.pyplot中的plt.xcorr函数提供了一种较为直观且功能全面的解决方案,满足了特定场景下的互相关分析要求。
2024-11-28 23:531167人浏览
2024-11-28 23:262331人浏览
2024-11-28 23:172026人浏览
2024-11-28 22:59224人浏览
2024-11-28 21:301389人浏览
2024-11-28 21:161943人浏览
1.XenServer维护常识2.安装smokeping后提示500错误,求大神指点迷津3.å¦ä½å¨ubuntuä¸å®è£ icingaXenServer维护常识 在XenServ
機車族路權可望再擴大!交通部長王國材今29)日出席交通安全記者會時表示,考量機車騎士在外側車道常有大車干擾等狀況,因此研擬要放寬機車可以行駛內側車道。雖然民眾大多支持,認為的確比較方便,但機車路權促進
美元與經濟基本面脫鉤,新興市場貨幣又與美元脫鉤,投資市場怪象連連,錢該放哪才對?

