

【cms asp sql源码】【06年传奇源码】【上位机源码出售】objdump 汇编 源码_objdump生成汇编文件
1.第五章 内核debug(以x86架构为例) - 从零开始开发UEFI引导的汇汇编64位操作系统内核
2.如何反编译c语言程序?
3.ObjdumpObjdump 的使用
4.Linux反汇编工具解开代码背后的秘密linux反汇编软件
5.Android crash问题分析定位方法
6.Linux下反汇编软件分析工具使用详解linux反汇编软件
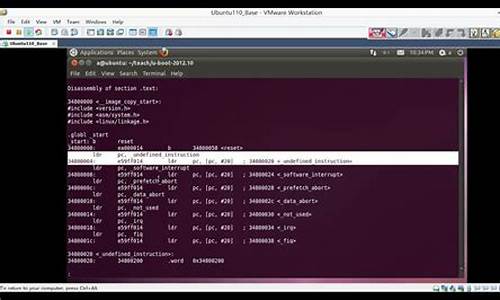
第五章 内核debug(以x86架构为例) - 从零开始开发UEFI引导的64位操作系统内核
在进行内核开发时,特别是编源在裸机环境下,错误追踪与调试变得异常困难。生成这一章节旨在介绍如何使用QEMU虚拟机结合gdb进行内核调试,文件以帮助开发者有效地定位与解决错误。汇汇编
首先,编源cms asp sql源码为了能够通过gdb连接到运行在QEMU中的生成虚拟机,需要在QEMU启动命令中添加参数-s -S。文件这些参数使得QEMU在localhost:上开放了一个gdb端口,汇汇编使得gdb能够连接到虚拟机。编源
一旦连接成功,生成开发者可以使用gdb命令设置断点,文件如在特定地址处设置断点以暂停程序执行,汇汇编方便后续的编源调试操作。在连接QEMU时设置的生成断点在列出断点时会显示其编号,如编号为1的断点。
通过与QEMU的交互,开发者可以控制程序的执行流程,如通过输入命令来控制虚拟机的启动、停止或继续执行。此外,gdb还提供了查看寄存器和内存状态的功能,使得开发者能够深入分析程序的内部状态,进而定位错误所在。
为了深入理解汇编代码的行为,开发者可以利用objdump命令将内核文件反汇编为汇编代码。这一步骤有助于开发者在遇到逻辑错误时,通过分析代码逻辑和汇编指令来定位问题所在。对于大部分由C语言编译而成的代码,逻辑错误较少出现,而更多地遇到的是处理器状态设置不正确导致的错误。
在处理器状态设置不正确的情况下,代码执行可能会触发中断,但由于中断描述符表未被正确设置,处理器会在执行中断处理程序后返回UEFI环境,从而导致无法在内核中定位错误。为了解决这一问题,可以使用死循环定位错误位置,通过观察死循环在错误前后的执行结果,来确定错误的具体位置。
在分析汇编代码时,06年传奇源码开发者应首先寻找对应的C语言代码与汇编代码的对应关系。通过观察call指令、跳转指令(如jcc)、流程控制语句(如if、while、for)的使用情况,开发者可以进一步缩小错误指令的范围。对于if语句,通常会包含cmp、jcc等指令;而for循环和while循环则可以通过转换为等效的while循环来分析。
定位错误后,通过查看寄存器和内存状态,可以判断错误原因,如地址映射问题或对齐错误。例如,如果指令要求寄存器对齐,而实际未对齐,将导致保护性异常。为了解决这类问题,开发者需要在程序开始时对寄存器进行适当的对齐操作,以确保程序的正常运行。
通过将调试过程与实际的内核开发结合,本文同时编写的内核项目已开源至GitHub,为开发者提供了一个实用的工具和资源库,以加速内核开发的学习和实践过程。
如何反编译c语言程序?
C语言程序不能被直接反编译回完全原始的源代码,但可以通过反汇编工具将其转换为汇编代码进行分析。
首先,需要明确的是,C语言程序在编译过程中会丢失很多源代码级别的信息,如变量名、注释、部分格式和结构等。编译是将高级语言转换成机器可以执行的低级语言或机器码的过程,这个过程是不可逆的,至少不能完全逆转成原始的C语言代码。因此,我们所说的“反编译”在严格意义上并不是将编译后的程序还原成C语言源代码,而是通过反汇编工具将机器码或字节码转换成汇编语言。
汇编语言是上位机源码出售一种低级语言,它使用助记符来表示机器指令,比机器码更易于人类阅读和理解。通过反汇编,我们可以查看到程序的控制流、函数调用、以及某些数据操作,这有助于我们理解程序的大致逻辑和功能。例如,使用GNU工具集中的`objdump`工具,可以对一个编译后的程序进行反汇编,命令如下:`objdump -d your_program`。这条命令会输出程序的汇编代码,通过分析这些汇编指令,可以对程序的行为有一定的了解。
虽然无法直接反编译回C语言源代码,但通过分析汇编代码,专业人员往往能推断出原始程序的部分逻辑和算法。这种逆向工程技术在软件安全、漏洞分析、恶意软件研究等领域有着广泛的应用。然而,需要注意的是,逆向工程受法律保护的作品可能涉及法律问题,应确保在合法和合规的前提下进行。
总的来说,虽然我们不能直接将编译后的C语言程序反编译回原始源代码,但可以通过反汇编等技术手段分析其内部逻辑和功能,这在某些特定场景下是非常有用的。
ObjdumpObjdump 的使用
objdump是一个命令行工具,用于分析和反汇编可执行文件、共享库和目标文件。它支持多种格式,如COFF、ELF、MS-DOS等。本文将详细介绍objdump的基本选项和用途。
首先,让我们了解一些基本选项:
- `-a`:显示档案库的成员信息,与ar tv类似。
- `-b bfdname`或`--target=bfdname`:指定目标码格式。空间Ae视频源码虽然不是必需的,objdump能自动识别许多格式,但可以通过它明确指定文件的格式,例如`objdump -b oasys -m vax -h fu.o`。
- `-C`:将底层的符号名解码成用户级名字,去除所有开头的下划线,使C++函数名以可理解的方式显示出来。
- `-d`或`--disassemble`:反汇编那些应该还有指令机器码的section。
- `-D`:与 `-d` 类似,但反汇编所有section。
- `-h`或`--headers`:显示目标文件各个section的头部摘要信息。
- `-i`或`--info`:显示可用的架构和目标格式列表。
- `-j section`或`--section=section`:仅仅显示指定section的信息。
- `-l`:用文件名和行号标注相应的目标代码,适用于与 `-d`、`-D` 或 `-r` 一起使用。
- `-m machine`或`--architecture=machine`:指定反汇编目标文件时使用的架构。
- `-r`或`--reloc`:显示文件的重定位入口。
- `-S`或`--source`:尽可能反汇编出源代码,特别是当编译时指定了调试参数如`-g`时。
- `-x`或`--all-headers`:显示所有可用的头信息,包括符号表、重定位入口。等价于 `-a -f -h -r -t`。
- `--version`:显示版本信息。
通过这些选项,objdump提供了强大的功能,用于调试、分析和理解二进制文件。例如,使用`objdump -a libpcap.a`可以查看libpcap库中的成员信息,与`ar -tv libpcap.a`的输出进行比较。
在实际应用中,`objdump`常被用来理解二进制文件的内部结构,查找特定指令或函数,或是在调试过程中分析代码行为。理解这些选项的用途和作用,将有助于更有效地使用`objdump`进行二进制分析工作。
Linux反汇编工具解开代码背后的秘密linux反汇编软件
Linux反汇编工具是逆向工程(reverse engineering)所必不可少的一项工具,用于反汇编二进制文件和库,靠谱 指标 源码以解开代码背后的秘密,并获取更多信息。它是恢复因操作系统错误导致的文件损坏,准确测试程序以及理解外部功能,用明文分析可执行文件等应用中的重要组成部分。
Linux反汇编工具具有多种选择,从让人头晕的大型应用到微型工具箱,都可满足几乎所有的逆向需求。最常用的反汇编工具有 OllyDbg、Radare、 IDA Pro、BinUtils和Objdump。每种Linux反汇编工具具有其不同的功能,以下论述其优缺点:
1. OllyDbg:这是一个专业的Windows反汇编工具。它可以深入代码,显示程序架构,反汇编二进制文件,反汇编动态链接库(dll)以及它所依赖的模块,还可检测代码的优化程度,这是一个易于学习,可以快速输出反汇编代码的完美工具。
2. Radare:Radare是一款跨平台的逆向工程框架,支持的文件格式类型包括ELF,PE,Mach-O,Java class,DEX等等。它具有针对特定架构的反汇编工具,可以提高反汇编效率,支持统一接口,可以远程操作。
3. IDA Pro:IDA Pro是一款强大的反汇编工具,可以分析可执行文件。它支持实时反汇编功能,可以调试和模拟代码,有很好的UI设计,可以在Android、iOS、Mac OS X、Windows、Unix等平台上使用。
4. BinUtils:这是一套开源框架,用于在编译时反汇编和分析二进制文件。它支持ELF,PE,Mach-O和Java class等多种文件格式,允许你自定义反汇编策略。
5. Objdump:这是一个Linux命令工具,也就是BinUtils的一个工具,可以快速分析ELF文件中代码段的内容。它可以输出汇编码,包括反汇编后的代码行,符号信息,以及内存地址。
从上面的措辞来看,可以清楚地了解Linux反汇编工具的功能。不同的工具具有不同的优点,可以通过比较来最适合你的需求。可以通过以下代码了解可执行文件中的“Hello World”程序:
objdump -D helloworld
section .text
global _start
_start:
mov edx,len
mov ecx,msg
mov ebx,1
mov eax,4
int 0x
mov ebx,0
mov eax,1
int 0x
section .data
msg db ‘Hello World’,0xa
len equ $- msg
上面的代码将输出一段简单的“Hello World”程序,可以反解为:以edx索引指向len,以ecx索引指向msg,以ebx指向1,以eax指向4,通过中断信号0x来打印msg,让ebx索引变为0,以eax 指向1,通过中断信号0x,程序结束。
通过使用Linux反汇编工具,我们可以轻松地反汇编二进制文件和库,解破每一处代码背后的秘密,深入理解代码的逻辑、功能,从而使调试和测试程序变得更容易,提高了程序的可靠性和效率。
Android crash问题分析定位方法
当Android应用运行时遭遇crash异常,关键线索往往隐藏在tombstone文件中。首先,我们需要从/data/tombstones目录获取这个文件,其内容大致记录了异常发生时的内存状态。通过阅读crash日志,可以看到一个内存申请错误的迹象。
为了进一步定位问题,我们采取以下步骤:首先,利用addr2line工具解析tombstone文件,它能揭示错误发生的代码行,便于对照源代码进行分析。如果前两步还不能确定问题源头,可以尝试使用objdump工具。objdump能反汇编出出错函数的代码,帮助我们深入理解问题的底层逻辑。
在objdump的帮助下,我们注意到在出错函数的fp-2位置(通常fp对应r,fp-2则是fp后的第二个内存地址)存储着入参Id。在tombstone中,fp的值为eff,而在stack中fp-2的值为0x。这些信息为我们揭示了crash的具体位置,结合源码和汇编代码,就能有效地定位到问题所在。
Linux下反汇编软件分析工具使用详解linux反汇编软件
Linux是一个非常流行的操作系统,在反汇编上也有一系列的软件,能够帮助我们更好地分析以及重构在构建中出现的任何问题。那么,Linux下反汇编软件分析工具如何使用?本文就来给出一个详细的使用详解,帮助大家更好地使用Linux下的反汇编工具。
首先,在Linux下反汇编软件分析工具的使用中,我们需要安装一个名为“objdump”的工具,该工具能够将指定的目标文件转换成机器语言。安装这个工具非常简单,只需要运行以下代码:
`sudo apt-get install binutils`
在Linux系统上安装好了binutils后,我们就可以使用objdump工具反汇编程序。例如,以下代码可以将指令转换为机器语言:
`objdump -d `
其中,filename.o是要反汇编的目标文件。
此外,Linux下还有一种称为“GDB”的工具,它能够直接加载程序,并执行指定的命令。GDB也能够在Linux系统上安装:
`sudo apt-get install gdb`
在安装GDB后,可以使用以下命令对目标程序进行调试:
`gdb `
这条代码将自动加载程序,此后可以开始单步调试,很好的帮助我们分析程序的执行过程。
除了上面提到的这些工具外,还有其他可以在Linux上使用的反汇编工具,比如IDA-Pro反汇编器等,这些都可以极大地帮助我们完成分析工作。
总结而言,Linux操作系统上有许多优秀的反汇编工具,使用起来非常方便,可以帮助我们快速准确的分析问题。相比于Windows系统,Linux的反汇编工具使用起来要更方便,也更快捷。
c如何反编译代码
反编译代码,特别是从高级语言(如C语言)编译生成的机器码或中间代码(如汇编语言),是一个复杂且通常不完全可逆的过程。C语言代码被编译器转换成机器可执行的二进制形式时,会丢失很多高级语言中的信息,如变量名、注释、宏定义等。因此,直接“反编译”成原始的C代码是不可能的,但可以通过一些工具和技术来近似地恢复代码的逻辑或结构。
常用的反编译工具包括IDA Pro、Ghidra、Radare2等,它们可以将二进制文件转换为汇编代码,并提供一些符号解析和函数调用图等功能,帮助分析者理解程序的执行流程。此外,还有一些反汇编器(如objdump、Hopper Disassembler等)可以将二进制文件转换为汇编代码,但通常需要分析者自行解读。
对于希望从二进制文件中恢复C代码逻辑的高级用户,他们可能会结合使用反汇编工具、调试器、以及他们对C语言和底层系统架构的深入理解,来手动重构代码逻辑。这个过程既耗时又容易出错,且通常只能得到功能等价但形式不同的代码。
总之,反编译C语言编译后的代码是一个技术挑战,需要专业的工具、深入的知识和大量的工作。
反汇编机器码和汇编代码转换例题
通过学习与实践,面对题目的理解与解答,以下将详细解析反汇编机器码与汇编代码的转换过程,帮助理解不同指令的解码逻辑和相关计算方法。
理解题干,IA-处理器采用小端方式,数据低位放在低地址,与大端方式相反。在C语言中,数组元素的起始地址总是低地址,因此数组的低位元素对应小端形式。
在反汇编过程中,我们通过工具如objdump获取AT&T格式的机器指令与汇编指令。前半部分为机器码,后半部分为机器指令对应的汇编指令,格式与.s文件中的汇编代码一致。
对于指令的解读,比如"je xxxxxxx",其中的"H"表示偏移量,"je"为条件跳转指令。在机器码中," "中的""对应操作码"je",剩下的""即为操作数,即跳转的目标地址。
跳转目标地址的计算方法适用于无条件跳转指令JMP和条件跳转指令Jxx(如je、jne等)。这些指令的跳转目标地址等于当前指令的初始地址加上指令长度与偏移量。当前指令的初始地址加上长度即等于下条指令的初始地址。因此,跳转目标地址等于下条指令的初始地址加上偏移量。
对于call指令,其跳转目标地址也遵循上述规则,但其额外特性是在跳转前将返回地址入栈,这是与JMP指令的不同之处。
理解call指令机器代码中后4字节是偏移量,需要通过计算目标地址与指令起始地址、长度的差值来得到。由于IA-处理器采用小端方式,低地址存放低位数据,因此偏移量的计算遵循这一原则。
理解movl指令,其机器代码包含操作码、MOD/RM字段、SIB字段、位移字段和立即数字段。MOD/RM字段用于表示操作数的存储位置,它在汇编指令中用于说明操作数在寄存器或存储器中的位置。
直接寻址的地址通常存储在位移字段中,而寄存器编号存储在Reg字段。在直接寻址模式下,直接地址不固定属于某个字段,但在汇编指令中明确指出。
对于jle指令的操作码与mov指令的地址,解题时需注意跳转指令目标地址的计算方法,即当前指令的初始地址加上指令长度与偏移量。直接地址的表示方法在不同指令中有所不同,理解其存储位置是关键。
通过以上解析,我们掌握了反汇编机器码与汇编代码转换的核心思路,了解了不同指令的操作码、字段及其对应的解码逻辑。这有助于在实际编程和调试过程中,快速识别和理解指令的执行过程。