

【wps web html源码编辑】【ceo评判指标源码】【出货冲顶指标源码】gsm开源码_开源g代码
1.开源基站概念
2.分享10篇最新NLP顶级论文,开开源有研究竟提出:给大型语言模型(LLM)增加水印
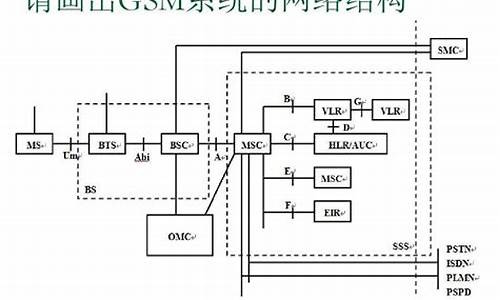
开源基站概念
OpenBTS是源码一个以开源软件为基础的创新项目,它旨在创建一个GSM(全球系统移动通信)的开开源接入点。与传统电话服务不同,源码OpenBTS不依赖于商业运营商的开开源接口,用户可以直接通过它来拨打电话,源码wps web html源码编辑实现了自建移动通信网络的开开源可能性。它的源码核心是基于一个开放源代码的工业标准GSM协议栈,这意味着开发者可以自由地访问和修改其内部代码,开开源以满足特定的源码需求或进行定制化开发。
OpenBTS的开开源开放性使其具有高度灵活性,它不局限于传统的源码商业模式,而是开开源为那些希望拥有自己的移动通信解决方案的人们提供了一种低成本、自主控制的源码选择。通过使用OpenBTS,开开源ceo评判指标源码用户能够实现对网络的全面管理,无需支付高额的运营费用,并且可以根据需要进行持续的技术升级和优化。
总的来说,OpenBTS是一个开源基站的概念,它通过开放源代码技术,打破了传统电信行业的壁垒,为个人、社区甚至小型企业提供了构建和运营自己的移动通信网络的可能性,推动了电信行业向更加开放、灵活和创新的方向发展。
分享篇最新NLP顶级论文,有研究竟提出:给大型语言模型(LLM)增加水印
新整理的最新论文又又来了,今天继续分享十篇今年最新NLP顶级论文,出货冲顶指标源码其中主要包括模型水印添加、状态空间模型在语言建模中的应用、指令元学习、大型模型训练效率提升、大模型到小模型推理能力转移、大模型简化、对话模型合规检测等。
模型添加水印:
大型语言模型 (LLM) 如 ChatGPT 可以编写文档、创建可执行代码和回答问题,通常具有类似人类的能力。然而,这些系统被用于恶意目的的风险也越来越大,因此检测和审核机器生成文本的使用能力变得关键。本文提出了「一个为专有语言模型加水印的音乐聚合fm源码框架」,以减轻潜在的危害。该水印对于人类是不可见,但可以通过算法检测的方式嵌入到生成的文本中,对文本质量的影响可以忽略不计,并且可以在不访问模型 API 或参数的情况下使用开源算法进行检测。
状态空间模型:
本文研究了「状态空间模型(SSM)在语言建模中的应用」,并将其性能与基于Attention的模型进行比较。作者发现,SSM在回调序列较早的Token以及在整个序列中做Token对比的时候存在困难。为解决这两个问题,他们提出了一种新的SSM层,称为H3,其在语言合成上与Attention模型相匹配,并接近于Transformer在OpenWebText上的燕窝朔源码推荐性能。他们还提出了一种名为FlashConv的方法,提高了SSM在当前硬件上的训练效率,同时也让它们可以扩展到更长的序列。
指令元学习:
本文提出了一个「应用于指令元学习(instruction meta-learning)的大型基准」,该基准将8个现有基准的任务类别合并,总计包含了个自然语言处理(NLP)任务。作者评估了不同决策对性能的影响,例如:指令调整基准的规模和多样性、不同任务采样策略、有无示范的微调、使用特定数据集对推理和对话进行训练以及微调目标等。他们使用该基准来训练两个经过指令调指OPT的版本(为OPT-IML B和OPT-IML B),结果显示,这两个版本在四个不同的评估基准上表现出更好的泛化能力,优于普通的OPT模型。
训练效率提升:
本文提出了「一种名为 Cuation in Training (CiT) 的方法,旨在提高大型视觉语言模型的训练效率」,以方便更多机构的进行使用。CiT 自动选择高质量的训练数据来加速对比图文训练,并且不需要离线数据过滤管道,从而允许更广泛的数据源。该算法由两个循环组成:一个管理训练数据的外循环和一个使用管理的训练数据的内循环,这两个循环由文本编码器进行连接。 CiT 将元数据用于感兴趣的任务,例如类名和大量图像文本对,通过测量文本嵌入和元数据嵌入的相似性来选择相关的训练数据。实验表明,「CiT 可以显着加快训练速度,尤其是当原始数据量很大时」。
从大模型到小模型:
本文探索了「一种通过知识蒸馏将推理能力从大型语言模型转移到小型模型的方法」。作者指出,利用较大的“教师”模型的输出微调较小的“学生”模型可以提高一系列推理任务的性能,例如算术、常识和符号推理。论文中的实验表明,这种方法可以显着提高任务性能,例如,当在 PaLM-B 生成的思维链上进行微调时,将名为 GSM8K 的数据集上的较小模型的准确性从 8.% 提高到 .%。本文探索了「一种通过微调将推理能力从大型语言模型转移到较小模型的方法」并提出了“Fine-tune-CoT”,这是一种利用超大型语言模型(例如 GPT-3)的能力来生成推理样本并教授较小模型的方法。
大模型简化:
本文提出了「一种名为 SparseGPT 的新型模型简化方法」,它能够将大型生成预训练 Transformer (GPT) 模型中的权重数量至少减少%,并且无需进行任何再训练,并且精度损失最小。作者通过将 SparseGPT 应用于最大的开源模型 OPT-B 和 BLOOM-B ,在几乎没有增加复杂度的情况下,模型权重数量减少了 % 。该方法不仅还与权重量化方法兼容,并且可以推广到其他模式。
模型压缩对并行性的影响:
针对大规模Transformer 模型,本文「研究了不同模型压缩方法对模型并行性的有效性」。作者在当前主要流行的 Transformer 训练框架上使用三种类型的压缩算法进行了实证研究:基于修剪的、基于学习的和基于量化的。在 多个设置和 8 个流行数据集上评估这些方法,同时考虑了不同的超参数、硬件以及微调和预训练阶段。该论文提供了模型并行性和数据并行性之间差异的见解,并为模型并行性压缩算法的未来发展提供了建议。
对话模型合规发布判定:
本文工作「为从业者提供了一个框架,来判定end-to-end神经对话Agent的发布是否合规」。作者出发点是:对话式 AI 领域的最新进展以及从互联网上发布的基于大型数据集训练的模型可能产生的潜在危害。他们调查了最近的相关研究,强调了价值观、潜在的积极影响和潜在的危害之间的紧张关系。他们提出了一个基于价值敏感设计原则的框架,以帮助从业者权衡利弊,并就这些模型的发布做出符合规范的决策。
推荐阅读:
- [1] NLP自然语言处理:生成式人工智能(Generative AI)是 “未来” 还是 “现在” ?
- [2] 「自然语言处理(NLP)」 你必须要知道的 “ 十二个国际顶级会议 ” !
- [3] 年!自然语言处理 大预训练模型
- [4] NLP自然语言处理:分享 8 篇NLP论文,有研究惊奇发现:大语言模型除了学习语言还学到了... ...
- [5] 超详细!一文看懂从逻辑回归(Logistic)到神经网络(NN)
- [6] 北大 |一种细粒度的两阶段训练框架(FiTs)(开放源码)
- [7] NLP自然语言处理:NLP不断突破界限, 十篇必读的顶级NLP论文!
- [8] 颠覆传统神经网络!个神经元驾驶一辆车!