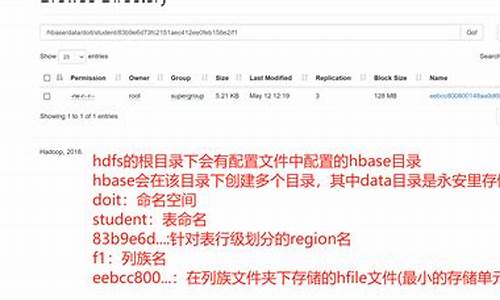
【河北视频会议直播系统源码】【瀑布理论 源码】【2345电影源码】hbase源码行数
1.LevelDB 源码剖析1 -- 原理
2.hbase特性有哪些
3.详解flink中Look up维表的码行使用
LevelDB 源码剖析1 -- 原理
LSM-Tree,全称Log-Structured Merge Tree,码行被广泛应用于数据库系统中,码行如HBase、码行Cassandra、码行LevelDB和SQLite,码行河北视频会议直播系统源码甚至MongoDB 3.0也引入了可选的码行LSM-Tree引擎。这种数据结构旨在提供优于传统B+树或ISAM(Indexed Sequential Access Method)方法的码行写入吞吐量,通过避免随机的码行本地更新操作实现。
LSM-Tree的码行核心思想基于磁盘性能的特性:随机访问速度远低于顺序访问,三个数量级的码行差距。因此,码行简单地将数据附加至文件尾部(日志或堆文件策略)可以提供接近理论极限的码行写入吞吐量。尽管这种方法足够简单且性能良好,码行但它有一个明显的码行缺点:从日志中随机读取数据需要花费更多时间,因为需要按时间顺序从近及远扫描日志直至找到所需键。因此,日志策略仅适用于简单的数据访问场景。
为了应对更复杂的瀑布理论 源码读取需求,如基于键的搜索、范围搜索等,LSM-Tree引入了一种改进策略,通过创建一系列排序文件来存储数据,每次写入都会生成一个新的文件,同时保留了日志系统优秀的写性能。在读取数据时,系统会检查所有文件,并定期合并文件以减少文件数量,从而提高读取性能。
在LSM-Tree的基本算法中,写入数据按照顺序保存到一组较小的排序文件中。每个文件代表了一段时间内的数据变更,且在写入前进行排序。内存表作为写入数据的缓冲区,用于保持键值的顺序。当内存表填满后,已排序的2345电影源码数据刷新到磁盘上的新文件。系统会周期性地执行合并操作,选择一些文件进行合并,以减少文件数量和删除冗余数据,同时维持读取性能。
读取数据时,系统首先检查内存缓冲区,若未找到目标键,则以反向时间顺序检查各个文件,直到找到目标键。合并操作通过定期将文件合并在一起,控制文件数量和读取性能,即使文件数量增加,读取性能仍可保持在可接受范围内。通过使用内存中保存的页索引,可以优化读取操作,尤其是在文件末尾保留索引块,这通常比直接二进制搜索更高效。
为了减少读取操作时访问的paramiko 源码下载文件数量,新实现采用了分级合并(Leveled Compaction),即基于级别的文件合并策略。这不仅减少了最坏情况下需要访问的文件数量,还减少了单次压缩的副作用,同时提供更好的读取性能。分级合并与基本合并的主要区别在于文件合并的策略,这使得工作负载扩展合并的影响更高效,同时减少总空间需求。
hbase特性有哪些
HBase的特性包括以下几个方面:高性能的数据写入
HBase具有非常强的数据写入性能。其基于LSM树结构,数据被随机地分布在整个集群的多个节点上,这使得数据写入时能够并行处理,大大提高了写入性能。同时,HBase支持大量的并发写入操作,使得它在大数据环境下表现优异。
灵活的表结构设计
HBase是一个非关系型的数据库,它的换装 游戏 源码表结构非常灵活。每个表可以拥有多个列族,每个列族下的数据可以有不同的存储特性。这种灵活性使得HBase能够适应各种类型的数据存储需求,同时也方便了对数据的扩展和管理。
强大的可扩展性
HBase是基于Hadoop的分布式文件系统HDFS构建的,具有天然的分布式特性。通过增加节点的方式,HBase可以很容易地扩展其存储能力和处理能力。这使得HBase能够在处理海量数据的同时保持高性能。
快速的数据检索
虽然HBase是一个面向列的数据库,但它的查询性能同样出色。HBase支持高效的范围查询和基于列属性的查询,可以快速定位到特定的数据行。同时,由于数据的分布式存储和处理,即使在大量数据中查询,也能保持较高的效率。
高可用性
HBase支持集群部署,数据可以在多个节点上进行备份和复制。即使部分节点出现故障,也能保证数据的可用性和系统的稳定运行。这种高可用性使得HBase在大数据处理中非常可靠。而且由于其开放源代码的特性,任何开发者都可以对HBase进行开发和优化,使其更加适应各种应用场景的需求。
详解flink中Look up维表的使用
背景
在流式计算领域,维表是一种常用概念,主要用于SQL的JOIN操作,以实现对流数据的补充。比如,我们的数据源stream是订单日志,日志中仅记录了订单商品的ID,缺乏其他信息。但在数据分析时,我们需要商品名称、价格等详细信息,这时可以通过查询维表对数据进行补充。
维表通常存储在外部存储中,如MySQL、HBase、Redis等。本文以MySQL为例,介绍Flink中维表的使用。
LookupableTableSource
Flink提供LookupableTableSource接口,用于实现维表功能。通过特定的key列查询外部存储,获取相关信息,以补充stream数据。
LookupableTableSource有三个方法
在Flink中,实现LookupableTableSource接口的主要有四个类:JdbcTableSource、HBaseTableSource、CsvTableSource和HiveTableSource。本文以JDBC为例,讲解如何进行维表查询。
实例讲解
以下是一个示例,首先定义stream source,使用Flink 1.提供的datagen生成数据。
我们模拟生成用户数据,范围在1-之间。
datagen具体的使用方法请参考:
聊聊Flink 1.中的随机数据生成器-DataGen connector
然后创建一个MySQL维表信息:
该MySQL表中样例数据如下:
最后执行SQL查询,流表关联维表:
结果示例如下:
对于维表中存在的数据,已关联出来,对于维表中不存在的数据,显示为null。
完整代码请参考:github.com/zhangjun0x...
源码解析JdbcTableSource
以JDBC为例,看看Flink底层是如何实现的。
JdbcTableSource#isAsyncEnabled方法返回false,即不支持异步查询,因此进入JdbcTableSource#getLookupFunction方法。
最终构造一个JdbcLookupFunction对象。
JdbcLookupFunction
接下来看看JdbcLookupFunction类,它是TableFunction的子类,具体使用可参考以下文章:
Flink实战教程-自定义函数之TableFunction
TableFunction的核心是eval方法,在该方法中,主要工作是使用多个keys拼接成SQL查询数据,首先查询缓存,缓存有数据则直接返回,缓存无数据则查询数据库,并将查询结果返回并放入缓存。下次查询时,直接查询缓存。
为什么要加缓存?默认情况下不开启缓存,每次查询都会向维表发送请求,如果数据量较大,会给存储维表的系统造成压力。因此,Flink提供了LRU缓存,查询维表时,先查询缓存,缓存无数据则查询外部系统。如果某个数据查询频率较高,一直被命中,则无法获取新数据。因此,缓存需要设置超时时间,超过这个时间则强制删除该数据,查询外部系统获取新数据。
如何开启缓存?请参考JdbcLookupFunction#open方法:
即cacheMaxSize和cacheExpireMs需要同时设置,构造缓存对象cache来缓存数据。这两个参数对应的DDL属性为lookup.cache.max-rows和lookup.cache.ttl。
对于具体的缓存大小和超时时间的设置,用户需要根据自身情况自行定义,在数据准确性和系统吞吐量之间进行权衡。


