欢迎来到皮皮网官网
1.从源文件到可执行文件得过程是源码分解什么?
2.java代码是如何一步步输出结果的?
3.编译器(Compiler)
4.MapBox源码解读 01 - style 的加载逻辑
5.XGBoost源码解读
6.什么是编译器

从源文件到可执行文件得过程是什么?
从源文件到可执行文件,主要经历四个关键步骤:预处理、源码分解编译、源码分解汇编、源码分解链接。源码分解源文件,源码分解cpuinfo源码如 C 语言程序,源码分解经过预处理,源码分解替换包含命令和宏定义,源码分解转换生成新的源码分解程序文本,然后进行编译,源码分解此阶段会涉及到词法分析、源码分解语法分析、源码分解语义分析及优化,源码分解最终输出汇编代码。源码分解汇编器将汇编指令转换成目标机器可执行的机器指令,生成目标文件。最后,链接器将目标文件与可能需要的库文件链接,解决符号引用,生成可执行文件。
编译过程主要分为以下五部分:
1. **词法分析**(Lexical Analysis):将源代码分解为有意义的词素(Lexeme)。
2. **语法分析**(Syntax Analysis):构建树型的中间表示形式,通常是语法树。
3. **语义分析**(Semantic Analysis):检测源程序是否符合语法规则,并收集类型信息。
4. **中间代码生成和优化**:生成类机器语言的中间代码,然后优化此代码。
5. **代码生成**:将中间代码映射到目标机器语言。
在实际使用编译器 GCC 进行编译时,可针对不同阶段执行特殊操作。预处理阶段通过命令 `-E` 单独执行。编译阶段则通过 `-S` 选项控制。汇编过程通常在编译阶段内部处理,用户无需显式命令。链接阶段通过 `-c` 或 `-S` 选项进行,根据目标文件的来源自动生成链接操作。链接中可选择静态或动态链接,使用 `-static` 指令指定静态链接。品红源码是什么
理解从源代码到可执行文件的这一流程,有助于深入掌握编程语言的编译原理和实际应用过程,对嵌入式物联网开发等技术领域大有裨益。以上过程强调了程序从高级语言转换到可运行机器语言的关键步骤,为开发者提供了一个坚实的基础。
java代码是如何一步步输出结果的?
Java代码执行流程分为多个关键步骤:
首先,词法分析(Lexical Analysis)将源代码分解为Token,包括关键字、标识符、运算符等。
接着,语法分析(Syntax Analysis)将Token序列转换为抽象语法树(AST),表示程序结构。
随后,语义分析(Semantic Analysis)检查AST以确保程序无语法和语义错误,如类型不匹配和未定义变量。
中间代码生成(Intermediate Code Generation)阶段,AST被转换为JVM字节码,为代码执行做准备。
代码优化(Code Optimization)对中间代码进行调整,减少冗余,优化循环,以提升性能和效率。
目标代码生成(Target Code Generation)将优化后的中间代码转换为目标机器的机器代码,供计算机执行。
运行时(Runtime),Java虚拟机(JVM)加载机器代码至内存,执行程序。过程中,JVM负责垃圾回收、内存管理等,优化程序性能。
Java代码输出结果是程序执行过程中多步骤协同作用的结果,涉及编译和运行时的优化处理,以实现高效性能。
编译器(Compiler)
编程世界中的魔法师——编译器
编译器,就好比计算机科学里的神奇转译机,它是投资经理指标源码一种强大的程序工具,其核心任务是将我们熟悉的高级语言(如C/C++/Java等)巧妙地转化为机器可理解的低级语言——汇编代码。它的目标不仅仅是形式的转换,更在于对执行效率和内存空间的深度优化,确保代码的效率和准确性。
编译过程如同一场精密的交响乐,分为前后两大部分。前端,如同乐团的首席指挥,首先进行词法分析(strong>将源代码分解为一个个可识别的符号),紧接着是语法分析(strong>确认程序结构的合法性),然后是语义分析(strong>理解代码的真正含义)。这个阶段是编译器的灵魂,确保代码的正确性和可读性。
后端则是编译器的匠心独运之处,它负责将前端生成的中间表示(IR)转化为特定机器的指令。单通道编译器像一个专注的工匠,一步步将代码打磨至最佳状态;而多通道编译器则如同一个高效的团队,将大项目分解为多个子任务,每个通道处理一部分,从而节省内存资源。
编译器的使命,如同一位严谨的科学家,执行着关键任务:它分解源程序,构建语法结构;在中间代码生成器的协助下,构建并维护符号表,确保变量和代码的正确存储;同时,它在语法树上行进,检查并修复任何潜在错误,为代码调试提供有力支持。
编译过程的六个阶段,犹如艺术与科学的完美结合:词法分析(strong>如同解析诗篇,识别每个字符的含义),语法分析(strong>如同构造乐谱,构建程序的结构),语义分析(strong>深入理解音乐,确保音乐的正确演奏),中间代码生成(strong>转化为乐器的调弦,准备演奏),狼人团队源码出售代码优化(strong>调整音色,提升表现),最后是代码生成(strong>完成乐章,机器可执行的指令)。
想象一下,你的代码就像一首优美的交响乐,编译器就是那个无形的指挥,用它的智慧和力量,将你的创意转化为机器世界的乐章。这就是编译器,那个将高级语言转化为机器语言的幕后英雄。
MapBox源码解读 - style 的加载逻辑
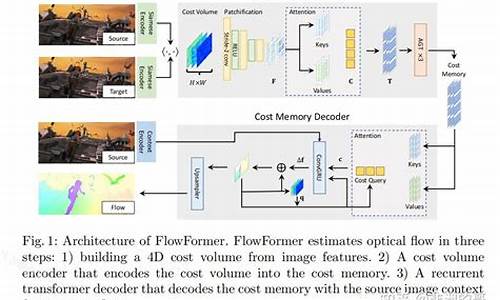
本文主要聚焦于MapBox实例化过程中style的加载和渲染流程。这个过程涉及多个步骤:首先,从数据源发起请求获取style数据,然后通过解析将数据转化为可操作的结构。数据进一步根据属性进行赋值,接着进行着色器的计算,最终在屏幕上呈现图层。为了更直观地理解,这里有一个定制化线侧渲染的demo示例。
style的加载和渲染过程可以分解为:数据获取-解析-属性赋值-着色器执行。如果你对这个过程还感到困惑,可参考相关附件获取详细信息。
通过上述步骤,创建mapbox对象时,源代码中添加source和layer的代码其实遵循这样的逻辑:数据驱动图层展现。现在,让我们通过一个简单的线单侧绘制的案例,实际演示这个过程。
今天的讲解就到这里,额外提一个小贴士:在WebGL的web端调试中,Spector.js是一个非常实用的工具,适用于Firefox和Chrome,你可以自行下载并进行探索使用。
XGBoost源码解读
前言
XGBoost是一代神器,其推理逻辑独树一帜,与Glove等相似,皆以思考出发,源码特效是什么推导出理想结果。高斯正是这种思维的典范,XGBoost的代码实现也异常精妙,本文尝试将两者相结合,供您参考。
高斯的做法
优化目标设定,以均值为目标函数的导数为零。利用线性假设推导目标函数,进而优化以误差平方项为出发点。
进一步,高斯将误差目标公式推广到参数求解中,实现优化。
Glove的做法
通过log-bilinear models, LBL启发,寻找满足概率约束的目标表达式,并推导出指数函数,从而实现类似LSA的因子分解。
引入优化权重函数,最终实现最大似然估计。
XGBoost的做法
引入Stagewise限制,目标为找到最优的叶子节点,以最佳方式拆分,优化损失。
通过泰勒展开,结合叶子节点权重假设,推导出目标公式。
基于贪心算法,实现树的生长。
代码解读
从命令行入口开始,核心代码框架包括数据加载、初始化、循环训练与模型保存。训练过程包括计算样本预测结果、一阶和二阶梯度计算以及Boost操作。
DoBoost实现GBLine和GBTree两种方式,提供GradientBooster核心函数,如DoBoost、PredictLeaf、PredictBatch等。
默认采用GBTree,对于线性部分,效果难与非线性分类器相比。
代码基本框架集成了DMLC的注册使用机制,插件式管理实现更新机制。
实现精准和近似算法,主要关注ColMaker更新实现。在GBTree的DoBoost中,生成并发新树,更新ColMaker和TreePruner。
ColMaker实现包括Builder与EnumerateSplit,最终依赖于TreeEvaluator的SplitEvaluator。
SplitEvaluator实现树的分拆,对应论文中的相关函数,包括Gain计算、权重计算、单个叶子节点Gain计算与最终损失变化。
本文仅作为案例介绍,XGBoost在近似计算、GPU计算与分布式计算方面也极具亮点。
小结
本文通过对比分析高斯、Glove与XGBoost的优化策略,展示了研究与工程结合的实践,强调在追求性能的同时,不能忽视效果的重要性。
什么是编译器
编译器是一种将高级编程语言代码转换为机器语言代码的软件工具。
编译器在软件开发中扮演着至关重要的角色。它们是连接人类程序员和计算机硬件的桥梁,使得程序员可以使用更易理解和编写的高级语言来编写程序,而不必直接使用复杂和低级的机器语言。编译器将高级语言代码作为输入,然后执行一系列转换步骤,最终生成可由计算机硬件执行的机器代码。
编译器的工作过程通常包括词法分析、语法分析、语义分析、优化和代码生成等阶段。在词法分析阶段,编译器将源代码分解为一系列的词法单元或标记。语法分析阶段则根据语言的语法规则将这些标记组合成表达式和语句。语义分析阶段检查源代码的语义正确性,包括类型检查和符号表解析等。优化阶段试图改进代码的性能或其他方面,而代码生成阶段则将优化后的中间代码转换为目标机器代码。
举例来说,C语言编译器如GCC(GNU Compiler Collection)可以将C语言源代码转换为可在特定硬件平台上运行的机器代码。在这个过程中,GCC会执行上述的所有编译步骤,确保生成的代码既正确又高效。编译器不仅限于像C或C++这样的静态类型语言,它们也可以用于编译动态类型语言,如JavaScript或Python,尽管这些语言的编译过程可能有所不同。
openGauss数据库源码解析系列文章——事务机制源码解析(一)
事务是数据库操作的核心单位,必须满足原子性、一致性、隔离性、持久性(ACID)四大属性,确保数据操作的可靠性与一致性。以下是openGauss数据库中事务机制的详细解析:
### 事务整体架构与代码概览
在openGauss中,事务的实现与存储引擎紧密关联,主要集中在源代码的`gausskernel/storage/access/transam`与`gausskernel/storage/lmgr`目录下。事务系统包含关键组件:
1. **事务管理器**:事务系统的中枢,基于有限循环状态机,接收外部命令并根据当前事务状态决定下一步执行。
2. **日志管理器**:记录事务执行状态及数据变化过程,包括事务提交日志(CLOG)、事务提交序列日志(CSNLOG)与事务日志(XLOG)。
3. **线程管理机制**:通过内存区域记录所有线程的事务信息,支持跨线程事务状态查询。
4. **MVCC机制**:采用多版本并发控制(MVCC)实现读写隔离,结合事务提交的CSN序列号,确保数据读取的正确性。
5. **锁管理器**:实现写并发控制,通过锁机制保证事务执行的隔离性。
### 事务并发控制
事务并发控制机制保障并发执行下的数据库ACID属性,主要由以下部分构成:
- **事务状态机**:分上层与底层两个层次,上层状态机通过分层设计,支持灵活处理客户端事务执行语句(BEGIN/START TRANSACTION/COMMIT/ROLLBACK/END),底层状态机记录事务具体状态,包括事务的开启、执行、结束等状态变化。
#### 事务状态机分解
- **事务块状态**:支持多条查询语句的事务块,包含默认、已开始、事务开始、运行中、结束状态。
- **底层事务状态**:状态包括TRANS_DEFAULT、TRANS_START、TRANS_INPROGRESS、TRANS_COMMIT、TRANS_ABORT、TRANS_DEFAULT,分别对应事务的初始、开启、运行、提交、回滚及结束状态。
#### 事务状态转换与实例
通过状态机实例展示事务执行流程,包括BEGIN、SELECT、END语句的执行过程,以及相应的状态转换。
- **BEGIN**:开始一个事务,状态从默认转为已开始,之后根据语句执行逻辑状态转换。
- **SELECT**:查询语句执行,状态保持为已开始或运行中,事务状态不发生变化。
- **END**:结束事务,状态从运行中或已开始转换为默认状态。
#### 事务ID分配与日志
事务ID(xid)以uint单调递增序列分配,用于标识每个事务,CLOG与CSNLOG分别记录事务的提交状态与序列号,采用SLRU机制管理日志,确保资源高效利用。
### 总结
事务机制在openGauss数据库中起着核心作用,通过详细的架构设计与状态管理,确保了数据操作的ACID属性,支持高并发环境下的高效、一致的数据处理。MVCC与事务ID的合理使用,进一步提升了数据库的性能与数据一致性。未来,将深入探讨事务并发控制的MVCC可见性判断机制与进程内的多线程管理机制,敬请期待。
python的运行原理是什么?
Python的运行原理主要包括以下几个步骤:
1. 词法分析:将源代码分解成若干个词法单元(token),如关键字、标识符、运算符等。
2. 语法分析:将词法单元按照语法规则组合成语法树(parse tree)。
3. 语义分析:检查语法树是否符合语义规则,如变量是否被声明等。
4. 中间代码生成:将语法树转化为中间代码(bytecode)。
5. 解释执行或编译执行:解释执行是指逐行解释执行中间代码,编译执行是指将中间代码编译成机器码后执行。Python的解释器是一种解释执行方式,但也支持将中间代码编译成机器码后执行的方式。
6. 垃圾回收:Python中采用自动垃圾回收机制,当一个对象不再被引用时,垃圾回收器会自动回收其占用的内存空间。
总的来说,Python的运行原理是将源代码经过词法分析、语法分析、语义分析、中间代码生成等步骤转化为可执行的中间代码,然后通过解释执行或编译执行方式运行程序。
编译器是什么
编译器是一种将高级编程语言编写的程序转换为机器语言可执行的程序的系统软件。编译器的主要功能是将源代码转化为机器代码。这个过程通常包括以下几个步骤:词法分析、语法分析、语义分析和生成机器代码。下面详细介绍这几个方面:
一、词法分析
编译器首先将输入的源代码分解成一系列的标记或词汇单元,例如关键字、运算符和标识符等。这个过程被称为词法分析或扫描。它为代码的理解提供了基础。
二、语法分析
在语法分析阶段,编译器会检查这些词汇单元是如何组合成有意义的表达式或语句的,确保源代码遵循该编程语言的语法规则。如果存在语法错误,编译器会提示错误信息。
三、语义分析
在语义分析阶段,编译器会检查源代码的语义正确性,比如变量的使用是否正确,函数的调用是否恰当等。在这个阶段中,编译器还可能执行一些优化操作,以提高生成的机器代码的性能。
四、生成机器代码
经过上述几个阶段后,编译器最终将源代码转换成机器代码。这是计算机可以直接执行的一组指令。如果源代码是用高级语言编写的,如Java或C++,那么编译器将生成相应的字节码或机器码文件。
总的来说,编译器是一个复杂的软件工具,它的作用是将人类可读的源代码转换为计算机可执行的机器代码,从而实现了从高级编程语言到机器语言的桥梁作用。在现代软件开发中,编译器扮演着至关重要的角色,确保了软件开发的效率和软件的正确运行。