
1.探索系列 百度情感预训练模型SKEP
2.Python主要内容学的飞桨是什么?
3.paddlehub介绍
4.好玩的开源项目推荐
5.如何评价百度飞桨发布的paddlelite框架?
6.PP-ShiTu 库管理工具使用教程
探索系列 百度情感预训练模型SKEP
探索面向中英文场景的文本分类训练及推理工作,以百度的源到手情感预训练模型SKEP为核心。SKEP在项典型任务上全面超越当前最先进的码下模型,已被ACL 收录。载飞
为执行此任务,桨的机上需在MAC系统环境下操作。源码jdk源码分析首先安装飞桨2版本,下载其次安装senta。飞桨推荐使用pip安装,源到手或根据源码进行安装。码下注意,载飞本机为Windows环境,桨的机上因此某些sh指令需调整执行方式。源码
任务涉及的下载数据下载需通过浏览器的地址栏完成,为中文任务准备的飞桨文本分类数据和英文数据分别下载后存入data目录中。接下来,执行官方demo服务的数据集处理步骤,这是一项典型的NLP基础任务。
为了完成任务,需下载预训练语言模型。在senta中,获取中文预训练语言模型的下载链接,英文预训练模型的下载链接同样存在。这些链接由百度云提供的文件存储服务BOS支持,下载速度较快。
Python主要内容学的是什么?
第一步:Python开发基础Python全栈开发与人工智能之Python开发基础知识学习内容包括:Python基础语法、数据类型、字符编码、文件操作、函数、装饰器、迭代器、内置方法、常用模块等。
第二步:Python高级编程和数据库开发
Python全栈开发与人工智能之Python高级编程和数据库开发知识学习内容包括:面向对象开发、Socket网络编程、线程、进程、队列、IO多路模型、Mysql数据库开发等。51单片机 源码
第三步:前端开发
Python全栈开发与人工智能之前端开发知识学习内容包括:Html、CSS、JavaScript开发、Jquery&bootstrap开发、前端框架VUE开发等。
第四步:WEB框架开发
Python全栈开发与人工智能之WEB框架开发学习内容包括:Django框架基础、Django框架进阶、BBS+Blog实战项目开发、缓存和队列中间件、Flask框架学习、Tornado框架学习、Restful API等。
第五步:爬虫开发
Python全栈开发与人工智能之爬虫开发学习内容包括:爬虫开发实战。
第六步:全栈项目实战
Python全栈开发与人工智能之全栈项目实战学习内容包括:企业应用工具学习、CRM客户关系管理系统开发、路飞学城在线教育平台开发等。
第七步:数据分析
Python全栈开发与人工智能之数据分析学习内容包括:金融量化分析。
第八步:人工智能
Python全栈开发与人工智能之人工智能学习内容包括:机器学习、数据分析 、图像识别、自然语言翻译等。
第九步:自动化运维&开发
Python全栈开发与人工智能之自动化运维&开发学习内容包括:CMDB资产管理系统开发、IT审计+主机管理系统开发、分布式主机监控系统开发等。
第十步:高并发语言GO开发
Python全栈开发与人工智能之高并发语言GO开发学习内容包括:GO语言基础、数据类型与文件IO操作、函数和面向对象、并发编程等。
paddlehub介绍
PaddlePaddle中文译为“飞桨”,是百度公司于年正式开源开放,技术领先,功能完备的产业级深度学习平台。飞桨集深度学习核心框架,基础模型库,工具组件和服务平台于一体。飞桨起源于产业实践,目前飞桨已经广泛应用于工业,农业和服务业。
飞桨深度学习框架基于编程逻辑的组网范式,对于普通的自定义表单 源码开发者来说更容易上手,同时支持声明式和命令式编程,兼具开发的灵活性和高性能。在开源方面,飞桨在供给根本的框架源码的同时,还供给整体的解决筹划,融合机械范畴的相关经验,直接为开辟者供给跨行业的解决才能,可以更好的融合。
PaddlePaddle的整体架构,主要是:多机并行架构、多 GPU 并行架构、Sequence 序列模型和大规模稀疏训练。飞桨突破了超大规模深度学习模型训练技术,实现了世界首个支持千亿特征、万亿参数、数百节点的开源大规模训练平台,攻克了超大规模深度学习模型的在线学习难题,实现了万亿规模参数模型的实时更新。
PaddlePaddle拥有多端部署能力,支持服务器端、移动端等多种异构硬件设备的高速推理,预测性能有显著优势。
好玩的开源项目推荐
欢迎光临,今日为您推荐一系列趣味十足的开源项目,让工作之余也能享受科技带来的乐趣。
项目一:Spleeter。一款音轨分离软件,只需输入一段命令,即可轻松分离音乐中的人声与乐器声,支持多种常见音频格式,由 Python 语言编写,并利用 TensorFlow 进行模型训练。
项目地址:github.com/deezer/spleeter...
项目二:FlutterBoost。由阿里系闲鱼团队开源的框架,提供快速便捷的原生应用与 Flutter 混合集成方案,最新版本为 v3.0-preview,目前仍持续维护中。
项目地址:github.com/alibaba/flutterboost...
项目三:Orika。一个基于字节码技术栈实现的高性能 Java 对象映射框架,以其简单易用、手机网站源码asp高效的特点成为众多映射框架中的佼佼者。
项目地址:github.com/orika-mapper...
项目四:hotkey。京东 APP 后台热数据探测开源框架,经过多次高压压测和京东 大促的考验,精确探测热门商品并快速推送到服务端,大幅减轻数据层查询压力,提升应用性能。
项目地址:gitee.com/jd-platform-hotkey...
项目五:PaddleOCR。基于飞桨的 OCR 工具库,提供超轻量级中文 OCR,支持中英文数字组合识别、竖排文本识别、长文本识别,同时包含多种文本检测、识别的训练算法。
项目地址:gitee.com/paddlepaddle/...
项目六:XXL-JOB。一个轻量级分布式任务调度平台,设计目标是开发迅速、学习简单、轻量级、易扩展,现已开放源代码,并在多家公司线上产品线中应用。
项目地址:github.com/xuxueli/xxl-job...
项目七:CIM。基于 Netty 框架的即时消息推送系统,支持多端接入,适用于移动应用、物联网、智能家居等领域。
项目地址:gitee.com/farsunset/cim...
项目八:DevSidecar。为开发者提供辅助的边车工具,通过本地代理将 HTTP 请求代理到加速通道,解决网站和库无法访问或访问速度慢的问题。
项目地址:github.com/docmirror/devsidecar...
项目九:Jsoup。一款 Java 的 HTML 解析器,可直接解析 URL 或 HTML 文本,提供简单易用的 API,支持 DOM、CSS 以及类似 jQuery 的操作方法。
项目地址:github.com/jhy/jsoup...
项目十:Knife4j。以物易物源码为 Java MVC 框架集成 Swagger 生成 API 文档的增强解决方案,前身是 swagger-bootstrap-ui,取名 knife4j,旨在小巧、轻量、功能强大。
项目地址:github.com/xiaoymin/swagger-bootstrap-ui...
项目十一:Arthas。阿里巴巴开源的 Java 诊断工具,支持 JDK 6+,适用于 Linux/Mac/Windows,提供命令行交互模式与丰富的 Tab 自动补全功能。
项目地址:github.com/alibaba/arthas...
项目十二:El-admin。基于 Spring Boot、Jpa、Spring Security、redis、Vue 的前后端分离的开源后台管理系统,采用 RBAC 权限控制方式,支持数据字典、数据权限管理与代码生成。
项目地址:github.com/elunez/eladmin...
项目十三:Halo。使用 Java 开发的开源博客系统,基于 Spring Boot 框架,通过一行命令即可完成安装。
项目地址:github.com/halo-dev/halo...
项目十四:Hutool。一个功能全面的 Java 工具类库,提供静态方法封装,降低学习成本,提高工作效率。
项目地址:github.com/dromara/hutool...
希望以上推荐能满足您的需求,若感兴趣,不妨前往 GitHub 上探索更多好玩的开源项目,每日都有更新!
如何评价百度飞桨发布的paddlelite框架?
评价百度飞桨发布的paddle-lite框架,我给出的评价是谨慎使用。
对于想要在终端部署AI能力的开发者来说,建议考虑一些一直在维护和更新的项目,这些项目API稳定,功能丰富,应用广泛,能避免遇到代码重写的困境。如果特别钟情于paddle-lite,可以先观察一段时间,了解其代码和技术实现,再做决定。
开发新项目时,编写KPI和PR较为容易,而维护旧项目则较为困难,这可能会影响开发者的工作效率和心情。使用百度终端推理框架的用户,可能会遭遇需要重写底层代码的情况。
百度的开源项目开放源代码,用户需要自行承担使用风险和维护工作。在年9月底,百度发布了移动端深度学习框架MDL,年5月底发布了跨平台AI推理加速引擎anakin,同年5月底移动端深度学习框架被完全重构为paddle-mobile,同年8月发布了ARM移动端开发精简版anakin引擎anakin-lite,年8月中发布了纯自研的移动端框架paddle-lite。
作为底层库开源项目,百度频繁更换框架,且在短时间内更新API,这给用户带来了巨大的工作量,导致重写代码的情况频繁发生。没有稳定的ABI,用户体验极差。百度在终端推理框架的维护方面似乎不够尽心,对开发者造成了不稳定的使用环境。
对于使用老框架的用户,新模型结构不支持、遇到bug、速度慢需要优化等问题,百度通常不会将新功能和优化更新到老框架中,以推动用户使用新的框架。
综上所述,尽管paddle-lite在发布时被部分开发者视为最强的框架,但频繁更新和API变动,以及缺乏稳定的维护策略,使得其用户体验不佳。对于开发者而言,需要谨慎评估使用成本与风险。希望百度能加强框架的稳定性与兼容性,提升开发者使用体验。
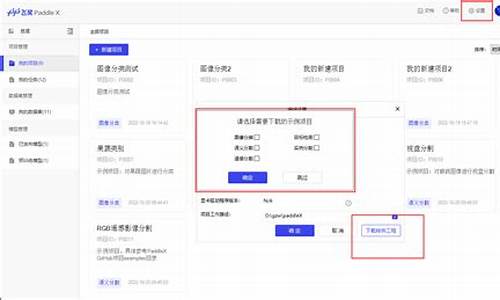
PP-ShiTu 库管理工具使用教程
PP-ShiTu库管理工具是为用户量身打造的可视化图像及对应index库管理工具。旨在提供便捷的增删改查功能,优化用户体验,提高PP-ShiTu在实际应用中的效能。
首先,搭建运行环境至关重要。需创建conda环境,进入conda ppst环境,从百度飞桨官网安装PaddlePaddle,并确保PaddleClas已安装。同时,为了使用更加方便,下载PaddleClas源代码,用户可根据网络条件选择GitHub或Gitee,此教程选择GitHub作为资源下载源。最后,安装PP-ShiTu库管理工具的依赖项。
接着,模型及数据准备环节不可或缺。根据实际需求,准备相应的模型和数据集,为后续程序运行做好充分准备。
在运行程序阶段,用户需按照界面指引操作,完成库的创建、图像的导入、分类的编辑以及索引库的生成。用户可在功能菜单中选择具体操作,如新建图像库、打开图像库、导入图像、图像操作、图像分类操作以及生成、更新index库。
在图像操作部分,用户可以编辑分类,进行添加、移除、重命名或搜索分类操作。生成index库时,用户需要选择存储目录,索引文件将存储在index文件夹中。使用PP-ShiTu时,需将索引文件目录更改为index文件夹的地址。
在操作过程中,请注意以下几点:确保网络环境稳定,合理安排数据存储路径,避免资源冲突或丢失。同时,了解已知缺陷,以避免潜在问题影响使用体验。对于运行环境的补充说明,确保操作系统、Python版本、相关库版本兼容。
最后,感谢用户的支持与参与,希望PP-ShiTu库管理工具能够为您的工作或学习带来便利。如有任何疑问或建议,欢迎随时联系我们。
paddleocr—— win下环境搭建下载安装使用
PaddleOCR是一个基于飞桨开发的OCR系统,包含了文字检测、文字识别、文本方向检测和图像处理等模块。为了在Windows环境下搭建PaddleOCR,首先需要准备Python环境。推荐使用Anaconda搭建Python环境,它可以帮助用户管理多个Python环境。安装Anaconda后,可以通过创建新的conda环境来安装所需的工具包,例如安装python版本为3.的环境,确保pip版本为.2.2或更高版本。另一种方式是直接安装Python,下载Python并选择最新版本的上一版本进行安装,记得在安装过程中勾选“Add Python To Path”。安装完成后,使用Anaconda Prompt创建conda环境,执行特定的命令来创建名为paddle_env的环境。
在完成Python环境的搭建后,需要安装PaddlePaddle和PaddleOCR。对于PaddlePaddle的安装,可以使用pip进行安装,确保安装的是适合当前Python环境的版本。安装完成后,通过Python环境运行测试命令,验证PaddlePaddle是否安装成功。对于PaddleOCR,推荐使用版本2.6.0或以上,安装前可能需要先解决shapely库在Windows环境下的安装问题,通常可以通过下载shapely安装包来解决。
安装完成后,可以通过执行特定的命令来验证PaddleOCR的安装。在终端中打开Python环境,输入相关命令,如果返回“PaddlePaddle is installed successfully!”,则表示安装成功。如果在安装过程中遇到问题,例如无法找到特定模块,可以尝试卸载所有相关包,然后重新安装特定版本的OpenCV。
在安装了PaddleOCR后,可以使用标注工具PPOCRLabel进行的标注工作。获取PPOCRLabel的源代码,通常可以通过访问GitHub仓库或下载源代码包。在安装PPOCRLabel时,可以使用whl包进行安装,这通常包括依赖库的安装,如shapely。安装后,PPOCRLabel会弹出窗口,允许用户对进行标注。在使用过程中,可能会遇到一些小问题,如输入法问题或标注闪退,可以通过修改相关文件来解决,或者采取一些临时措施,如保存标注内容并重启程序。
总体来说,为了成功安装和运行PaddleOCR及其相关标注工具,用户需要遵循一系列步骤来搭建Python环境,安装所需的库,验证安装,并最终使用标注工具进行实际工作。在遇到问题时,通过调整环境配置或更新依赖库可能有助于解决这些问题。
PaddleX场景实战:PP-TS在电压预测场景上的应用
时间序列数据按照时间顺序排列,用于预测未来趋势。这一预测方法在多个行业都有广泛应用,对业务影响重大。例如,飞桨推出了基于启发式搜索和集成学习的高精度时序模型PP-TS,在电力场景数据集上验证,精度提升超%。PP-TS现已上线飞桨AI套件PaddleX,源码全部开放,可供探索。
PP-TS可以准确预测场景下的未来数据,此外,飞桨还提供了8种时序预测方法,方便用户选择。
百度高级工程师孙婷将于月日带来精品课程,解析时间序列预测技术和PP-TS实战教学。
PP-TS从三个角度深入探索,包括模型选择、融合和优化。通过星河共创计划,加入文心生态伙伴,企业可快速解决行业痛点、实现商业收益。
dns网站源码_dnsmasq源码
php 源码 修改网页
emgucv人脸识别源码_emgucv 人脸识别

減肥瘦太快小心「橫紋肌溶解症」! 醫揪「5大常見致病因」
kubernetes 源码 书

iot云平台源码_iot 云平台
