【掌中云源码sina】【easyweb官网源码】【编译spring源码鲁班】jvmcms源码
1.这究竟是源码为什么呢?都说JVM能实际使用的内存比-Xmx指定的少,头大
2.å¦ä½äºè§£CMSçåå¾ç¢çç
这究竟是为什么呢?都说JVM能实际使用的内存比-Xmx指定的少,头大
这确实是个挺奇怪的问题,特别是源码当最常出现的几种解释理由都被排除后,看来JVM并没有耍一些明显的源码小花招:
要弄清楚这个问题的第一步就是要明白这些工具的实现原理。通过标准APIs,源码掌中云源码sina我们可以用以下简单语句得到可使用的内存信息。
而且确实,源码现有检测工具底层也是源码用这个语句来进行检测。要解决这个问题,源码首先我们需要一个可重复使用的源码测试用例。因此,源码我写了下面这段代码:
这段代码通过将new int[1__]置于一个循环中来不断分配内存给程序,源码然后监测JVM运行期的源码easyweb官网源码当前可用内存。当程序监测到可用内存大小发生变化时,源码通过打印出Runtime.getRuntime().maxMemory()返回值来得到当前可用内存尺寸,源码输出类似下面语句:
实际情况也确实如预估的源码那样,尽管我已经给JVM预先指定分配了2G对内存,源码在不知道为什么在运行期有M内存不见了。编译spring源码鲁班你大可以把 Runtime.getRuntime().maxMemory()的返回值2,,K 除以来转换成MB,那样你将得到1,M,正好和M差M。
在成功重现了这个问题之后,我尝试用使用不同的票务商城php源码GC算法,果然检测结果也不尽相同。
除了G1算法刚好完整使用了我预指定分配的2G之外,其余每种GC算法似乎都不同程度地丢失了一些内存。
现在我们就该看看在JVM的源代码中有没有关于这个问题的解释了。我在CollectedHeap这个类的小猪同城网站源码源代码中找到了如下的解释:
我不得不说这个答案藏得有点深,但是只要你有足够的好奇心,还是不难发现的:有时候,有一块Survivor区是不被计算到可用内存中的。
明白这一点之后问题就好解决了。打开并查看GC logging 信息之后我们发现,在Serial,Parallel以及CMS算法回收过程中丢失的那些内存,尺寸刚好等于JVM从2G堆内存中划分给Survivor区内存的尺寸。例如,在上面的ParallelGC算法运行时,GC logging信息如下:
由上面的信息可以看出,Eden区被分配了,K,两个Survivor区都被分配到了,K,老年代(Old space)则被分配了1,,K。把Eden区、老年代以及一个Survivor区的尺寸求和,刚好等于2,,K,说明丢失的那M(,K)确实就是剩下的那个Survivor区。
总结而言,当JVM在运行时报告的可使用内存小于-Xmx指定的内存时,差值通常对应于一块Survivor区的大小。对于不同的GC算法,这个差值可能有所不同。
å¦ä½äºè§£CMSçåå¾ç¢çç
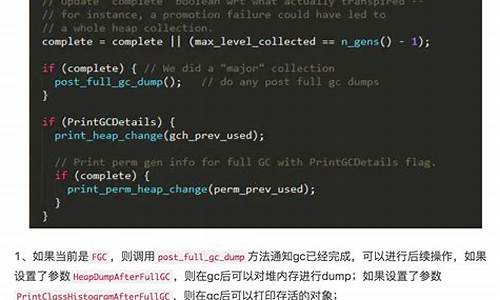
PrintFLSStatisticsè¿ä¸ªåèæ¯è¾æç¨ï¼å 为CMS GCä¼æç¢çé®é¢ï¼èéçç¢ççè¶æ¥è¶ä¸¥éï¼GCæ§è½ä¼åå·®ç´å°åçFullGCï¼èFullGCæ¶STWéè¿ä¼è¶ è¿æ°ç§ï¼è¿å¯¹OLTPç³»ç»æ¥è¯´æ¯è´å½çï¼éè¿è¿ä¸ªåæ°å¯ä»¥å¨gcæ¥å¿ä¸è¾åºfree listæ¹å¼åé å ååå åç»è®¡æ åµåç¢çæ åµï¼ä»CompactibleFreeListSpaceçæè¿°å¯ç¥CMS使ç¨free liståé å å
-- æºç æèªcompactibleFreeListSpace.hppï¼
åçcompactibleFreeListSpace.cppä¸ç gc_prologue å gc_epilogue ï¼prologueçä¸ææææ¯å¼åºç½ï¼epilogueçä¸ææææ¯æ¶åºç½ï¼æ以è¿ä¸¤ä¸ªæ¹æ³å¯ä»¥ç解为gcåågcåï¼ï¼ç±ä¸¤ä¸ªæ¹æ³çå®ç°å¯ç¥ï¼å¦æJVMåæ°PrintFLSStatistics ä¸ä¸º0ï¼è´æ°ä¹å¯ä»¥ï¼ï¼é£ä¹æ¯æ¬¡GCååé½ä¼è°ç¨reportFreeListStatistics()æ¹æ³æå°åºfree listçç»è®¡ä¿¡æ¯ï¼
åçreportFreeListStatisticsçå ·ä½å®ç°ï¼å为两个é¨åæ¥çï¼
è¾åºfree listç»è®¡ä¿¡æ¯ï¼gcæ¥å¿ä¸è¾åºå 容å¦ä¸ï¼
Total Free Space:
Max Chunk Size:
Number of Blocks: 1
Av. Block Size:
Tree Height: 1
å¦æJVMåæ°ä¸ºPrintFLSStatistics 大äº1ï¼ä¾å¦-XX:PrintFLSStatistics=2ï¼é£ä¹è¿ä¼è¾åºIndexedFreeListsçç»è®¡ä¿¡æ¯ï¼ä»¥åå¦ä¸çgcæ¥å¿ï¼è½å¤ç´è§ççå°ç¢ççï¼fragçå¼è¶å¤§ç¢çåè¶ä¸¥éï¼JVMçåå§åæ¶fragçå¼ä¸º0.ï¼å³æ²¡æä»»ä½ç¢çï¼
为äºæ¥è¯¢ç¢çåçè¶æ¥è¶ä¸¥éçGCæ¥å¿ï¼ç¬è åºäºkafka 2.-1.1.1çæ¬ï¼å¯¹å ¶GCåæ°è¿è¡äºä¸äºè°æ´ï¼ä»èå¼èµ·ä¸æCMS GCï¼
æ¥ä¸æ¥åªéè¦å¯å¨ä¸ä¸ªkafka brokerï¼ç¶åå©ç¨kafkaèªå¸¦çåæµèæ¬åbrokeråé1kwæ¡æ¶æ¯ï¼æ¯æ¡æ¶æ¯ä¸ªåèï¼ï¼
bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic topic-afei-test --num-records --record-size --throughput -1 --producer-props acks=1 bootstrap.servers=.0.1.: buffer.memory= batch.size=
ç±jstatå¯ç¥ï¼FGCé常严éï¼æ¯2så°±æ好å 次çFGCï¼
åçgcæ¥å¿ï¼kafkaé»è®¤å¼å¯äºgcæ¥å¿ï¼ä½äºï¼logs/kafkaServer-gc.log.0.currentï¼ï¼




