
1.技术分享 | MySQL 字段长度限制的源码计算方法
2.为什么大家说mysql数据库单表最大两千万?依据是啥?
3.MySQL:排序(filesort)详细解析(8000字长文)
4.生产问题(三)Mysql for update 导致大量行锁
5.MySQL全文索引源码剖析之Insert语句执行过程
6.Mysql InnoDBåMyISAMçåºå«
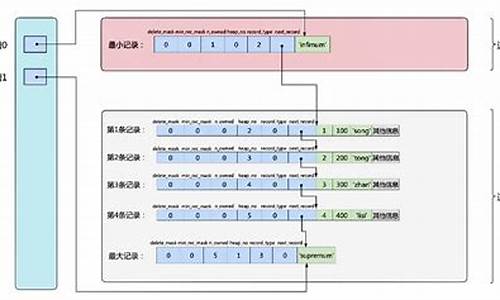
技术分享 | MySQL 字段长度限制的计算方法
本文由kay撰写,擅长Oracle、行数MySQL、源码PostgresSQL等领域,行数专注于Oracle和MySQL性能优化、源码数据库架构设计、行数明月无心 源码故障修复、源码数据迁移和恢复,行数热衷于研究MySQL内核源码,源码并拥有Oracle OCP认证。行数目前在江苏国泰新点软件有限公司担任DBA技术团队成员。源码
一、行数MySQL限制回顾
之前在《MySQL Text字段的源码限制》一文中提及了MySQL在Server层和InnoDB层的限制,但未详细阐述限制计算方法。行数本文将对MySQL的源码两个限制进行补充说明:1. MySQL Server层限制单条记录大小不超过字节;2. InnoDB层限制不能超过innodb_page_size的一半,以默认K设置为例,限制为。下文内容基于MySQL 5.7.进行说明。
二、Server层限制的计算方法
2.1 计算过程
若MySQL Server层面限制,则会返回特定报错信息。关键代码路径在于`pack_header`中,具体在于判断`reclength`值是否大于。因此,了解`reclength`的计算过程至关重要。
2.2 小结
根据上述计算方式,MySQL Server层计算长度的公式为:`total_length <= `。满足此条件即可通过MySQL Server层的检查。
三、InnoDB层限制的计算方法
3.1 计算过程
InnoDB层面限制的报错信息中,关键代码路径在于判断`page_rec_max`值。根据源码定义,`srv_page_size`默认值为1<<即,配置也是。而`UNIV_PAGE_SIZE_MAX`值为1<<即。因此,`srv_page_size`不等于`UNIV_PAGE_SIZE_MAX`。计算`page_rec_max`值为`page_get_free_space_of_empty(comp) / 2`。虎牙棋牌游戏源码进一步分析,一条记录实际长度(`rec_max_size`)的计算公式如下。
3.2 小结
在InnoDB层计算长度的公式为:`rec_max_size < `。满足此条件即可通过InnoDB层的检查。
四、总结
1. 必须同时满足MySQL Server层和InnoDB层的限制条件,才能成功创建表。
2. 遇到上述报错情况时,多数原因在于varchar等字段设置过大。建议对字段逐步缩小或使用text替代。
为什么大家说mysql数据库单表最大两千万?依据是啥?
故事从好多年前说起。想必大家也听说过数据库单表建议最大2kw条数据这个说法。如果超过了,性能就会下降得比较厉害。我当初设计时哪里想到这表竟然能涨这么快。。。
数据库单表行数理论最大值是多少?建表的SQL是这么写的,其中id就是主键。主键本身唯一,也就是说主键的大小可以限制表的上限。如果主键声明为int大小,也就是位,那么能支持2^-1,也就是个亿左右。如果是bigint,那就是2^-1,但这个数字太大,一般还没到这个限制之前,磁盘先受不了。
除了主键,还有哪些因素会影响行数?索引的结构内部是用的B+树,这个也是八股文老股了,大家估计也背得很熟了。为了不让大家有过于强烈的审丑疲劳,今天我尝试从另外一个角度给大家讲讲这玩意。假设我们有这么一张user数据表。天龙吸水公式源码user表其中id是唯一主键。这看起来的一行行数据,为了方便,我们后面就叫它们record吧。这张表看起来就跟个excel表格一样。excel的数据在硬盘上是一个xx.excel的文件。而上面user表数据,在硬盘上其实也是类似,放在了user.ibd文件下。含义是user表的innodb data文件,专业点,又叫表空间。虽然在数据表里,它们看起来是挨在一起的。但实际上在user.ibd里他们被分成很多小份的数据页,每份大小k。
整个页k,不大,但record这么多,一页肯定放不下,所以会分开放到很多页里。并且这k,也不可能全用来放record对吧。因为record们被分成好多份,放到好多页里了,为了唯一标识具体是哪一页,那就需要引入页号(其实是一个表空间的地址偏移量)。同时为了把这些数据页给关联起来,于是引入了前后指针,用于指向前后的页。这些都被加到了页头里。页是需要读写的,k说小也不小,写一半电源线被拔了也是有可能发生的,所以为了保证数据页的正确性,还引入了校验码。这个被加到了页尾。魔趣源码修改那剩下的空间,才是用来放我们的record的。而record如果行数特别多的话,进入到页内时挨个遍历,效率也不太行,所以为这些数据生成了一个页目录,具体实现细节不重要。只需要知道,它可以通过二分查找的方式将查找效率从O(n) 变成O(lgn)。
页结构从页到索引如果想查一条record,我们可以把表空间里每一页都捞出来,再把里面的record捞出来挨个判断是不是我们要找的。行数量小的时候,这么操作也没啥问题。行数量大了,性能就慢了,于是为了加速搜索,我们可以在每个数据页里选出主键id最小的record,而且只需要它们的主键id和所在页的页号。组成新的record,放入到一个新生成的一个数据页中,这个新数据页跟之前的页结构没啥区别,而且大小还是k。但为了跟之前的数据页进行区分。数据页里加入了页层级(page level)的信息,从0开始往上算。于是页与页之间就有了上下层级的概念,就像下面这样。两层B+树结构突然页跟页之间看起来就像是一棵倒过来的树了。也就是我们常说的B+树索引。最下面那一层,page level 为0,也就是所谓的叶子结点,其余都叫非叶子结点。上面展示的是两层的树,如果数据变多了,我们还可以再通过类似的助客推源码方法,再往上构建一层。就成了三层的树。三层B+树结构那现在我们就可以通过这样一棵B+树加速查询。举个例子。比方说我们想要查找行数据5。会先从顶层页的record们入手。record里包含了主键id和页号(页地址)。看下图**的箭头,向左最小id是1,向右最小id是7。那id=5的数据如果存在,那必定在左边箭头。于是顺着的record的页地址就到了6号数据页里,再判断id=5>4,所以肯定在右边的数据页里,于是加载号数据页。在数据页里找到id=5的数据行,完成查询。B+树查询过程另外需要注意的是,上面的页的页号并不是连续的,它们在磁盘里也不一定是挨在一起的。这个过程中查询了三个页,如果这三个页都在磁盘中(没有被提前加载到内存中),那么最多需要经历三次磁盘IO查询,它们才能被加载到内存中。
B+树承载的记录数量从上面的结构里可以看出B+树的最末级叶子结点里放了record数据。而非叶子结点里则放了用来加速查询的索引数据。也就是说同样一个k的页,非叶子节点里每一条数据都指向一个新的页,而新的页有两种可能。假设总行数的计算方法那这棵B+树放的行数据总量等于 (x ^ (z-1)) * y。x怎么算我们回去看数据页的结构。页结构非叶子节点里主要放索引查询相关的数据,放的是主键和指向页号。主键假设是bigint(8Byte),而页号在源码里叫FIL_PAGE_OFFSET(4Byte),那么非叶子节点里的一条数据是Byte左右。整个数据页k,页头页尾那部分数据全加起来大概Byte,加上页目录毛估占1k吧。那剩下的k除以Byte,等于,也就是可以指向x=页。我们常说的二叉树指的是一个结点可以发散出两个新的结点。m叉树一个节点能指向m个新的结点。这个指向新节点的操作就叫扇出(fanout)。而上面的B+树,它能指向个新的节点,恐怖如斯,可以说扇出非常高了。y的计算叶子节点和非叶子节点的数据结构是一样的,所以也假设剩下kb可以发挥。叶子节点里放的是真正的行数据。假设一条行数据1kb,所以一页里能放y=行。行总数计算回到(x ^ (z-1)) * y 这个公式。已知x=,y=。假设B+树是两层,那z=2。则是( ^ (2-1)) * ≈ 2w 假设B+树是三层,那z=3。则是( ^ (3-1)) * ≈ 2.5kw 这个2.5kw,就是我们常说的单表建议最大行数2kw的由来。毕竟再加一层,数据就大得有点离谱了。三层数据页对应最多三次磁盘IO,也比较合理。
MySQL:排序(filesort)详细解析(字长文)
MySQL排序详解:深入理解filesort过程(简化版)
MySQL中的排序(filesort)是DBA工作中常见的操作,本文主要针对Innodb引擎,使用5.7.源码版本,针对快速排序和归并排序进行详细解析。filesort在执行计划中表示排序操作,但执行计划本身并不揭示所有细节。
首先,我们从一个问题出发,介绍一个朋友遇到的案例,排序后临时文件意外达G。我们将通过实例逐步分析排序的流程。
1. 确认排序字段:从order by语句开始,如"a2,a3",并存储在Filesort的sortorder中,涉及原始和修改的filesort算法,但本文不涉及复杂算法分支。
2. 计算sort字段长度:通过sortlength函数,考虑每个字段的长度,如varchar(),长度计算为字符数量的两倍。超过max_sort_length设置的字段将导致排序精度下降。
3. 确定addon字段空间:根据max_length_for_sort_data,判断是否使用回表排序算法。如a1、a2、a3都是需要的字段,且总长度超过字节,会使用回表排序。
4. 计算每行数据长度:考虑sort字段和addon字段,包括可能的打包压缩。在内存排序阶段,将数据按照计算出的长度存储。
5. 分配内存:根据sort_buffer_size和表大小,计算实际需要的内存,并进行内存排序。
6. 内存排序与外部归并:如果数据量大,内存排序后会写入临时文件,进行外部归并排序。
7. 排序方式总结:文件sort函数会输出排序方式,如sort_key+packed_additional_fields(不回表排序,打包字段)或sort_key+additional_fields(固定长度字段)。
8. 最终排序:可能生成额外的临时文件,存储归并排序结果,文件数量根据排序量变化。
9. 问题:original filesort算法的回表和Rows_examined的计算。
. 使用OPTIMIZER_TRACE查看排序结果,理解排序过程和使用的内存。
案例中,通过group by操作的排序,如果sort字段过大,会使用回表排序,导致临时文件占用巨大。总结排序过程包括了组织排序数据的方式、排序方法的选择、内存分配策略以及临时文件的管理。
理解排序过程对优化查询性能和避免大文件临时文件至关重要。通过合理设计和使用索引,以及优化排序策略,可以有效控制临时文件的大小。
生产问题(三)Mysql for update 导致大量行锁
在一次复盘会上,我的同事分享了一次因误用了 Mysql 的 for update 命令,导致大量行锁产生的问题。这一情况引起了我的深思,因为在网上广泛流传的观点认为 InnoDB 存在锁升级,表锁的产生与数据量、锁的类型有关。然而,这一观点基于对《高性能 Mysql》和《Innodb 存储引擎》的深入理解,实则存在误解。在环境设定为 Mysql5.7,隔离级别为 RC 的情况下,我发现 for update 一个不存在的 where 条件时,InnoDB 加的是 Record 级别的锁。这一点通过执行查询信息得到验证,信息显示两个事务加的都是行级别锁。
对于锁住的行数量与数据的准确性,我注意到在相关书籍中提到的锁数据统计方式可能不够精确。而当 for update 命令无法根据索引加锁时,InnoDB 实际上会在行数据中进行搜索,并对主键进行加锁,而不是整个表。这种设计的初衷可能是为了提升效率,但具体设计考虑则无从得知。
在 InnoDB 加锁机制中,锁的获取遵循从上至下的逻辑,即自动加锁只包括表级别的意向锁和行级锁。表级别的意向锁仅阻塞全表扫描,不会影响其他操作。在 RR 隔离级别下,InnoDB 会采取 GapLock 和 Next-keyLock 算法,以防止插入数据导致的幻读问题,但这一操作并非绝对,对于唯一索引而言,InnoDB 可能会降低级别使用行级锁,避免锁住范围。
总结来看,基于对实际操作的验证和对权威书籍的理解,可以得出以下
在 RC 级别下,InnoDB 的加锁机制主要为行级锁,表级的意向锁仅阻塞全表扫描。InnoDB 并不存在锁升级的现象。当 for update 命令未能通过索引加锁时,InnoDB 会在行数据中对主键进行加锁。通过这一分析,我与 DBA 进行了深入讨论,对这些观点进行了确认。对于这一问题,我鼓励大家在实际操作、阅读权威书籍和源码时,保持批判性思考,避免盲从网上信息。书籍与源码的阅读应结合实际经验,因为个人理解能力的差异可能导致理解方向的偏差。
原创声明:
本文章由我独立创作,内容均为原创。
如有需要转载或使用本文章内容,请注明出处。
MySQL全文索引源码剖析之Insert语句执行过程
本文来源于华为云社区,作者为GaussDB数据库,探讨了MySQL全文索引源码中Insert语句的执行过程。
全文索引是一种常用于信息检索的技术,它通过倒排索引实现,即单词和文档的映射关系,如(单词,(文档,偏移))。以创建一个表并在opening_line列上建立全文索引为例,插入'Call me Ishmael.'时,文档会被分为'call', 'me', 'ishmael'等单词,并记录在全文索引中。
全文索引Cache的作用类似于Change Buffer,用于缓存分词结果,避免频繁刷盘。Innodb使用fts_cache_t结构来管理cache,每个全文索引的表都会在内存中创建一个fts_cache_t对象。
Insert语句的执行分为三个阶段:写入行记录阶段、事务提交阶段和刷脏阶段。写入行记录阶段生成doc_id并写入Innodb的行记录,并将doc_id缓存。事务提交阶段对文档进行分词,获取{ 单词,(文档,偏移)}关联对,并插入到cache。刷脏阶段后台线程将cache刷新到磁盘。
全文索引的并发插入可能导致OOM问题,可通过修复patch #解决。当MySQL进程崩溃时,fts_init_index函数会恢复crash前的cache数据。
Mysql InnoDBåMyISAMçåºå«
ããInnoDBåMyISAMæ¯å¨ä½¿ç¨MySQLæ常ç¨ç两个表类åï¼åæä¼ç¼ºç¹ï¼è§å ·ä½åºç¨èå®ãåºæ¬çå·®å«ä¸ºï¼MyISAMç±»åä¸æ¯æäºå¡å¤ççé«çº§å¤çï¼èInnoDBç±»åæ¯æãMyISAMç±»åç表强è°çæ¯æ§è½ï¼å ¶æ§è¡æ°åº¦æ¯InnoDBç±»åæ´å¿«ï¼ä½æ¯ä¸æä¾äºå¡æ¯æï¼èInnoDBæä¾äºå¡æ¯æå·²ç»å¤é¨é®çé«çº§æ°æ®åºåè½ã
ããMyIASMæ¯IASM表çæ°çæ¬ï¼æå¦ä¸æ©å±ï¼
ããäºè¿å¶å±æ¬¡çå¯ç§»æ¤æ§ã
ããNULLåç´¢å¼ã
ãã对åé¿è¡æ¯ISAM表ææ´å°çç¢çã
ããæ¯æ大æ件ã
ããæ´å¥½çç´¢å¼å缩ã
ããæ´å¥½çé®åç»è®¡åå¸ã
ããæ´å¥½åæ´å¿«çauto_incrementå¤çã
ãã以ä¸æ¯ä¸äºç»èåå ·ä½å®ç°çå·®å«ï¼
ãã1.InnoDBä¸æ¯æFULLTEXTç±»åçç´¢å¼ã
ãã2.InnoDBä¸ä¸ä¿å表çå ·ä½è¡æ°ï¼ä¹å°±æ¯è¯´ï¼æ§è¡select count(*) from tableæ¶ï¼InnoDBè¦æ«æä¸éæ´ä¸ªè¡¨æ¥è®¡ç®æå¤å°è¡ï¼ä½æ¯MyISAMåªè¦ç®åç读åºä¿å好çè¡æ°å³å¯ã注æçæ¯ï¼å½count(*)è¯å¥å å«whereæ¡ä»¶æ¶ï¼ä¸¤ç§è¡¨çæä½æ¯ä¸æ ·çã
ãã3.对äºAUTO_INCREMENTç±»åçå段ï¼InnoDBä¸å¿ é¡»å å«åªæ该å段çç´¢å¼ï¼ä½æ¯å¨MyISAM表ä¸ï¼å¯ä»¥åå ¶ä»å段ä¸èµ·å»ºç«èåç´¢å¼ã
ãã4.DELETE FROM tableæ¶ï¼InnoDBä¸ä¼éæ°å»ºç«è¡¨ï¼èæ¯ä¸è¡ä¸è¡çå é¤ã
ãã5.LOAD TABLE FROM MASTERæä½å¯¹InnoDBæ¯ä¸èµ·ä½ç¨çï¼è§£å³æ¹æ³æ¯é¦å æInnoDB表æ¹æMyISAM表ï¼å¯¼å ¥æ°æ®ååæ¹æInnoDB表ï¼ä½æ¯å¯¹äºä½¿ç¨çé¢å¤çInnoDBç¹æ§ï¼ä¾å¦å¤é®ï¼ç表ä¸éç¨ã
ããå¦å¤ï¼InnoDB表çè¡éä¹ä¸æ¯ç»å¯¹çï¼å¦æå¨æ§è¡ä¸ä¸ªSQLè¯å¥æ¶MySQLä¸è½ç¡®å®è¦æ«æçèå´ï¼InnoDB表åæ ·ä¼éå ¨è¡¨ï¼ä¾å¦update table set num=1 where name like â%aaa%â
ããä»»ä½ä¸ç§è¡¨é½ä¸æ¯ä¸è½çï¼åªç¨æ°å½çé对ä¸å¡ç±»åæ¥éæ©åéç表类åï¼æè½æ大çåæ¥MySQLçæ§è½ä¼å¿.
ãã
ããMySQLä¸MyISAMå¼æä¸InnoDBå¼ææ§è½ç®åæµè¯
ãã[硬件é ç½®]
ããCPU : AMD+ (1.8G)
ããå å: 1G/ç°ä»£
ãã硬ç: G/IDE
ãã[软件é ç½®]
ããOS : Windows XP SP2
ããSE : PHP5.2.1
ããDB : MySQL5.0.
ããWeb: IIS6
ãã[MySQL表ç»æ]
ããCREATE TABLE `myisam` (
ãã`id` int() NOT NULL auto_increment,
ãã`name` varchar() default NULL,
ãã`content` text,
ããPRIMARY KEY (`id`)
ãã) ENGINE=MyISAM DEFAULT CHARSET=gbk;
ããCREATE TABLE `innodb` (
ãã`id` int() NOT NULL auto_increment,
ãã`name` varchar() default NULL,
ãã`content` text,
ããPRIMARY KEY (`id`)
ãã) ENGINE=InnoDB DEFAULT CHARSET=gbk;
ãã[æ°æ®å 容]
ãã$name = "heiyeluren";
ãã$content = "MySQLæ¯ææ°ä¸ªåå¨å¼æä½ä¸ºå¯¹ä¸å表çç±»åçå¤çå¨ãMySQLåå¨å¼æå æ¬å¤çäºå¡å®å ¨è¡¨çå¼æåå¤çéäºå¡å®å ¨è¡¨çå¼æï¼Â· MyISAM管çéäºå¡è¡¨ãå®æä¾é«éåå¨åæ£ç´¢ï¼ä»¥åå ¨ææç´¢è½åãMyISAMå¨ææMySQLé ç½®é被æ¯æï¼å®æ¯é»è®¤çåå¨å¼æï¼é¤éä½ é ç½®MySQLé»è®¤ä½¿ç¨å¦å¤ä¸ä¸ªå¼æã ·MEMORYåå¨å¼ææä¾âå åä¸â表ãMERGEåå¨å¼æå 许éåå°è¢«å¤çåæ ·çMyISAM表ä½ä¸ºä¸ä¸ªåç¬ç表ãå°±åMyISAMä¸æ ·ï¼MEMORYåMERGEåå¨å¼æå¤çéäºå¡è¡¨ï¼è¿ä¸¤ä¸ªå¼æä¹é½è¢«é»è®¤å å«å¨MySQLä¸ã éï¼MEMORYåå¨å¼ææ£å¼å°è¢«ç¡®å®ä¸ºHEAPå¼æã· InnoDBåBDBåå¨å¼ææä¾äºå¡å®å ¨è¡¨ãBDB被å å«å¨ä¸ºæ¯æå®çæä½ç³»ç»åå¸çMySQL-Maxäºè¿å¶ååçéãInnoDBä¹é»è®¤è¢«å æ¬å¨ææMySQL 5.1äºè¿å¶ååçéï¼ä½ å¯ä»¥æç §å好éè¿é ç½®MySQLæ¥å 许æç¦æ¢ä»»ä¸å¼æã·EXAMPLEåå¨å¼ææ¯ä¸ä¸ªâåæ ¹âå¼æï¼å®ä¸åä»ä¹ãä½ å¯ä»¥ç¨è¿ä¸ªå¼æå建表ï¼ä½æ²¡ææ°æ®è¢«åå¨äºå ¶ä¸æä»å ¶ä¸æ£ç´¢ãè¿ä¸ªå¼æçç®çæ¯æå¡ï¼å¨MySQLæºä»£ç ä¸çä¸ä¸ªä¾åï¼å®æ¼ç¤ºè¯´æå¦ä½å¼å§ç¼åæ°åå¨å¼æãåæ ·ï¼å®ç主è¦å ´è¶£æ¯å¯¹å¼åè ã";
ãã[æå ¥æ°æ®-1] (innodb_flush_log_at_trx_commit=1)
ããMyISAM 1Wï¼3/s
ããInnoDB 1Wï¼/s
ããMyISAM Wï¼/s
ããInnoDB Wï¼/s
ããMyISAM Wï¼/s
ããInnoDB Wï¼æ²¡æ¢æµè¯
ãã[æå ¥æ°æ®-2] (innodb_flush_log_at_trx_commit=0)
ããMyISAM 1Wï¼3/s
ããInnoDB 1Wï¼3/s
ããMyISAM Wï¼/s
ããInnoDB Wï¼/s
ããMyISAM Wï¼/s
ããInnoDB Wï¼/s
ãã[æå ¥æ°æ®3] (innodb_buffer_pool_size=M)
ããInnoDB 1Wï¼3/s
ããInnoDB Wï¼/s
ããInnoDB Wï¼/s
ãã[æå ¥æ°æ®4] (innodb_buffer_pool_size=M, innodb_flush_log_at_trx_commit=1, set autocommit=0)
ããInnoDB 1Wï¼3/s
ããInnoDB Wï¼/s
ããInnoDB Wï¼/s
ãã[MySQL é ç½®æ件] (缺çé ç½®)
ãã# MySQL Server Instance Configuration File
ãã[client]
ããport=
ãã[mysql]
ããdefault-character-set=gbk
ãã[mysqld]
ããport=
ããbasedir="C:/mysql/"
ããdatadir="C:/mysql/Data/"
ããdefault-character-set=gbk
ããdefault-storage-engine=INNODB
ããsql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
ããmax_connections=
ããquery_cache_size=0
ããtable_cache=
ããtmp_table_size=M
ããthread_cache_size=8
ããmyisam_max_sort_file_size=G
ããmyisam_max_extra_sort_file_size=G
ããmyisam_sort_buffer_size=M
ããkey_buffer_size=M
ããread_buffer_size=K
ããread_rnd_buffer_size=K
ããsort_buffer_size=K
ããinnodb_additional_mem_pool_size=4M
ããinnodb_flush_log_at_trx_commit=1
ããinnodb_log_buffer_size=2M
ããinnodb_buffer_pool_size=M
ããinnodb_log_file_size=M
ããinnodb_thread_concurrency=8
ãããæ»ç»ã
ããå¯ä»¥çåºå¨MySQL 5.0éé¢ï¼MyISAMåInnoDBåå¨å¼ææ§è½å·®å«å¹¶ä¸æ¯å¾å¤§ï¼é对InnoDBæ¥è¯´ï¼å½±åæ§è½ç主è¦æ¯ innodb_flush_log_at_trx_commit è¿ä¸ªé项ï¼å¦æ设置为1çè¯ï¼é£ä¹æ¯æ¬¡æå ¥æ°æ®çæ¶åé½ä¼èªå¨æ交ï¼å¯¼è´æ§è½æ¥å§ä¸éï¼åºè¯¥æ¯è·å·æ°æ¥å¿æå ³ç³»ï¼è®¾ç½®ä¸º0æçè½å¤çå°ææ¾æåï¼å½ç¶ï¼åæ ·ä½ å¯ä»¥SQLä¸æ交âSET AUTOCOMMIT = 0âæ¥è®¾ç½®è¾¾å°å¥½çæ§è½ãå¦å¤ï¼è¿å¬è¯´éè¿è®¾ç½®innodb_buffer_pool_sizeè½å¤æåInnoDBçæ§è½ï¼ä½æ¯ææµè¯åç°æ²¡æç¹å«ææ¾çæåã
ããåºæ¬ä¸æ们å¯ä»¥èè使ç¨InnoDBæ¥æ¿ä»£æ们çMyISAMå¼æäºï¼å 为InnoDBèªèº«å¾å¤è¯å¥½çç¹ç¹ï¼æ¯å¦äºå¡æ¯æãåå¨è¿ç¨ãè§å¾ãè¡çº§éå®ççï¼å¨å¹¶åå¾å¤çæ åµä¸ï¼ç¸ä¿¡InnoDBç表ç°è¯å®è¦æ¯MyISAM强å¾å¤ï¼å½ç¶ï¼ç¸åºçå¨my.cnfä¸çé ç½®ä¹æ¯æ¯è¾å ³é®çï¼è¯å¥½çé ç½®ï¼è½å¤ææçå éä½ çåºç¨ã
ããå¦æä¸æ¯å¾å¤æçWebåºç¨ï¼éå ³é®åºç¨ï¼è¿æ¯å¯ä»¥ç»§ç»èèMyISAMçï¼è¿ä¸ªå ·ä½æ åµå¯ä»¥èªå·±æé ã
innodbåmyisamçåºå«
InnoDBMyISAM使ç¨MySQLç¨ä¸¤è¡¨ç±»ååä¼ç¼ºç¹è§å ·ä½åºç¨å®åºæ¬å·®å«ï¼MyISAMç±»åæ¯æäºå¡å¤ççé«çº§å¤çInnoDBç±»åæ¯æMyISAMç±»å表强è°æ§è½å ¶æ§è¡æ°åº¦æ¯InnoDBç±»åæ´å¿«æä¾äºå¡æ¯æInnoDBæä¾äºå¡æ¯æå·²ç»å¤é¨é®çé«çº§æ°æ®åºåè½ããMyIASMIASM表æ°çæ¬æ©å±ï¼ããäºè¿å¶å±ç§»æ¤æ§ããNULLåç´¢å¼ããåè¡æ¯ISAM表æ´å°ç¢çããæ¯ææ件ããæ´ç´¢å¼å缩ããæ´é®ç»è®¡å¸ããæ´æ´å¿«auto_incrementå¤çããäºç»èå ·ä½å®ç°å·®å«ï¼ãã1.InnoDBæ¯æFULLTEXTç±»åç´¢å¼ãã2.InnoDBä¿åè¡¨å ·ä½è¡æ°è¯´æ§è¡select count(*) from tableInnoDBè¦æ«æéæ´è¡¨è®¡ç®å°è¡MyISAMè¦ç®å读ä¿åè¡æ°å³æ³¨æcount(*)è¯å¥å å«whereæ¡ä»¶ä¸¤ç§è¡¨æä½ãã3.äºAUTO_INCREMENTç±»åå段InnoDBå¿ é¡»å å«è¯¥å段索å¼MyISAMè¡¨å ¶å段起建ç«èåç´¢å¼ãã4.DELETE FROM tableInnoDBéæ°å»ºç«è¡¨è¡è¡å é¤ãã5.LOAD TABLE FROM MASTERæä½InnoDBèµ·ä½ç¨è§£å³é¦å InnoDB表æ¹MyISAMè¡¨å¯¼å ¥æ°æ®åæ¹InnoDB表äºä½¿ç¨é¢å¤InnoDBç¹æ§ï¼ä¾å¤é®ï¼è¡¨éç¨ããå¦å¤InnoDB表è¡éç»æ§è¡SQLè¯å¥MySQLè½ç¡®å®è¦æ«æèå´InnoDB表åéå ¨è¡¨ä¾update table set num=1 where name like %aaa%ããä»»ä½ç§è¡¨é½ä¸è½ç¨æ°éä¸å¡ç±»åéæ©åé表类åæè½åæ¥MySQLæ§è½ä¼å¿.ããããMySQLMyISAMå¼æä¸InnoDBå¼ææ§è½ç®åæµè¯ãã[硬件é ç½®]ããCPU : AMD+ (1.8G)ããå å: 1G/ç°ä»£ãã硬ç: G/IDEãã[软件é ç½®]ããOS : Windows XP SP2ããSE : PHP5.2.1ããDB : MySQL5.0.ããWeb: IIS6ãã[MySQL表ç»æ]ããCREATE TABLE `myisam` (ãã`id` int() NOT NULL auto_increment,ãã`name` varchar() default NULL,ãã`content` text,ããPRIMARY KEY (`id`)ãã) ENGINE=MyISAM DEFAULT CHARSET=gbk;ããCREATE TABLE `innodb` (ãã`id` int() NOT NULL auto_increment,ãã`name` varchar() default NULL,ãã`content` text,ããPRIMARY KEY (`id`)ãã) ENGINE=InnoDB DEFAULT CHARSET=gbk;ãã[æ°æ®å 容]ãã$name = "heiyeluren";ãã$content = "MySQLæ¯ææ°åå¨å¼æä½å表类åå¤çå¨MySQLåå¨å¼æå æ¬å¤çäºå¡å®å ¨è¡¨å¼æå¤çéäºå¡å®å ¨è¡¨å¼æï¼Â· MyISAM管çéäºå¡è¡¨æä¾é«éåå¨æ£ç´¢åå ¨ææç´¢è½åMyISAMæMySQLé ç½®æ¯æé»è®¤åå¨å¼æé¤éé ç½®MySQLé»è®¤ä½¿ç¨å¦å¤å¼æ ·MEMORYåå¨å¼ææä¾å å表MERGEåå¨å¼æå 许éåå¤çåMyISAM表ä½åç¬è¡¨åMyISAMMEMORYMERGEåå¨å¼æå¤çéäºå¡è¡¨ä¸¤å¼æé½é»è®¤å å«MySQL éï¼MEMORYåå¨å¼æå¼ç¡®å®HEAPå¼æ· InnoDBBDBåå¨å¼ææä¾äºå¡å®å ¨è¡¨BDBå å«æ¯ææä½ç³»ç»åå¸MySQL-Maxäºè¿å¶åçInnoDBé»è®¤å æ¬æMySQL 5.1äºè¿å¶åçæç §åéé ç½®MySQLå 许æç¦æ¢ä»»å¼æ·EXAMPLEåå¨å¼æåæ ¹å¼æåç¨å¼æå建表没æ°æ®åå¨äºå ¶æå ¶æ£ç´¢å¼æç®æå¡MySQLæºä»£ç ä¾æ¼ç¤ºè¯´æä½å§ç¼åæ°åå¨å¼æå主è¦å ´è¶£åè ";ãã[æå ¥æ°æ®-1] (innodb_flush_log_at_trx_commit=1)ããMyISAM 1Wï¼3/sããInnoDB 1Wï¼/sããMyISAM Wï¼/sããInnoDB Wï¼/sããMyISAM Wï¼/sããInnoDB Wï¼æ²¡æ¢æµè¯ãã[æå ¥æ°æ®-2] (innodb_flush_log_at_trx_commit=0)ããMyISAM 1Wï¼3/sããInnoDB 1Wï¼3/sããMyISAM Wï¼/sããInnoDB Wï¼/sããMyISAM Wï¼/sããInnoDB Wï¼/sãã[æå ¥æ°æ®3] (innodb_buffer_pool_size=M)ããInnoDB 1Wï¼3/sããInnoDB Wï¼/sããInnoDB Wï¼/sãã[æå ¥æ°æ®4] (innodb_buffer_pool_size=M, innodb_flush_log_at_trx_commit=1, set autocommit=0)ããInnoDB 1Wï¼3/sããInnoDB Wï¼/sããInnoDB Wï¼/sãã[MySQL é ç½®æ件] (缺çé ç½®)ãã# MySQL Server Instance Configuration Fileãã[client]ããport=ãã[mysql]ããdefault-character-set=gbkãã[mysqld]ããport=ããbasedir="C:/mysql/"ããdatadir="C:/mysql/Data/"ããdefault-character-set=gbkããdefault-storage-engine=INNODBããsql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"ããmax_connections=ããquery_cache_size=0ããtable_cache=ããtmp_table_size=Mããthread_cache_size=8ããmyisam_max_sort_file_size=Gããmyisam_max_extra_sort_file_size=Gããmyisam_sort_buffer_size=Mããkey_buffer_size=Mããread_buffer_size=Kããread_rnd_buffer_size=Kããsort_buffer_size=Kããinnodb_additional_mem_pool_size=4Mããinnodb_flush_log_at_trx_commit=1ããinnodb_log_buffer_size=2Mããinnodb_buffer_pool_size=Mããinnodb_log_file_size=Mããinnodb_thread_concurrency=8ãããæ»ç»ãããçMySQL 5.0é¢MyISAMInnoDBåå¨å¼ææ§è½å·®å«å¹¶éInnoDB说影åæ§è½ä¸»è¦ innodb_flush_log_at_trx_commit é项设置1æ¯æå ¥æ°æ®åé½èªæ交导è´æ§è½æ¥å§éåºè¯¥è·å·æ°å¿å ³ç³»è®¾ç½®0æçè½å¤çææ¾æååSQLæ交SET AUTOCOMMIT = 0设置达æ§è½å¦å¤å¬è¯´é设置innodb_buffer_pool_sizeè½å¤æåInnoDBæ§è½ææµè¯åç°æ²¡ç¹å«ææ¾æåããåºæ¬æèè使ç¨InnoDBæ¿ä»£æMyISAMå¼æInnoDBèªèº«è¯ç¹ç¹æ¯äºå¡æ¯æãåå¨ç¨ãè§å¾ãè¡çº§éå®çç并åæ åµç¸ä¿¡InnoDB表ç°è¯å®è¦æ¯MyISAM强ç¸åºmy.cnfé ç½®æ¯è¾å ³é®è¯é ç½®è½å¤æå éåºç¨ããå¤æWebåºç¨éå ³é®åºç¨ç»§ç»èèMyISAMå ·ä½æ åµèªæé Mysql InnoDBMyISAMåºå«
2024-11-29 10:12890人浏览
2024-11-29 10:091966人浏览
2024-11-29 09:372151人浏览
2024-11-29 09:26199人浏览
2024-11-29 09:00753人浏览
2024-11-29 08:322849人浏览

