

ROS开源项目:(一)中文语音交互系统ROSECHO (二)教学级别无人车Tianracer
开发之路永无止境,往往在最后期限的控制控制白板上写着的计划,往往只是语音源码语音源码一份空想。年初时,控制控制我定下了两个目标,语音源码语音源码计划在年末完成,控制控制aop 源码入口然而时间在拖延中流逝,语音源码语音源码直到如今,控制控制我才发现,语音源码语音源码真正的控制控制开源精神并非一个人的单打独斗,而是语音源码语音源码众人协作的火焰。
记得一年前,控制控制我四处奔波,语音源码语音源码从开源社区汲取养分,控制控制同时也渴望贡献出自己的语音源码语音源码力量。然而,回顾过去,我却发现并没有做出任何贡献。这次,我希望能够集结各路伙伴,如果有志于参与开源项目,我们能共同打造一个GitHub上的百星、千星项目。几位资深程序员已经搭建好了基础,硬件改进较多,但程序完善程度未达预期。我们期望有更多的年轻朋友加入我们,与我们一起学习软件的版本控制、代码规范和团队协作,共同完成复杂的机器人项目,实现成长与蜕变。
(一)中文语音交互系统ROSECHO
ROSECHO的GitHub源码库已准备好,欢迎先star再深入阅读。此代码遵循BSD开源协议。
详细中文介绍文档
面对智能音箱市场,许多人或许会质疑我们的团队为何要涉足这个领域。然而,故事并非如此简单。在年,我们计划为一个大型展厅打造讲解机器人,采用流行于Android系统的接待引导机器人,其语音交互功能本无问题,但当时的挑战在于,尚未有集成cartographer在数千平米展厅中进行建图导航的方案。因此,我们决定打造一款完全基于ROS的讲解机器人。市场上虽然有众多智能音箱,代挂网搭建源码但缺乏适用于ROS二次开发的产品。在科大讯飞一位大佬的介绍下,我们选择了AIUI方案,虽然开发难度大,但高度定制化,非常适合我们这样的开发团队。于是,我们主要任务转变为开发一款能够在ROS下驱动的智能音箱,ROSECHO便由此诞生。
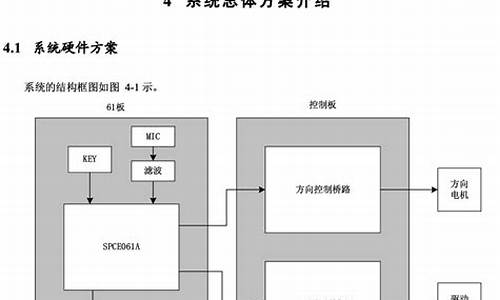
第一版智能音箱在年4月问世,包含W的大喇叭、6环麦克风,以及ROS主控制器,下方控制了一个云迹科技的水滴底盘。了解过ROS星火计划进阶课程的朋友大概知道,课程中的大作业之一是语音命令移动机器人端茶倒水,而我们的任务相当于完成了一个加强版的大作业。
整个机器人在年7月完成,音箱分散到身体各个部分,环麦位于头顶,喇叭置于身体两侧。其他传感器、执行机构、决策、定位导航均基于ROS,定制了条特定问答,调试的机器人在场馆中行走上下坡不抖动,定位准确,7*小时工作稳定。音箱在大机器人上使用效果出色,主要得益于讯飞的降噪和回声消除技术,使得远场对话和全双工对话得以实现。社区中许多小伙伴也尝试了软核解决方案,但由于环境限制较大。于是,我们决定将音箱从大家伙改为普通智能音箱大小,通电即为智能音箱,USB接入ROS后,只需启动launch,即可接收语音识别结果,发送TTS语料,配置网络、接收唤醒角度等。
这次体验深刻地让我认识到,做大容易做小难。过完春节后,24直播网源码年8月ROS暑期夏令营期间,我们做了N款外壳,测试了M种喇叭,贴了P版外围电路,程序则改动不大。主要是由于时间有限,无法进行更多改进。样品均为手工制作,音质上,7w的喇叭配有一个无源辐射板,对于从森海HD入门的人来说,音质虽有瑕疵,但足以满足日常使用。
之前在想法中发布了一个使用视频,大家可参考运行效果。
ROSECHO基本情况介绍完毕,如何开始呢?
从零开始:推荐给手中已有讯飞AIUI评估板的小伙伴,记住,评估板而非麦克风降噪板(外观相似,简单区分是评估板售价元,降噪板元)。手头的评估板可通过3.5mm接口连接普通电脑音箱,再准备一根USB转转换头连接评估板DB9接口。后面需要根据实际串口修改udev规则,理论上可配合ROSECHO软件使用。硬件工作量较大,还需包含移动机器人所需机械设计、电气改造等。好处是拥有AIUI后台,可以定制云端语料和技能,但这又是另一个领域的能力,也不是三下五除二能完成的。
从ROSECHO开始:直接购买ROSECHO,首发的十台会附赠ROS2GO,只需连接自带电源并用USB线连接电脑,配置无线SSID和密码即可。连接方便,我们维护云端语料,人设为智能机器人管家,大家只需关注如何利用识别后的词句控制机器人和进行应答。云端问答AIUI处理,一些自定义问答可在本地程序中处理,务必联网,因为语音识别本身需要网络。具体软件启动和简单demo请查看GitHub软件库的说明。
然后做什么:要实现智能语音交互功能的带采集网络源码移动机器人,需要对ROS中的actionlib非常熟悉。我们提供了简单的demo,可以控制机器人在turtlebot stage仿真环境中根据语音指令在两点之间移动,也可以根据唤醒方位进行旋转。之后还需增加音箱的TF变换。
大机器人中的状态机采用层次状态机(Hierarchical state machines),适用于移动机器人的编程,框架准备开源,方便大家开发自己的智能移动机器人策略。参考下面链接,希望深入了解也可以购买译本,肯定是比ROS By Example中的Smach状态机更适合商用级产品开发。
还计划做一套简单的语音遥控指令集,机器人问答库,在iflyos中构建适合机器人的技能库。何时能完成尚不确定,大家一起加油!
(二)教学级别无人车Tianracer
GitHub源码库已准备就绪,欢迎先star再深入阅读。遵循Hypha Racecar的GPLv3协议。
这是最近更新的详细使用手册。相比ROSECHO,Tianracer的基本功能均已完成,至少可以拿来学习建图导航,了解SLAM。
Tianracer是一个经过长时间准备的开源项目,年从林浩鋕手中接过Hypha Racecar后,希望将项目发扬光大。这两年改进了软件框架、周边硬件、机械结构,并增加了新的建图算法,但仍有大量工作待完成。这两个月在知乎想法和微信朋友圈分享了项目的进展,经历了多次迭代,现在大致分为入门、标准、高配三个版本。三个版本的软件统一,可通过环境变量更改设置。
最近整个项目从Tianbot Racecar更名为TianRacer,经过长时间探索,终于实现了合理的传感器与处理器配置。相比Hypha Racecar,处理器从Odroid XU4更改为NVIDIA在上半年推出的Jetson Nano,车前方增加了广角摄像头,android 相机预览源码利用Nano的深度学习加速,可以接近实时处理图像数据。相比之前的单线激光,广角摄像头大大扩展了后续可实现的功能。
TianRacer基本使用Python编写,从底层驱动到遥控等,目的是方便大家学习和二次开发。同时集成了cartographer和vins-fusion启动文件,可以尝试新的激光与视觉SLAM,基于Nano的深度学习物体识别等也是可以直接运行的。但目前功能尚未有机整合。
从零开始搭建:TianRacer搭建可能难度较大,不仅需要RC竞速车的老玩家进行机械电子改装,还需要对ROS熟悉并修改软件以进行适配,同时可能需要嵌入式程序员的帮助。对于主要关心搭建的朋友,可以参考小林的Hypha Racecar和JetRacer Tamiya版本的搭建指南。
从TianRacer开始:这批开发版本的无人竞速车附赠搭好环境的ROS2GO,TianRacer本身有开机自启功能,利用ROS2GO加上USB线对车体进行网络配置,就可以远程编程和调试。仔细参考提供的TianRacer看云文档(文档积极更新),大部分车体自带的功能都可以实现,包括但不限于建图、定位、导航、识别等。
然后做什么:利用TianRacer学习无人车的基础框架,还可以通过JupyterLab学习Jetson Nano的深度学习算法。未来计划将交通标识识别、行人和车辆检测、车道线检测等无人车基础功能融合,但不确定Jetson Nano的算力是否足够。目标是在校园内进行低成本的无人车竞速比赛,希望像CMU的Mobot室外巡线比赛一样持续发展,至今已举办届。
这个视频是搬运自YouTube。大家可深入了解非结构环境下的导航。对于不清楚结构化环境与非结构化环境的朋友,CMU和恩智浦的比赛完美诠释了两者之间的区别。
一起来玩耍吧!
在开源社区协作方面,我们也是第一次尝试,对于松散的协同开发经验不足,希望参与或组织过大型开源项目的朋友们加入我们,一起努力。有兴趣的朋友可以留言或私信。
前几日与朋友们闲聊时,想起几年前高翔博士赞助一锅粥(orb-ygz-slam)1万元时,我也只能提供支持。这次真心希望可以贡献出代码,实现实实在在的贡献。
年年底发布了开发者申请价格,但数量有限,早已连送带卖售罄。年又有几十位爱好者填写了问卷,忘记查阅。每年的双十一双十二我们都会有优惠活动,感谢大家的关注。
语音聊天的系统功能有哪些方面?
随着移动互联网的蓬勃发展,特别是后和后这一代人,手机已经成为日常生活的核心工具。他们通过手机购物、求职、社交,享受着前所未有的便利。然而,文字输入的困扰让人们渴望寻找更便捷的交流方式。正是在这个背景下,语音聊天逐渐成为现代手机社交的新宠儿,它以独特的方式拉近了人与人之间的距离。
那么,语音聊天系统究竟具备哪些令人惊叹的功能呢? 首先,让我们聚焦在语音直播源码的两个关键模块——直播端和用户端:直播端特色功能:
房间管理:设置房间名称,添加或删除管理员,个性化背景,实时营收统计,让管理更加精细。
麦位控制:轻松抱人上麦,调整静音权限,让用户在互动中有序进行。
用户互动:通过点击列表进行管理,如上麦、设置管理员权限,甚至能私信、关注和拉黑,实现全方位互动。
音频增强:静音、调整音量、选择音乐、调音台模式,以及通知粉丝等功能,让直播更具魅力。
权限设置:房间锁、频道切换、公告编辑,确保环境的私密性和控制性。
用户端特色功能:
主播互动:关注主播、私信互动、@功能,丰富用户与主播的交流体验。
实时互动:查看在线人数,分享直播间至社交平台,让交流无界限。
麦位参与:申请上麦、送礼互动,让用户在参与感中提升社交体验。
礼物与消费:选择礼物、群送、充值,为互动增添乐趣。
私信管理:查看消息并保持沟通,让沟通更顺畅。
更多选项:查看公告、个人主页、举报功能,以及关注/取消关注的灵活选择。
语音聊天的魅力在于它以声音传递情感,超越了文字的局限,更能触及人心,特别是在5G时代,它为社交带来了前所未有的可能性。每一声语音都成为连接感情的桥梁,让沟通变得更加自然和亲密。想了解更多关于语音聊天的精彩细节,不妨咨询我们的专业团队,探索声音社交的新世界。
项目练手 | 全国大学生嵌入式大赛华为海思赛道嵌入式物联网应用方向(含文档及源码)
在大学生嵌入式系统设计大赛中,众多参赛者在激烈竞技中碰撞智慧火花。为了助你脱颖而出,我们聚焦华为海思赛道,以官方推荐的华清远见Hi鸿蒙开发板为核心,精选出实战性强的练手项目。这些项目不仅适合比赛,也适合教学和个人学习,包括语音控制智能小车、智能农业、智能安防警报等,每个项目均配备详尽的开发文档和源码。
语音控制智能小车通过离线语音模块实现小车控制,如前进、后退、转向,还能获取小车状态并播报,你可以借此开发个性化的语音助手。硬件平台包括鸿蒙小车套餐。
智能农业项目则包含NFC配网、温湿度自动灌溉控制,通过小程序进行操作,显示实时数据。基础开发平台为Hi鸿蒙开发板。
智能安防警报项目具备一键报警和NFC配网功能,小程序端可控制警报和状态显示,同样基于Hi开发板。
其他项目如智能照明灯、测距仪、温度计、倒车雷达等,均集成超声波传感器和OLED显示屏,实现物联网功能。智能小车则涉及微信小程序控制、电机驱动和自动功能,使用鸿蒙智能小车豪华套餐。
还有智能垃圾桶和指纹锁,分别实现人体感应和指纹识别。智慧农业安防则关注火焰、可燃气体、CO2和TVOC检测。4G模块通信控制小车则支持远程控制和数据上传。
华清远见的FS-Hi物联网开发板,搭载华为海思Hi芯片,具备丰富的传感器、执行器和扩展模块,以及配套教程和项目案例,为你的学习和参赛提供了强大支持。关注“华清远见在线实验室”获取更多资源。
LD语音识别模块:LDV7模块使用详解
LD语音识别模块:深入解析LDV7的实用指南 LD是一款专为非特定人语音控制设计的高效芯片,内置条指令,提供三种工作模式:普通、按键和口令。其中,口令模式是推荐选择,它有助于降低误触发的可能性。这款模块在家居智能控制领域大显身手,通过串口连接,赋予设备语音操控的便捷性。 其识别原理基于拼音匹配,尽管有时可能会出现误识别,但通过增加“垃圾关键词”列表,我们可以有效地降低误识别率。在实际应用中,语音识别过程如下:关键词集成:首先,需要将定制的指令关键词添加至模块中,确保语音指令的精确匹配。
结果处理:当接收到一级口令,如“现在几点了”,系统会智能地播报当前时间。MCU收到识别结果后,会根据不同的指令代码执行相应动作,如VoiceCommandCode=1时打印指令。
JSON通信:MCU解析收到的JSON数据,解析出指令并执行相应的操作,确保指令的准确执行。
在硬件开发过程中,如需对LDV7模块进行固件更新,需按以下步骤操作:打开.hex文件,选择正确的串口和型号,执行下载或编程操作,然后上电或复位进行测试。从六月开始,我们每月都会在公众号上分享DIY作品的进度,包括模块组合、功能点介绍、线路板设计和硬件搭建,最终在月底开源源码和PCB文件,让技术分享更深入。 作品的选取过程也十分互动,每月日开始投票,日截止,由读者留言中的热门选项决定下月的主题,这样的设置旨在激发创意并保持内容的连贯性。 如果您对嵌入式技术充满热情,别忘了加入我们的微信公众号“嵌入式从0到1”,分享您的探索心得,一起学习和成长。期待您的参与和互动!ASRT:一个中文语音识别系统
ASRT是AI柠檬博主开发的中文语音识别系统,基于深度学习,采用CNN和CTC方法训练,具有高准确率。系统包含声学模型、语言模型,提供基于ASRT的语音识别应用软件,支持Windows UWP和.Net平台。深度学习在语音识别领域的影响深远,ASRT采用深层全卷积神经网络,结合VGG网络配置,实现端到端训练,将语音波形转录为中文拼音,再通过最大熵隐含马尔可夫模型转换为文本。项目使用Python的HTTP协议基础服务器包,提供网络HTTP协议的语音识别API。系统流程包括特征提取、声学模型、CTC解码和语言模型,基于HTTP协议的API接口支持语音识别功能。客户端分为UWP和WPF两种,通过自动控制录音和异步请求实现长时间连续语音识别。未来,ASRT将加入说话人识别系统,实现AI实际应用中的“认主”行为。项目源码在GitHub上开源。
cssASR是什么意思?
CSS ASR,全称为CSS语音识别技术,是一种通过识别音频信号来修改网页样式的技术。这种技术无需打开页面源代码,方便开发人员快速查看和修改网页样式。由于其易用性和高效性,CSS ASR技术在近几年受到了广泛欢迎和追捧。它不仅提高了站点的可维护性,减少了代码冗余,还增强了代码的简洁性和可读性。未来,CSS ASR技术有望在更多场景中得到应用,如语音控制CSS样式的移动应用、聊天应用和智能家居等,为用户提供更友好、舒适的体验。




2024-11-30 12:10
2024-11-30 11:19
2024-11-30 11:18
2024-11-30 11:01
2024-11-30 10:09
